TL;DR
- Governance fails when Day 0 is treated as a kick-off instead of a code-generating event. Hardcoding RBAC, network topology, and .forms.yml constraints early ensures every downstream environment inherits a secure DNA that cannot be bypassed.
- Review queues scale linearly with headcount and eventually break under the weight of repetitive tickets. By encoding policy directly into StackForms, you shift from “checking work” to “defining boundaries,” allowing engineers to move at full speed without needing a human to click ‘approve’.
- Most teams over-engineer the initial deployment but under-solve for the years of entropy that follow. A platform is only as strong as its ability to govern post-provisioning actions like scaling, patching, and secret rotation through the same GitOps-backed paths used at launch.
- Manual console “hotfixes” create a delta between your Git repo and reality, leading to cascading failures during the next automation run. Continuous drift detection is non-negotiable; it turns the version-controlled stack into a living ground truth rather than a stale template.
- Monthly spending dashboards are post-mortems for wasted capital that is already gone. Real governance requires operational FinOps, where cost boundaries and carbon footprint estimates are surfaced inside the provisioning form to block over-provisioning before the resource ever exists.
- Governance shouldn’t require a clean slate or a total rewrite of legacy infrastructure. Tools like InfraImport allow you to reverse-engineer existing cloud resources into versioned Stacks, bringing unmanaged “wild” infrastructure back under the platform’s control and visibility.
What Day 0, Day 1, and Day 2 Operations Actually Mean for Platform Teams
Platform teams are good at solving Day 1. CI/CD pipelines get built, Terraform modules get written, and provisioning gets automated. The uncomfortable truth is that Day 1 is the easy part, it’s time-bounded. Day 2 is not, and the governance investment almost never matches the operational duration.
Gartner forecasts that by 2026, 80% of large software engineering organizations will have established platform teams as internal providers of reusable services and tools, up from 45% in 2022. The pressure to stand up those platforms quickly creates a pattern where Day 2 governance gets deferred until the pain of not having it becomes loud enough to justify the investment. By then, there’s already drift to clean up, cost overruns to explain, and compliance gaps to document. According to Spacelift’s survey of 413 infrastructure decision-makers, 45% of organizations claim they’ve achieved high levels of automation, yet only 14% demonstrate the practices of genuine infrastructure automation excellence. The gap lives almost entirely in Day 2.
The Day 0/1/2 model only works if governance is continuous across all three phases, not enforced at provisioning and then quietly abandoned. This article covers what each phase actually owns, where governance breaks down between phases, and what a platform built to span the full lifecycle looks like in practice, from the .forms.yml definitions that encode Day 0 policy to the drift detection and cost governance mechanisms that make Day 2 manageable at scale.
What Belongs to Day 0 vs Day 1 vs Day 2
Day 0 is not a planning meeting; it produces engineering artifacts: RBAC boundaries, IaC templates, compliance policies, identity strategy, network topology decisions, and catalog repository structures. Everything downstream inherits these constraints, which makes getting them wrong expensive. Retroactively changing VPC segmentation in a production environment or restructuring a catalog hierarchy after dozens of stacks have been imported are the kinds of fixes that take weeks and generate incidents along the way.
Day 1 is the initial deployment window. Infrastructure gets provisioned, services get deployed, and CI/CD pipelines get wired. Day 0 constraints should arrive here intact, encoded into the templates and forms that engineers actually interact with during provisioning.
Day 2 begins the moment the first post-deployment change is applied and runs until the environment is decommissioned. It covers monitoring, patching, secret rotation, scaling events, Helm chart updates, cost management, and the cleanup work of tearing environments down properly. Calling it a “phase” is generous, it’s the default state of any production system and the one phase with no defined end date. A team that invests heavily in Day 0 and Day 1 and then treats Day 2 as somebody else’s problem will spend most of its operational time in a state it never designed for.
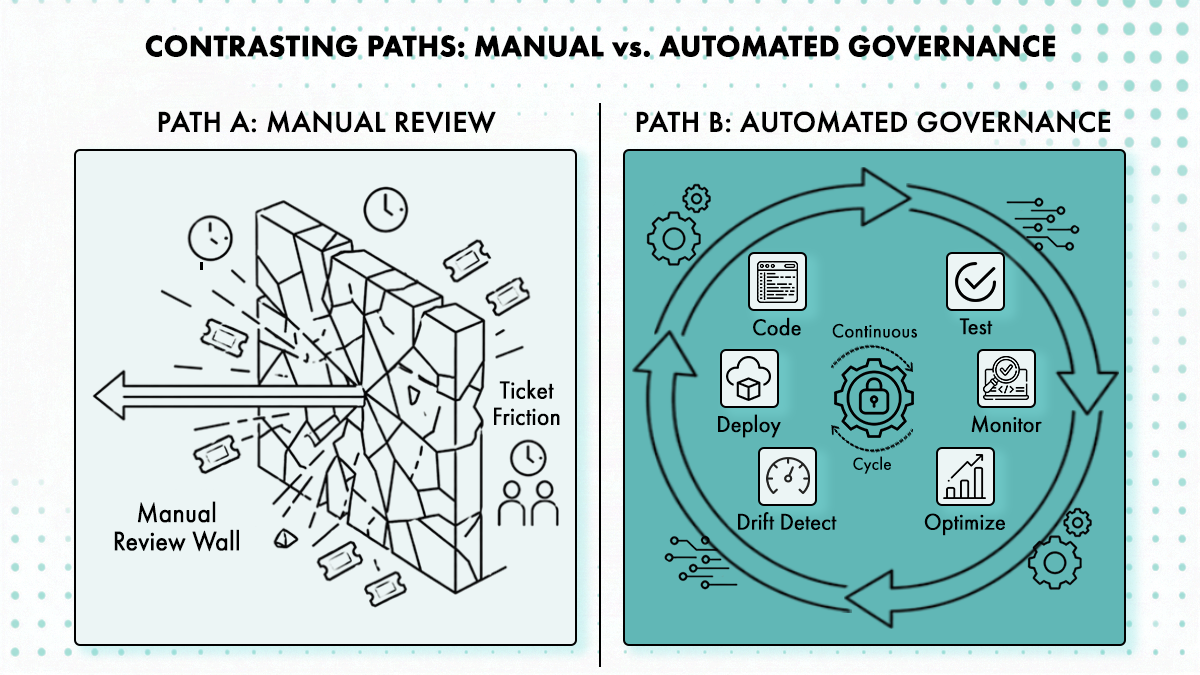
Why Manual Review Queues Break Down at 100+ Engineers
The failure pattern is consistent: platform teams enforce standards at creation time through approved Terraform modules and pipeline gates, then let Day 2 operations fall back into tickets. Scaling an environment, rotating a secret, updating a Helm chart, or decommissioning a service bypasses the same guardrails that governed the original provisioning.
As Cycloid’s platform engineering research documents, governance that depends on human review scales linearly with usage. At 100+ engineers, review queues become the bottleneck, not missing tooling. A data team provisioning a new warehouse triggers a platform engineer review for Terraform network placement, a security review for data access paths, and a finance check for warehouse size, all sequentially, all for a request that’s structurally identical to the last twenty. Adding more reviewers to the loop doesn’t fix the structural problem; it just delays when the queue breaks.
How Configuration Drift Enters Production Environments
The failure modes are specific and compounding. Configuration drift enters through manual console changes made to unblock incidents, changes that never make it back into version control. Cost exposure builds from over-provisioned resources that were sized correctly at Day 1 but were never re-evaluated as usage patterns changed. Compliance gaps emerge from policies enforced at creation but not at update or decommissioning. An environment that passed its initial security review can accumulate months of ungoverned changes before the next audit surfaces the problem.
The operational floor collapses when manual runbooks are the primary Day 2 response mechanism. Nobody wants to grep through a Notion page at 2 AM trying to find the restart procedure for a service they didn’t write.
Day 0 Operations: RBAC, Network Topology, and IaC Decisions Made Before Provisioning
Day 0 is where the governance model either holds together or quietly falls apart. The decisions made here don’t just affect the first deployment, they constrain every environment, every update, and every decommissioning event that follows for the life of the platform.
Treating Day 0 outputs as durable engineering artifacts rather than draft documents to be revised later is what separates a platform that ages well from one that accumulates structural debt on a fixed schedule.
Day 0 Decisions That Are Hard to Change Later
Network topology and VPC segmentation decisions made during Day 0 are expensive to change post-deployment. Retroactively isolating a data tier that was provisioned on the same subnet as application workloads isn’t a configuration change, it’s a re-architecture with downtime implications. Identity strategy and RBAC model design carry the same weight. An RBAC model built around broad service accounts can’t be easily tightened after dozens of workloads have been deployed against it. IaC toolchain choice carries lock-in implications that shape what Day 2 automation looks like for years; mid-lifecycle toolchain changes mean rewriting the state management model for every existing environment.
Cycloid treats Git as the authoritative state store from Day 0, where catalog repositories, Stack definitions, and configuration files are version-controlled before any environment exists. Catalog repositories, stack definitions, and .cycloid.yml configurations are version-controlled before any environment exists. Decisions made outside Git during Day 0 create undocumented state that Day 2 cannot reconcile, drift detection requires a canonical record of the intended state to compare against the actual deployed state. Without it, the platform has no baseline.
How forms.yml Enforces Compliance at Provisioning Time
In Cycloid, a Stack’s .forms.yml file defines what inputs are exposed to the deploying engineer, what values are bounded to an approved range, and what options are locked entirely. The compliance decisions made during Day 0 determine what Day 1 and Day 2 operators can do, not through policy documents, but through what the interface literally permits.
StackForms reads the .forms.yml configuration and presents only bounded, approved inputs. An engineer provisioning a data warehouse doesn’t choose the instance class from an open text field, they choose from a small, pre-approved set. External network attachment isn’t a choice that can be made because the option isn’t exposed. Only the elements defined in .forms.yml are replaceable in the generated configuration; everything else remains fixed by the stack definition. Under the hood, Terraform still runs. The shape of what Terraform can produce is just constrained before execution.
The tradeoff is worth naming plainly: over-constraining stack inputs during Day 0 creates the inflexibility that teams work around with console access and out-of-band changes. Under-constraining them recreates the review burden the platform was supposed to eliminate. The right calibration is inputs bounded enough to remove manual review from the standard path but flexible enough that engineers don’t need to bypass the system to get legitimate work done.
Catalog Hierarchy and RBAC Inheritance Across Child Organizations
Organizational structure decisions are Day 0 outputs in Cycloid’s model: which teams share which stacks, which catalog repositories are visible to which child organizations, which credentials are scoped to which environments. Shared stacks propagate from parent organizations to child organizations, not the reverse. For optimal governance, shared stacks should be defined at the root-level organization to ensure standardized access and streamlined maintenance. A catalog hierarchy built without reference to the actual organizational structure means stacks end up shared with teams that shouldn’t have access, or isolated from teams that need them.
Stack visibility defaults also inherit from the catalog repository at import time and cannot be changed retroactively for a batch, only per-stack. Getting the catalog hierarchy wrong in Day 0 means re-architecting it later, one stack at a time.
Day 1 Provisioning: How StackForms Enforces Day 0 Policy at Deployment
A governed Day 1 differs from an ungoverned one in a specific and measurable way: the engineer deploying the environment cannot make choices that violate Day 0 policy because those choices aren’t available to them. The governance isn’t a gate at the end of the provisioning workflow. It’s built into the interface they’re using.
The mechanisms that carry Day 0 constraints through to the provisioned environment are what separate an IDP from a collection of Terraform modules wrapped in a web form.
How StackForms Reads .forms.yml to Constrain Terraform Inputs
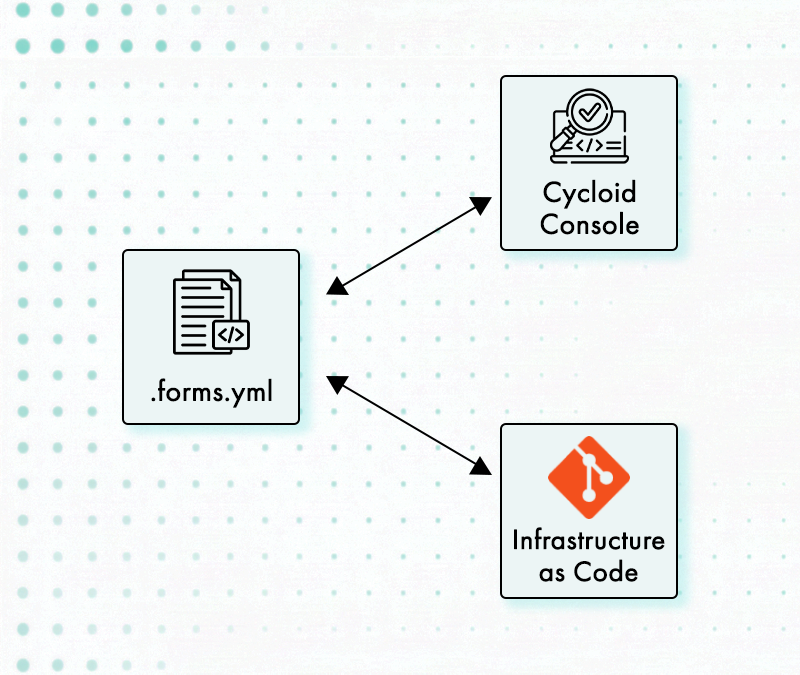
The mechanical relationship between Day 0 and Day 1 works as follows: a StackForm reads the .forms.yml defined in the catalog repository during Day 0 and presents only bounded, approved inputs to the deploying engineer. The underlying Terraform still executes, but the shape of what it can produce is constrained before execution begins. Engineers interact with the form, they don’t see raw Terraform plan output, and they don’t have access to configuration parameters that weren’t deliberately exposed.
Stack definitions and runtime configuration are split across two repositories. The catalog repository contains the stack definition (.cycloid.yml, .forms.yml, Terraform/OpenTofu modules, and pipelines). The config repository stores the user inputs captured through StackForms for each environment. This separation enforces a boundary between platform authors and platform consumers.
The pipeline triggered by a StackForm submission runs on Cycloid’s CI/CD layer, which is built on Concourse and executed by Cycloid workers (Concourse workers configured with Cycloid tooling).
Platform engineers no longer need to review every Terraform diff to verify that someone chose the correct module, instance class, or network attachment. Those choices simply aren’t available to begin with. Standard provisioning requests stop generating review work because the platform has already made the contested decisions.
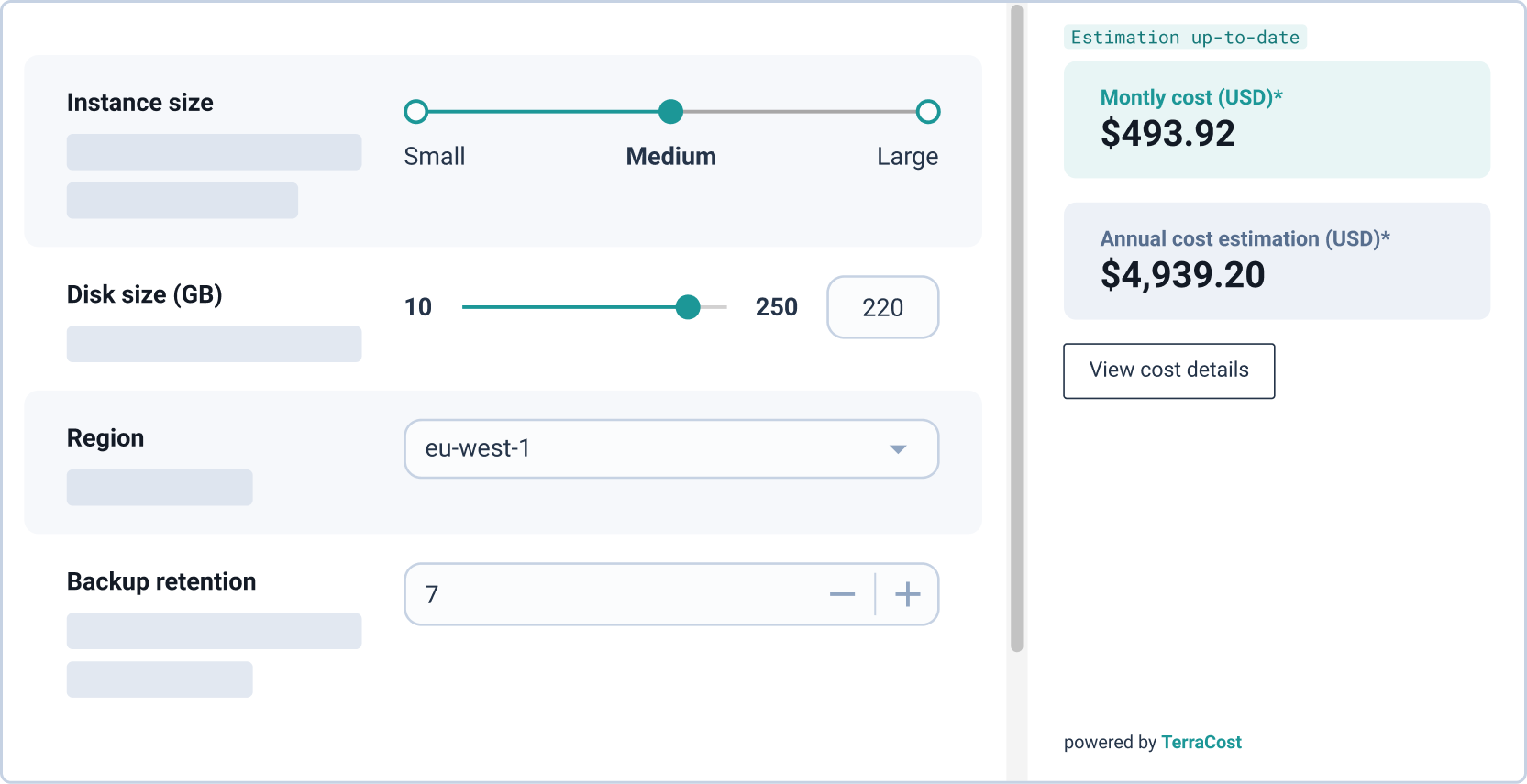
Cycloid’s StackForms also integrates with TerraCost to display a live infrastructure cost estimate before the engineer commits the configuration. That estimate is visible at provisioning time, and the final configuration is written back to the Git config repository automatically. Cost visibility at Day 1 prevents the Day 2 problem of discovering over-provisioned environments weeks after deployment when the FinOps review finally catches up.
Why Git-Backed StackForm Configs Are the Source of Truth for Drift Detection
Every StackForm configuration saves user inputs back to the config repository automatically. The deployed state has a traceable Git history from the moment the environment is created. Drift detection in Day 2 needs a ground truth to compare against actual infrastructure state, the Git commit record is that ground truth.
Teams that provision outside the governed model (manual console changes, direct terraform apply without a pipeline, ad-hoc kubectl commands against production) create environments that Day 2 tooling cannot reconcile. There’s no authoritative record of intended state, so drift detection has nothing to measure drift against. The environment exists, but from the platform’s perspective, its configuration is a mystery.
Pre-Apply Policy Evaluation: Blocking Violations Before terraform apply
Cycloid enforces governance at two distinct points, and they serve different purposes. The first layer is .forms.yml, which constrains inputs at form-render time. Engineers cannot select values outside predefined bounds because those options are never exposed in the interface. This is input-level enforcement, not policy evaluation.
The second layer is InfraPolicies, which are written in Rego (Open Policy Agent’s policy language) and evaluated against the Terraform or OpenTofu plan output before apply. These policies operate on the fully resolved infrastructure graph, not on user input. Each policy is assigned a severity level: Advisory, Soft Mandatory, or Hard Mandatory, following the same enforcement model used by HashiCorp Sentinel. This distinction matters because it separates input validation from policy-as-code enforcement at the plan stage.
Day 2 Operations: Drift Detection, Cost Governance, and Lifecycle Management
Day 2 is the longest phase by a significant margin, and the one where governance debt from Days 0 and 1 becomes operationally visible. Every shortcut taken during Day 0 design and every manual workaround accepted during Day 1 provisioning shows up here, as drift, as unexplained cost, as an environment that behaves differently than its stack definition says it should.
The scope of Day 2 is broad: monitoring, patching, scaling, configuration drift management, secret rotation, environment updates, cost optimization, and decommissioning. The challenge isn’t defining what Day 2 includes. It’s ensuring the same governance model that applied at provisioning still applies to every one of those activities.
How Drift Detection Reconciles Deployed State Against Stack Definitions
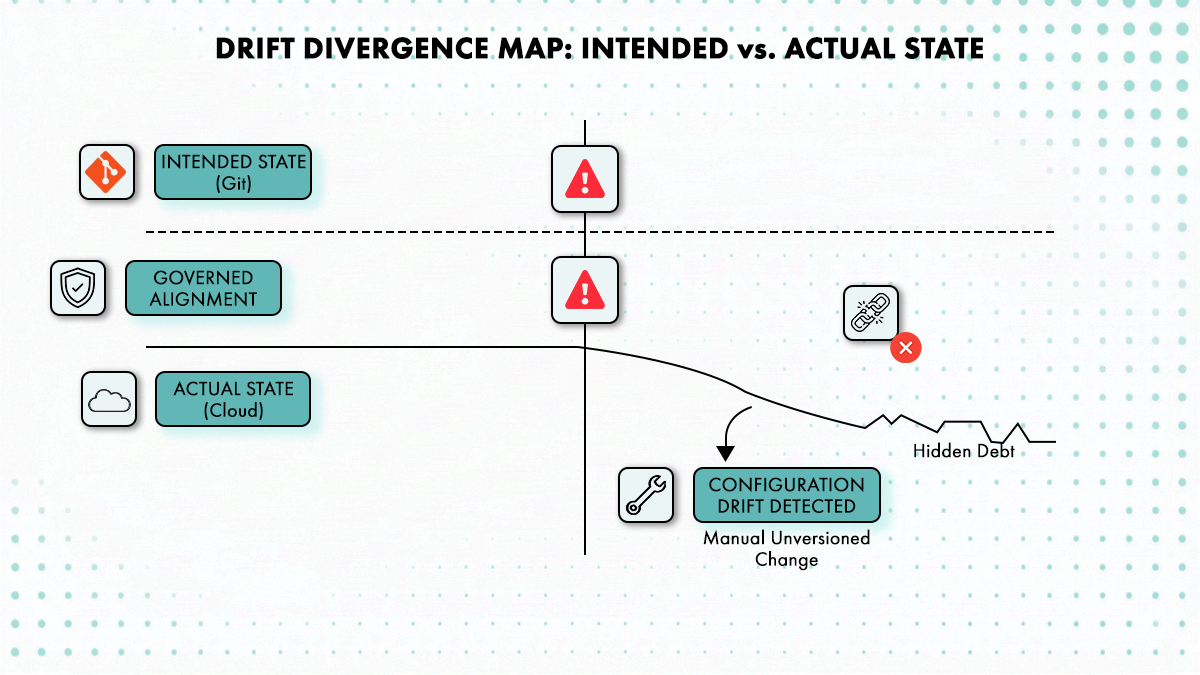
Cycloid does not run a continuous reconciliation loop like Kubernetes-native controllers such as Flux or Argo CD. Instead, drift is surfaced during Terraform or OpenTofu plan execution. InfraPolicies evaluate the planned state against expected constraints, and discrepancies caused by manual changes appear as plan differences. This means drift detection is tied to execution events rather than continuous reconciliation. The platform relies on plan-time evaluation rather than an always-on controller model, which is a different operational trade-off.
Cycloid’s drift detection alerts when deployed infrastructure diverges from the version-controlled stack configuration, giving platform teams the opportunity to re-align states before the divergence cascades into a compliance finding or an incident.
Kubernetes amplifies Day 2 complexity considerably. A misconfigured HorizontalPodAutoscaler can cause cascading failures under load. Cluster upgrades, certificate rotation, and RBAC policy maintenance all require ongoing attention. A single misconfigured HPA can trigger failure chains across services in ways that are difficult to trace retrospectively. Day 2 governance for Kubernetes means continuous reconciliation of cluster state against defined policy, not periodic post-incident audits.
Governing Day 2 Scaling, Helm Updates, and Decommissioning Through Pipelines
The governance gap most IDP implementations leave open is visible in the post-provisioning lifecycle. Self-service governance stops at creation. Scaling an environment falls back into a ticket. Updating a Helm chart gets handled with a direct helm upgrade command from a local machine. Decommissioning a service becomes an undocumented series of manual deletions across three cloud consoles.
Cycloid integrates with HashiCorp Vault for credential management, which underpins secret rotation workflows described in Day 2 operations. Updates follow defined pipeline workflows. Decommissioning enforces ownership verification and cleanup rules before resources are deleted. Governance stays consistent across the full lifecycle, not just at creation time. When Day 2 operations are treated as first-class platform actions rather than out-of-band work, governance remains enforced without adding new review loops.
Pre-Deployment Cost Estimation with TerraCost (Plus GreenOps Carbon Tracking)
Observational FinOps and operational FinOps are different disciplines with different outcomes. A dashboard showing what was spent last month tells you what happened. Budget ceilings attached to every environment prevent the over-provisioning from happening in the first place.
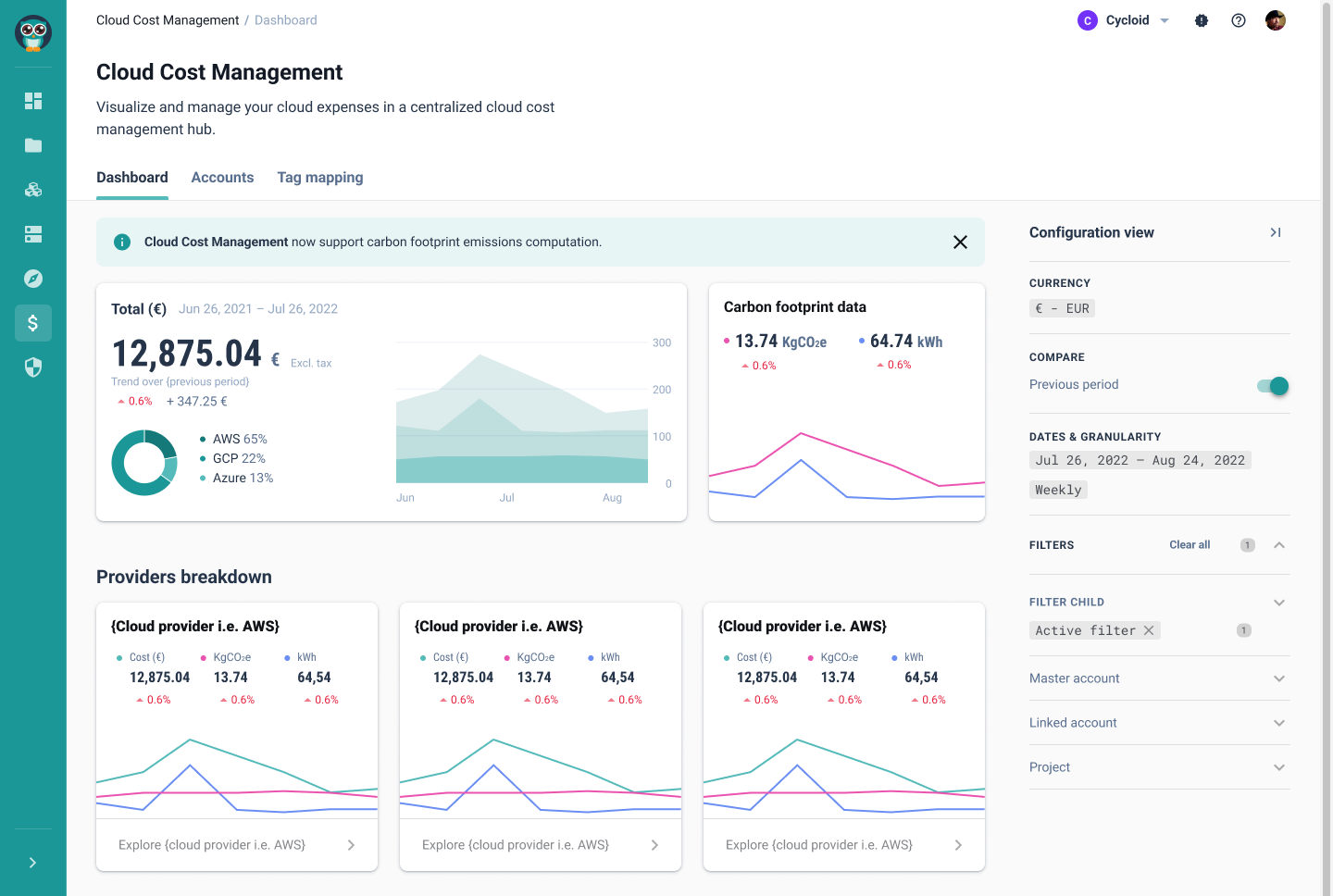
Cycloid’s GreenOps module builds on the open-source Cloud Carbon Footprint project, embedded within its FinOps Cloud Cost Management layer. Carbon estimates are derived alongside cost data, using the same infrastructure inputs. Engineers see the estimated cost generated from the Terraform or OpenTofu plan before apply. TerraCost parses the plan JSON and produces a cost estimate at the same stage where InfraPolicies are evaluated. Budget boundaries prevent resources from being created outside approved cost ranges, rather than flagging them for remediation after the spend has already occurred.
The GreenOps implication follows directly: over-provisioned compute is over-provisioned carbon emissions. Cycloid tracks carbon footprint data filtered by project, region, date, and provider from the same module that manages cost data. The environmental cost of infrastructure decisions gets surfaced at the same decision point as the financial cost, at provisioning time, before the environment exists.
Platform Tooling That Spans All Three Phases: Stacks, StackForms, Asset Inventory, and InfraView Working Together
Cycloid’s Asset Inventory is not a passive listing of resources. It is populated through Cycloid’s Terraform HTTP backend, where Terraform or OpenTofu state is stored using a JWT token (inventory_jwt). Resources flow into the inventory directly from state, making it the authoritative record of managed infrastructure. Cycloid also exposes a CLI (cycloid-cli) and a Terraform provider (cycloidio/cycloid), allowing platform teams to manage Cycloid resources programmatically.
This inventory is also exposed to StackForms through the cy_inventory_resource widget, allowing engineers to reference existing resources such as VPCs when provisioning new environments. This is how Day 2 state becomes reusable input for Day 1 workflows.
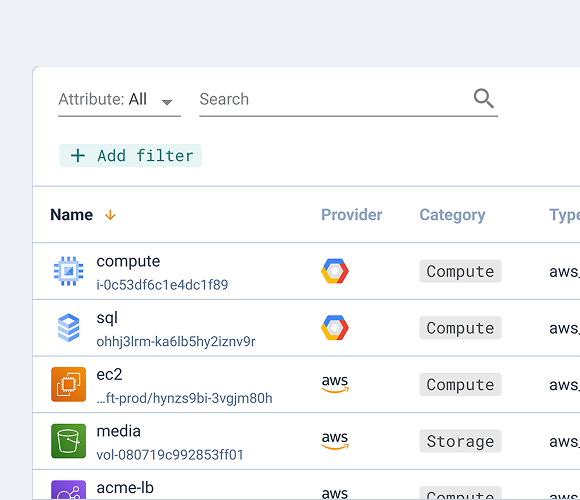
InfraView builds on this by reading the .tfstate file directly to render infrastructure relationships. It does not query cloud provider APIs, which means it reflects only what is managed through Terraform or OpenTofu. Resources created outside the platform will not appear, which is an intentional constraint tied to state-based visibility.
Stack Lifecycle: Catalog Definition → Provisioning → Day 2 Updates
The lifecycle of a Cycloid Stack runs as follows: defined during Day 0 in a catalog repository with a .forms.yml that encodes approved inputs, consumed during Day 1 provisioning via StackForms, and referenced during Day 2 for updates, drift reconciliation, and decommissioning. Unlike a generic YAML configuration file, .forms.yml defines the user-facing contract of the stack, what inputs are exposed, how they are validated, and which values are constrained before Terraform ever runs. A Stack is not just a provisioning template. It’s the canonical description of the intended state across the full lifecycle. When an environment drifts, the Stack definition is what it has drifted from.
A minimal example of .yml looks like this:
| version: “1” use_cases: – name: “deploy” sections: – name: “Compute” groups: – name: “Instance configuration” fields: – name: “instance_type” label: “Instance Type” type: “select” values: – “t3.medium” – “t3.large” default: “t3.medium” required: true – name: “disk_size” label: “Disk Size (GB)” type: “number” min: 20 max: 200 default: 50 |
This is structurally different from Terraform variables or standard YAML configuration in two ways. The file is not describing infrastructure; it is defining what an engineer is allowed to choose when requesting infrastructure. Fields like values, min, and max enforce boundaries at input time, not during plan or apply.
The result is that .forms.yml acts as a control layer in front of Terraform. Instead of reviewing a plan to catch an invalid instance type or oversized disk, those options are never exposed in the first place. That distinction is what allows Day 1 provisioning to run without manual review while still enforcing Day 0 policy.
Shared stacks defined at the root organization propagate to child organizations. A policy change to a shared stack at the root level propagates to every Day 2 environment that uses it, which means a governance update made during a periodic Day 0 review applies retroactively to running environments at the next update cycle, without requiring individual environment patches.
InfraView for Day 2 Resource Ownership, Drift, and Cost Visibility
Cycloid’s Asset Inventory maintains visibility into all deployed infrastructure resources, linked to the Stack that provisioned them. Engineers can see what exists, who owns it, and which Stack version it corresponds to, without requiring direct cloud console access. Direct console access is, itself, a drift risk, every engineer with console access is an engineer who can make changes that bypass the governance model.
InfraView exposes ownership, drift, and cost impact across environments in a single view. Platform teams use it during Day 2 to identify environments that have diverged from their stack definition, confirm ownership before decommissioning, and validate that cost boundaries are being respected across the fleet.
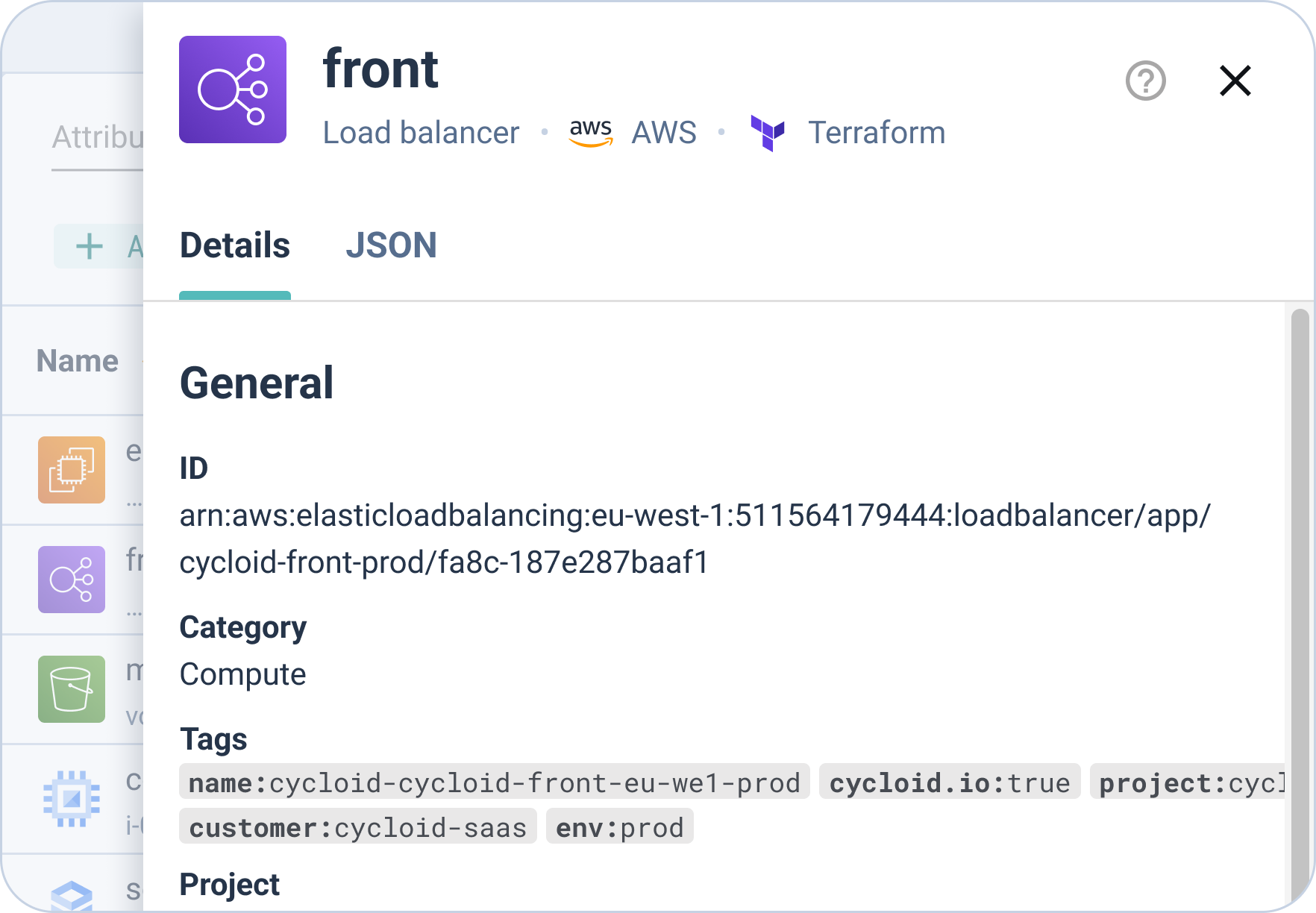
In practice: an on-call SRE can trace a misbehaving environment back to its Stack version, its config repository commit, and its StackForm configuration without opening the cloud provider console. The investigation starts with the platform, not with a series of ad-hoc API calls.
CI/CD Pipelines as the Execution Layer for Day 2 Automation
Cycloid’s pipeline layer runs on Concourse, with pipelines executed by Cycloid workers. The same runtime executes both Day 1 provisioning and Day 2 lifecycle actions, which keeps enforcement consistent across the lifecycle. Cycloid’s managed CI/CD pipelines serve as the execution layer for Day 2 automation: Helm chart updates, secret rotations, environment patches, and runbook-codified recovery actions. These pipelines are version-controlled, reusable across stacks, and modular. Day 2 operations that previously required manual intervention can be codified and triggered via the same self-service model used for Day 1 provisioning.
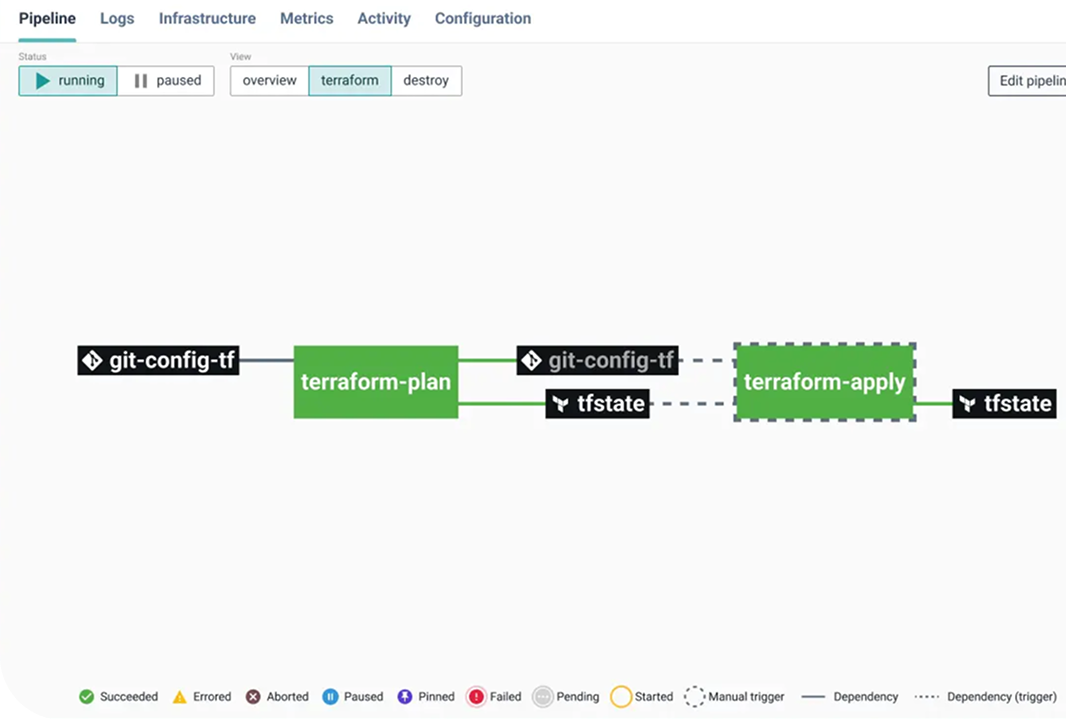
Teams that use separate tools for Day 2 tasks (Rundeck for runbooks, manual kubectl for Kubernetes changes, direct console access for scaling) create the same fragmentation problem that IDPs exist to address. Separate Day 2 tooling generates separate audit trails, separate governance gaps, and separate cognitive load. The engineer who needs to respond to a Day 2 incident shouldn’t have to remember which of four systems has the relevant action.
Where Day 0/1/2 Governance Actually Breaks in Enterprise Deployments
The failure modes that appear at scale or in brownfield environments tend to share a common root: the governance model assumed a clean start that the actual environment never had.
Understanding these failure modes matters not just for diagnosing existing problems, but for designing the Day 0 artifacts that will prevent them in future deployments.
Brownfield Environments Where Day 0 Never Happened
Many organizations run significant cloud infrastructure that was provisioned before any governed IDP existed. There’s no Day 0 artifact to reference, no canonical stack definition, and no Git history of intended state. Day 2 governance for these environments can’t start from a Stack definition because none exists.
InfraImport is currently a beta feature and operates on a best-effort basis. The generated Terraform code requires review and adaptation by platform teams before being used in production workflows. Cycloid’s InfraImport addresses this directly. The reverse Terraform generator, built on the same concepts as Cycloid’s open-source TerraCognita project, which has over 2,400 GitHub stars, reads existing cloud resources and generates IaC configuration and Stack templates from what’s already deployed. The output is a retroactive Day 0 artifact from which Day 2 governance can start. It won’t reconstruct the original intent behind every configuration decision, but it creates the version-controlled baseline that drift detection and ongoing governance require.
Multi-Cloud and Hybrid Environments Where Governance Policies Diverge
Large enterprises run workloads across multiple cloud providers and on-premises environments. Governance policies designed for AWS don’t automatically translate to Azure or GCP. Cost data lives in separate billing systems. RBAC models differ across providers. Teams managing workloads across multiple environments frequently apply different governance standards to different environments not because they want inconsistency, but because their tooling doesn’t unify the governance model across providers.
Cycloid stacks support AWS, Azure, GCP, and VMware vSphere through Terraform or OpenTofu. InfraImport (based on TerraCognita) targets the same providers, while the Terraform HTTP backend used by Asset Inventory supports S3-compatible storage such as AWS S3, Google Cloud Storage, Azure Blob Storage, and MinIO. The FinOps module centralizes cost data across all cloud providers in a single view, filtered by project, region, and provider. The governance model encoded in a Stack definition doesn’t change based on where the Stack is deployed, which means the Day 2 drift and cost management problems don’t require separate tooling per cloud.
The Self-Service Adoption Problem That Makes Day 2 Governance Collapse
An IDP with governed self-service only controls Day 2 operations for the environments provisioned through it. Teams that adopt workarounds, direct console access, ad-hoc terraform apply runs outside the pipeline, kubectl commands against production clusters, create ungoverned environments that sit entirely outside the observability and governance layer. The platform doesn’t know those environments exist in the form they currently have, so it can’t detect drift, enforce cost boundaries, or apply lifecycle governance to them.
The organizational signal Cycloid documents is worth noting: manual review requests that the platform can’t resolve on its own represent missing context, missing constraints, or missing defaults in the Stack definitions. Each one is a signal to improve the Day 0 artifact, tighten the .forms.yml, add a missing default, extend the governance to a lifecycle action that currently falls out of scope. Adding a human reviewer to handle the gap is the more expensive response, and it doesn’t fix the underlying problem.
Conclusion
The Day 0/1/2 model is only as durable as the governance layer spanning all three phases. This article covered how Day 0 produces the engineering artifacts, RBAC boundaries, .forms.yml stack definitions, catalog visibility hierarchies, that constrain every downstream operation. Day 1 provisioning, governed through StackForms and GitOps commit records, carries those constraints into the deployed environment without requiring manual review for standard requests. Day 2 operations, when treated as first-class platform actions rather than out-of-band work, apply the same enforced paths to scaling, updates, and decommissioning that applied at creation time.
Cycloid’s tooling, Stacks, StackForms, Asset Inventory, InfraView, and managed CI/CD pipelines, spans all three phases, with drift detection and FinOps governance keeping the platform aligned against the intended state it was designed to maintain. The platform doesn’t replace engineering judgment. It stops requiring judgment on decisions that were already made on Day 0.
FAQs
1. What is the difference between Day 0, Day 1, and Day 2 operations?
Day 0 is the design phase where you build the templates, RBAC, and policies that constrain everything downstream. Day 1 is the deployment window where you provision the initial infrastructure. Day 2 is the sustained state, the longest phase covering scaling, patching, and drift management until the system is decommissioned.
2. How do IDPs enforce governance during Day 2?
Governance remains active by forcing post-provisioning changes (like scaling or updates) through the same guarded workflows used at launch. Instead of manual console edits, changes must pass through version-controlled forms and pipelines that respect pre-defined budget ceilings and security boundaries.
3. What causes configuration drift and how is it resolved?
Drift occurs when manual “hotfixes” are made directly in the cloud console, bypassing version control. Platform teams resolve this through continuous drift detection, which compares the live environment against the Git-backed Stack definition and alerts teams to reconcile the states before failures occur.
4. How does Day 2 governance work for Kubernetes at scale?
Because Kubernetes has multiple moving parts like HPAs and network policies, governance is baked into the deployment templates. This ensures that certificate rotation, scaling limits, and cluster upgrades are handled automatically and consistently across all teams, preventing small configuration errors from becoming major outages.


