
TL;DR
- Engineering platforms work best when they reduce cognitive load. Research from the State of Platform Engineering, Vol. 2 shows widespread belief in platform engineering’s value, yet Reddit discussions warn that platforms fail when they add bureaucracy instead of clarity. A successful platform removes complexity from daily development, not the other way around.
- Internal platforms fix delivery drift by giving teams predictable workflows. As organizations grow, pipelines splinter and every team invents its own deployment path. A well-structured IDP brings consistent templates, shared automation, and cross-team visibility so developers no longer need to reverse-engineer how work moves to production.
- Product-led platform strategies consistently outperform infrastructure-led ones. High-performing teams model their platforms after real developer behavior, not internal assumptions. Examples like Backstage and Cycloid show how centering developer experience turns platforms into tools engineers actually enjoy using rather than mandatory gatekeeping layers.
- Self-service unlocks delivery speed where tickets once created bottlenecks. Organizations trapped in request queues face slow lead times and heavy operational load. Shifting to curated, governed self-service removes waiting periods while maintaining control through guardrails instead of manual approvals. According to Gartner, 58 % of organisations regard developer experience as a key factor in productivity and quality, those with a strong developer experience are 31 % more likely to improve delivery flow.
- Golden paths prevent the chaos of “every team builds its own thing.” Without recommended routes, deployment patterns multiply until support and onboarding become painful. Golden paths use documented templates, automation, and sane defaults to bring order while keeping room for team-level variation.
- Policy as code stabilizes governance by removing human inconsistency. Manual reviews slow teams and produce uneven decisions. Versioned, machine-applied rules deliver immediate feedback and uniform enforcement across services, a shift that dramatically improves trust and repeatability.
- Developer experience determines platform adoption more than any technical feature. Even with automation and governance in place, a fragmented toolchain forces engineers to jump between dashboards. Unified portals like Cycloid’s project views cut down on context switching and make the platform feel like a natural part of daily work.
Introduction
The State of Platform Engineering, Vol. 2 research shows that an overwhelming majority of respondents view platform engineering as beneficial to delivering software, with earlier reporting indicating over ninety percent agreement that platform efforts help realize DevOps benefits. This statistical baseline explains why many organizations are investing in internal platforms rather than relying on necessary toolchains.
At the same time, community conversations on Reddit make one practical point clear: platform initiatives can succeed only if they reduce developers’ cognitive load rather than add another layer of bureaucracy, threads such as “Platform Engineering Fad?” and related discussions repeatedly surface complaints about platforms that centralize control without usable self-service.

This article compares five platform strategies that platform teams use in practice, framed as pairs of contrasts, and illustrates how a modular IDP approach can pursue a product mindset while preserving autonomy for engineering teams. The aim is practical: for each strategy we offer short, implementable guidance, example snippets where relevant, and notes on how Cycloid’s control plane maps to the pattern so you can translate strategy into daily workflows.
When Engineering Workflows Become Difficult to Coordinate
Engineering groups reach a point where services increase, pipelines expand, and teams adopt different tools to solve similar problems. For example, one team might deploy with GitHub Actions while another uses Jenkins, even though both ship similar microservices. This creates uneven practices across the organization. New developers struggle to understand how code moves through builds, tests and deployments, while senior engineers get pulled into repeated tasks such as fixing broken YAML files, clarifying pipeline steps or approving environment requests instead of improving reliability or scaling the platform. Delivery slows because every team follows a different path, even when the outcome is identical.
An internal platform brings clarity by replacing scattered scripts, one-off deployment methods and team-specific infrastructure choices with a single set of templates, workflows and environments that everyone understands. Instead of scattered workflows such as custom bash scripts, hand-written deployment steps or ad-hoc Terraform folders, the platform offers a shared space where developers work with consistent templates, predictable deployment steps and patterns that reduce uncertainty.
The platform is not trying to restrict how services are written. It removes unnecessary variation such as each team defining its own CI pipeline format, inventing different directory structures or choosing conflicting deployment methods, which makes everyday engineering work easier to understand and maintain. Cycloid is one example of a platform that brings these elements together in a single control plane, giving teams templates, governance, and project visibility in one location.
Problems an Internal Platform Helps Reduce
Teams usually start exploring platform engineering after running into repeated delivery issues such as slow environment provisioning, inconsistent CI pipelines, unreliable deployment steps and frequent handoffs that delay releases. These problems appear in many organizations regardless of size, tech stack, or cloud provider:
- Long waits for environments or changes to deployment workflows.
- Heavy dependence on a few senior developers who hold crucial operational knowledge.
- Drift across infrastructure choices that creates reliability and support issues.
- Too many disconnected dashboards that hide operational, cost and compliance signals, such as checking deployments in GitLab, costs in AWS Billing, logs in Kibana and policy violations in a separate security tool, which forces developers to jump between four or five systems to understand a single service.
- Little visibility into how developers move through the delivery process.
A clear platform strategy helps address these issues by replacing ad-hoc steps with reliable workflows such as a standard CI pipeline that always runs tests, builds images and pushes artifacts the same way for every service. It adds shared automation like a single provisioning process that creates environments with the same networking, logging and security settings, instead of each team scripting it differently. These guardrails remove uncertainty because developers no longer have to guess how their service should be built, deployed or scaled. Cycloid’s platform engineering and cost views represent one approach to consolidating these signals in a single place, which many teams find missing in their current setups.
Before selecting tools or building templates, platform teams make a foundational choice about how the platform will take shape. This decision influences adoption, developer trust, and the long term direction of the platform itself, which leads into the first strategy.
Strategy 1: Infra Led Platform Strategy vs Product Led Platform Strategy
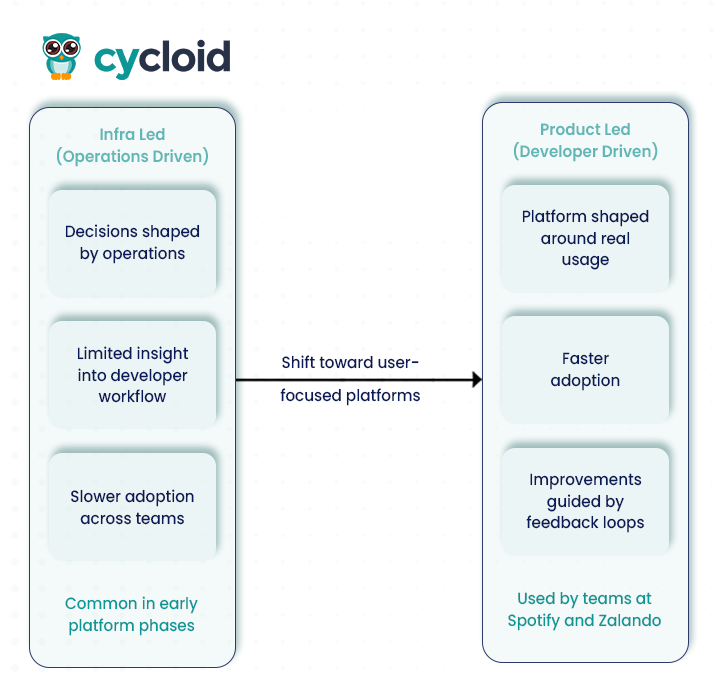
Every platform team eventually must choose whether the platform’s direction will be driven by operational priorities or by developer needs. Infra led platforms begin with standardizing tools, pipelines, and infrastructure governance. This path creates structure, but it often results in a platform that mirrors how operations teams prefer to work rather than how developers actually build and ship software.
A product led strategy follows a different route. In this model, the platform is treated as a service with clearly defined users (developers), measurable adoption metrics, and continuous refinement based on real usage. Platform teams observe how developers move through delivery, identify recurring friction points, and adjust the platform based on those findings. For example, Spotify built its internal system Backstage to improve developer workflows, reduce onboarding time, and give developers a unified interface to find services and tools. In another case, Zalando created its platform Sunrise on top of Backstage to integrate infrastructure, cost, pipelines, and service ownership into a single view for builders.
Cycloid supports this mindset by allowing platform teams to see how developers use templates, workflows, and environments, which means changes are grounded in user behaviour instead of assumptions made inside the platform group. Once the platform begins to reflect actual developer workflows, the next natural question is how developers should interact with it in their daily work, which leads directly into the second strategy.
Strategy 2: Self-Service Enablement vs Ticket-Based Operations
Many organisations begin their internal-platform journey with a ticket-based model. In this scenario developers submit requests for environment provisioning, pipeline changes or infrastructure updates. The operations or platform team handles each ticket manually. This method delivers control and visibility but creates delays and dependency chains. Consider large enterprises where every new service must go through a ticketing workflow, approvals, and manual operations steps; each request can take days or longer, reducing delivery velocity and adding cognitive load on both developers and operations.
For example, one large global software company reportedly spent nearly half of its infrastructure team’s time handling provisioning requests, leading to slower feature delivery and developer frustration (indirect reference via general industry analysis). The ticket-based workflow became a bottleneck rather than a control point.
In contrast, a self-service enablement model flips the interaction flow. Developers access a curated set of templates, automation, and flows via a portal or catalogue. They select a template, fill in inputs, trigger provisioning or deployment and go direct. This removes intermediary steps and lets teams move faster without sacrificing governance. Microsoft’s documentation on platform engineering describes this as the transition from tickets to tools: “enable self-service with guardrails through controlled, governed task execution and provisioning, along with centralized visibility”.
When a platform team chooses self-service enablement rather than maintaining a ticket-queue, the next strategic consideration becomes how to manage consistency across those workflows, which leads directly into our next strategy around golden paths.
Strategy 3: Golden Paths vs You Build It, You Run It Chaos
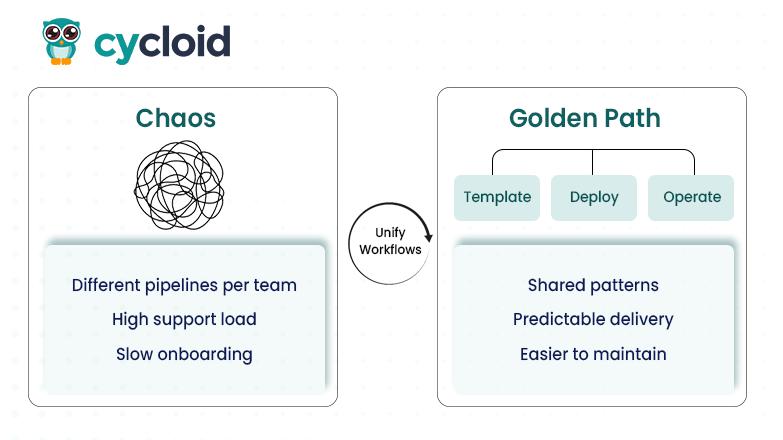
When teams adopt self-service workflows, the next challenge often arises: developers start creating unique deployment patterns, pipelines, and infrastructure configurations. At first this seems flexible, but over time these variations accumulate. Support and onboarding begin to suffer, incident response slows down, and maintaining shared standards across teams becomes difficult.
Golden paths address this problem. A golden path is a recommended route that combines templates, documentation, safe defaults and automation. It gives developers a predictable and efficient starting point while preserving some degree of flexibility for service-specific needs. For example, Netflix built a “common front door” for developers and used golden paths to standardize on-boarding and deployment workflows across a large number of services. Similarly, the Google blog describes golden paths as a “templated composition of well-integrated code and capabilities for rapid project development” that reduce cognitive load for developers.
Without clear golden paths, a “You Build It, You Run It” culture may initially increase ownership but gradually leads to scattered practices. When each team follows its own way, the organization loses the ability to maintain consistent incident response, onboard new engineers efficiently, and enforce standards effectively. Golden paths bring shared direction into the platform without sacrificing team autonomy.
Cycloid supports this strategy by offering reusable stacks and shared workflows that help platform engineers guide teams through consistent patterns. Developers start from known templates and platform engineers maintain the underlying logic. This lowers variation and keeps day-to-day work manageable.
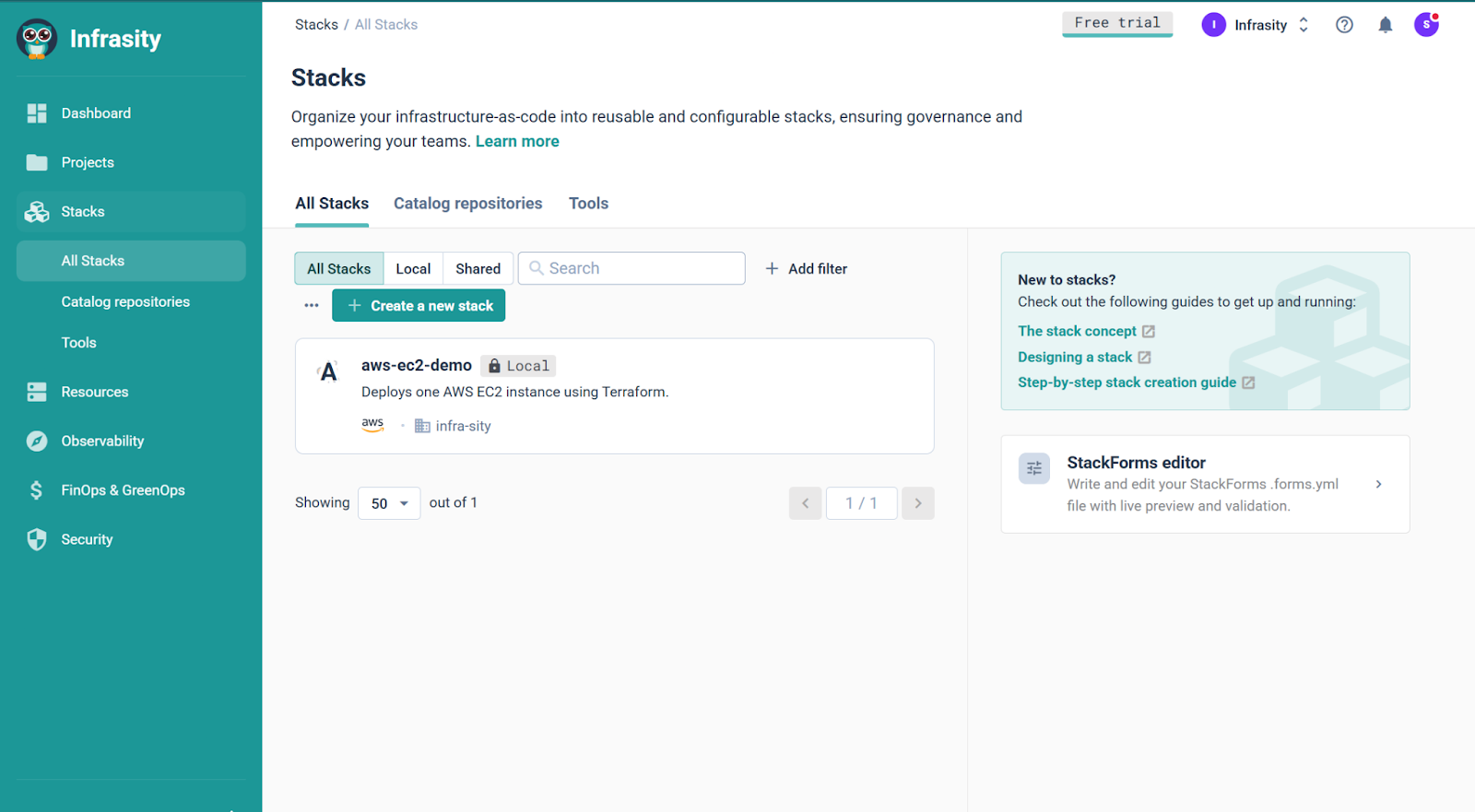
The Stacks view gives teams one place to define infrastructure, validate inputs and expose safe templates to developers.
Instead of storing keys and credentials across multiple team folders or cloud consoles, a central view gives developers a predictable and auditable location to manage access.
This screenshot clearly visualises credential management consolidation provided by cycloid.
As delivery practices start becoming more consistent through golden paths, the logical next step becomes enforcing those workflows safely and reliably, this leads into the next strategy around governance.
Strategy 4: Policy as Code Governance vs Manual Review Bottlenecks
As golden paths bring structure to delivery workflows, the next challenge is ensuring that these workflows remain safe and compliant across all teams. Many organisations begin with manual reviews for infrastructure and deployment changes. This creates inconsistency because reviewers interpret rules differently, and it adds delays because each request must be processed individually. Over time, this slows down teams and places a heavy load on senior engineers who become responsible for repetitive checks.
Policy as code improves this situation by defining safety rules in a machine-readable format stored in source control. These rules are applied automatically during provisioning, deployment or environment creation. Developers receive immediate feedback when something fails a rule, and the checks remain consistent across environments. For example, Capital One published its experience adopting policy as code using Open Policy Agent to unify compliance and security checks in a predictable way.
A simple policy for enforcing cost-center tagging in infrastructure looks like this:
| deny[msg] { input.resource_type == “aws_instance” not input.tags[“cost-center”] msg := “All compute instances must include a cost-center tag” } |
This rule communicates the requirement directly. Developers understand what is missing and can fix the issue without waiting for a reviewer. This reduces human dependency and creates transparency across all teams.
Cycloid incorporates policy as code into its governance engine, allowing teams to define rules once and apply them across projects through versioned policies. This creates predictable guardrails and supports the structure established by golden paths.
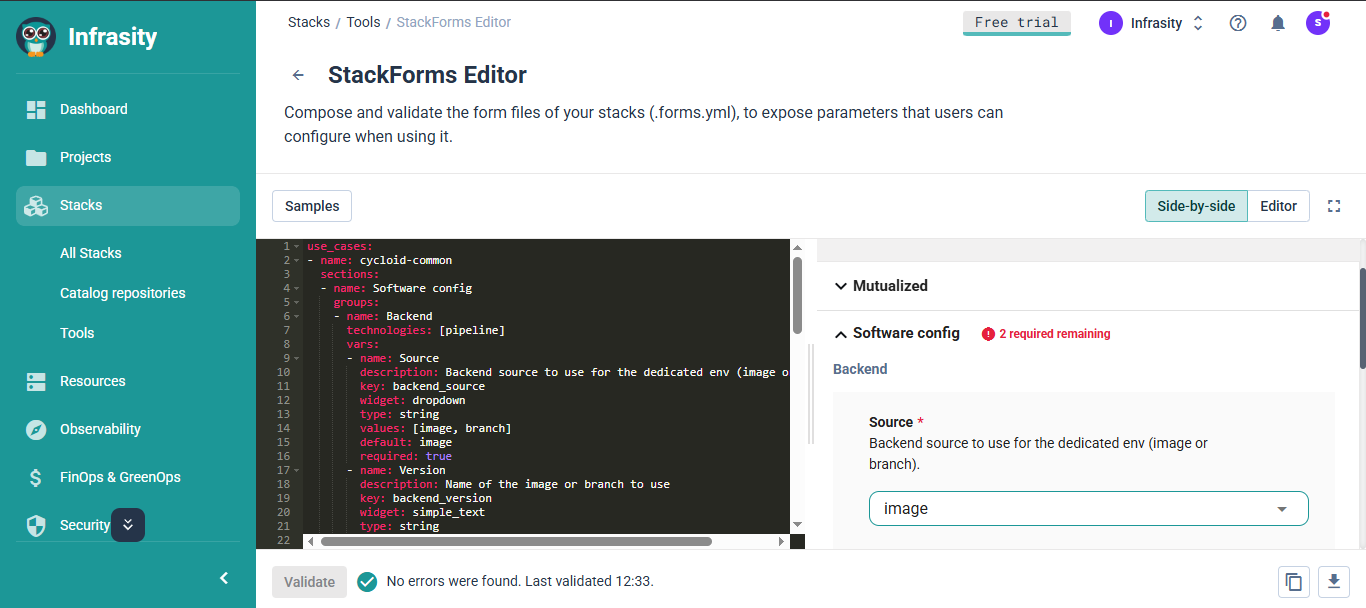
Cycloid supports golden paths and governance by giving platform teams a structured way to define the exact parameters developers can use when provisioning through a stack. In the StackForms Editor shown above, the .forms.yml file defines fields like backend_source and backend_version, sets allowed values and adds required checks. Cycloid validates these definitions in real time and generates a matching form on the right side, so developers only interact with approved, validated inputs. This keeps workflows consistent and prevents teams from introducing their own variations, while still giving developers a straightforward and predictable interface.
With governance handled through reliable automation, the next step focuses on the experience developers have when navigating the platform. This leads into the fifth strategy.
Strategy 5: Developer Experience First vs Platform as a Toolchain
As governance becomes more reliable through policy as code, the next focus is the experience developers have when working with the platform each day. Strong automation is useful, but the workflow still breaks down when developers need separate tools to check deployments, view logs, review configuration, track environments or confirm ownership details. Moving across these disconnected interfaces interrupts the delivery flow and adds extra cognitive load because each tool presents information differently.
Developer experience first addresses this fragmentation directly by reducing the number of tools developers must jump between and giving them one place to view deployments, configuration, environment details and workflows. A well-known example comes from Spotify’s Backstage, which became an open platform for integrating documentation, service ownership, templates and operational data into a single view for developers. This approach reduced context switching and improved onboarding speed.
Another example comes from Airbnb Podcasts (Willie Yao, former Head of Developer Infrastructure at Airbnb), which described how unifying developer tooling into a single internal portal reduced friction and simplified workflows by giving teams one consistent entry point to deploy, observe, and manage services.
Developers lose time when they must switch between several tools to understand what is running, what has failed and where deployments stand.
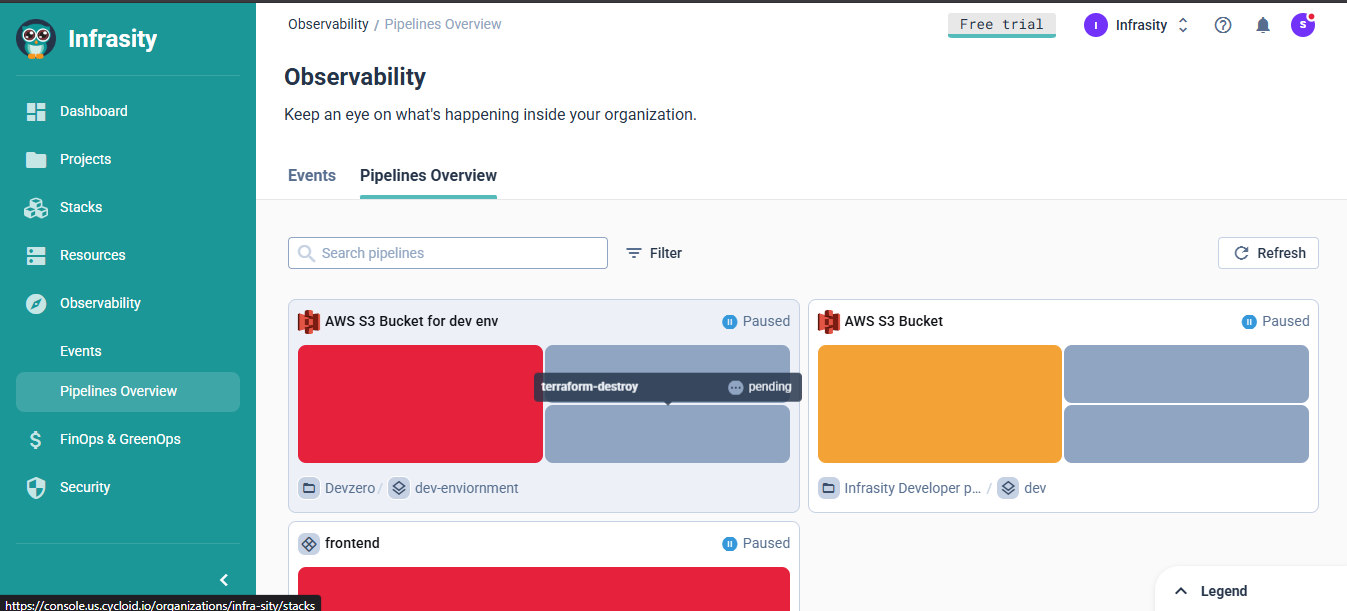
This screenshot represents pipeline sprawl replaced by unified observability.
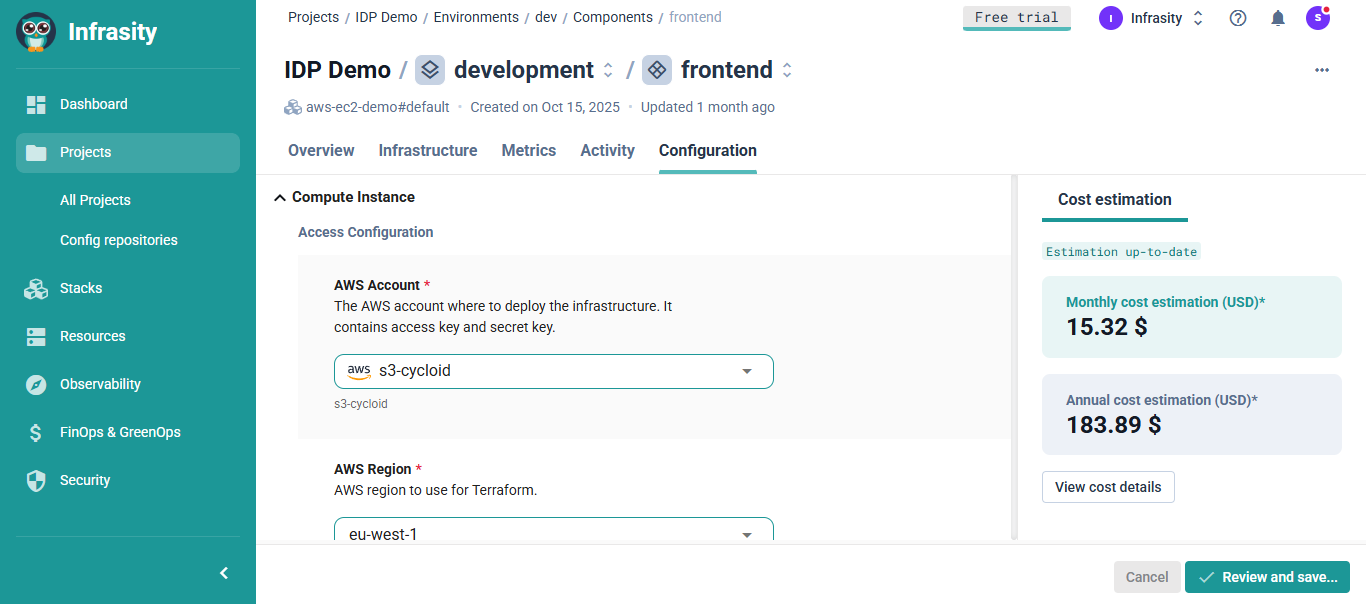
Cycloid supports a unified experience through project views that bring deployments, workflow history, cost information and governance signals together in one interface. This reduces uncertainty and gives developers a predictable environment for building and operating services.
Optional DX enhancement
The platform can also include optional views, such as cost and carbon insights, without forcing developers to leave the main interface.

Closing Takeaways
If your organisation is evaluating platform engineering practices or refining an existing internal platform, these strategies offer a practical starting point. They help teams reduce friction, stabilise delivery workflows and create a developer experience that scales. Cycloid provides one example of how these ideas can be put into practice in a unified environment. Exploring the product can give your team a clearer view of how self service, governance and shared workflows operate together in real use.
| Strategy Type | Traditional Approach | Modern Approach | How Cycloid Supports It |
| Platform Focus | The platform grows from operational priorities like enforcing a single CI tool, standardising Terraform modules, controlling cloud account structure or setting strict deployment rules. Decisions reflect infrastructure needs rather than developer workflows. | The platform evolves from developer behaviour and feedback. Improvements focus on reducing friction in daily tasks. | The platform structure highlights real usage patterns, which guides platform teams toward areas that matter most for developers. |
| Delivery Model | Developers rely on request queues for routine actions. Lead times vary because tasks depend on manual intervention. | Teams perform common tasks through predefined self service actions, which removes waiting periods and keeps work predictable. | Stack templates give developers clear inputs and repeatable actions, which shortens delivery cycles and keeps standards intact. |
| Developer Workflow | Each team creates its own deployment and infrastructure patterns. Variation grows over time and becomes difficult to support. | Recommended routes provide consistent starting points across services, which reduces drift while leaving room for service specific needs. | Shared workflows and templates serve as stable foundations, lowering the amount of custom logic that each team must maintain. |
| Governance | Manual checks like where engineers review infrastructure or deployment changes, such as approving Terraform plans in tickets, verifying whether required tags are present create repeated review cycles and inconsistent decisions. Safety controls depend on individual reviewers. | Rules live in code, stored in version control, and applied automatically. Developers receive instant clarity about requirements. | Versioned rules apply across environments, giving teams predictable control without slowing development. |
| Experience | Developers switch between several tools to understand deployments, costs, environment state, and compliance signals. | Information stays in one place. Developers track progress, understand changes, and make decisions without searching across systems. | Project views combine workflow history, deployment status, cost data, and governance signals in a single interface. |
This comparison highlights the path that most successful platform teams follow. The shift is gradual but meaningful. Each stage reduces uncertainty, strengthens developer confidence, and gives platform engineers clearer insight into where improvements will have the greatest impact.
FAQs
1. How can a team decide which platform strategy fits their engineering organization?
The best way to choose a strategy is to start with the problems developers face in their day to day work. Some teams struggle with long wait times, while others deal with fragmented tooling or inconsistent deployment patterns. Identifying the points where work slows down gives platform engineers a clear starting point. A product led approach tends to work well in most organizations because it focuses on actual usage instead of theoretical improvements.
2. Do all organizations need a dedicated platform team to build an internal developer platform?
A dedicated group becomes helpful once multiple teams rely on shared workflows. Without a focused team, standards drift and improvements stall. The size of this team varies, but the function remains the same: maintain templates, refine workflows, manage governance rules, and track adoption. Many organizations start small and grow the team only when usage increases.
3. Who are the primary users of a platform inside an engineering organization?
Developers are the main users because they interact with the platform during planning, building, deploying, and operating their services. Platform engineers, security teams, and leadership groups also rely on the platform for visibility, governance, and auditing. Each group uses the platform in a different way, but the daily experience of developers shapes most platform decisions.
4. What is an Internal Developer Platform?
An Internal Developer Platform, often called an IDP, is a system that organizes infrastructure, deployment workflows, automation, and governance into a consistent environment. It gives developers a reliable set of tools and templates, while giving platform engineers a central place to manage standards and policies. Cycloid is one example of an IDP that follows this pattern by combining projects, stacks, cost insights, and governance controls.
5. What is the role of a platform team in supporting developers?
A platform team designs, builds, and maintains the shared systems that developers rely on. This team identifies friction points, maintains golden paths, manages policy rules, and improves workflows based on real usage. The goal is not to control development work, but to reduce overhead across engineering groups and give developers a predictable path from code to production.


