
TLDR
- Platform engineering is no longer about reducing Jira volume but about creating stable, reusable contracts. A successful IDP separates the “how” of infrastructure from the “what” of delivery, allowing developers to deploy without mastering the underlying cloud complexity.
- Most platforms fail by either building ignored portals or creating “black box” abstractions that make debugging impossible. The elite 2026 stack balances service scaffolding with deep runtime visibility, ensuring the platform is a tool for speed rather than a barrier to troubleshooting.
- Holding nearly 90% market share, Backstage is the undisputed industry “front door,” yet it remains a framework, not a turnkey product. Adoption requires dedicated headcount to manage fragile plugin ecosystems and frequent breaking changes that can stall internal progress for weeks.
- Choose your platform based on your primary bottleneck: use Cycloid or Humanitec if infrastructure provisioning and state management are your pain points. Opt for Port, Cortex, or OpsLevel if your goal is mapping microservice sprawl and enforcing operational maturity scorecards.
- For cloud-native purists, tools like Kratix and Upbound transform Kubernetes into the universal orchestrator for all resources. This “Infrastructure-as-Code-as-API” approach provides the highest ceiling for customization but demands a platform team with deep controller-level expertise.
- SaaS IDPs offer immediate time-to-value by offloading the operational burden of databases and state locking to vendors. Conversely, self-hosted solutions offer total data sovereignty but inherit a permanent tax of maintenance, upgrades, and disaster recovery that many teams underestimate.
The State of Internal Developer Platforms in 2026
Platform teams ship IDPs to reduce cognitive load, not ticket volume. The goal is letting engineers deploy without needing to understand Terraform state locks, Kubernetes admission controllers, or AWS IAM role chaining.
By 2026, 80% of large software engineering organizations will establish platform engineering teams to provide reusable services, components and tools via platforms for application delivery, according to Gartner. In 2025 alone, over 55% of organizations have already adopted platform engineering. This isn’t trend following. It’s table stakes.
Most IDPs fail because they solve the wrong problem i.e., they build portals engineers ignore, or they abstract so much that debugging becomes archaeology. This comparison focuses on how each platform handles three things: service scaffolding, infrastructure provisioning, and runtime visibility. We’ll evaluate 11 platforms on deployment model, extensibility, operational cost, and where they become bottlenecks, backed by documentation and production references.
What an Internal Developer Platform Does
An IDP sits between your engineers and your infrastructure. It templates common workflows, enforces guardrails, and exposes self-service actions without requiring infrastructure expertise.
The platform does not replace Kubernetes, Terraform, or your CI/CD pipeline. It wraps them in a contract engineers can use without reading 400 pages of AWS documentation. A working IDP has three layers: a service catalog (what can I deploy), an orchestration engine (how does it get deployed), and an integration surface (where does it run). Most products only solve one of these well.
Why Most IDP Comparisons Are Useless
Feature matrices count integrations, not capabilities; They list “GitOps support” without explaining whether that means ArgoCD native support or a webhook that triggers a bash script.
Real differences show up under load. Can the platform handle 50 teams deploying 200 services across 12 AWS accounts? Does it break when someone needs a non-standard Postgres extension? This article evaluates platforms on deployment model, extension points, operational cost, and where they become a bottleneck.
Evaluation Criteria for This Comparison
Six dimensions separate working platforms from vaporware. Here’s how this comparison measures each one.
Architecture and Deployment Model
Self-hosted platforms demand infrastructure you maintain forever. SaaS platforms outsource that burden but lock you into their update cadence. Hybrid models split the difference, usually with a managed control plane and self-hosted workers.
]
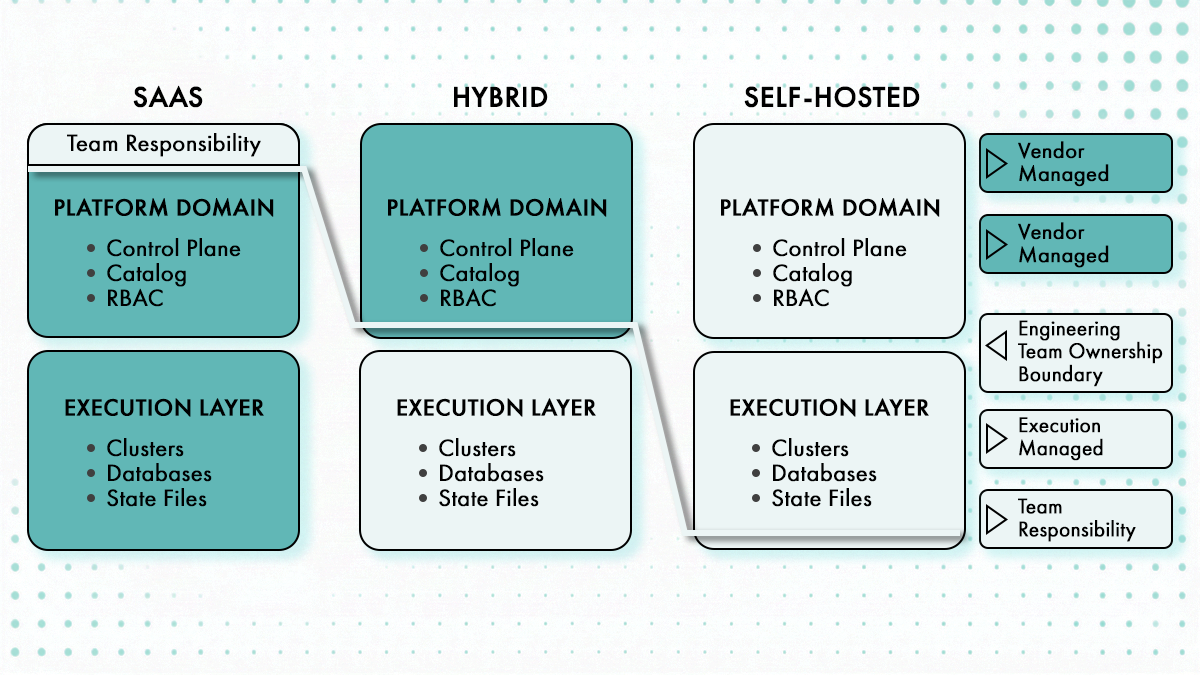
The deployment model determines operational overhead before you write a single line of config. Backstage requires PostgreSQL (not hosted on the same server as the Backstage app, the PostgreSQL port needs to be accessible, default is 5432 or 5433), persistent volumes for state, and a container orchestration platform. Production deployments require PostgreSQL, GitHub App auth, RBAC, and Kubernetes hosting. SQLite and guest auth are demo-only.
Extensibility and Customization
Can you add custom workflows without forking the codebase? What’s the plugin model? Can non-platform engineers contribute templates? Extensibility determines whether you’ll still be using this platform in 18 months or rewriting it from scratch.
Backstage’s plugin model is the most mature but also the most fragile. Breaking changes to alpha or beta exports must result in at least a minor version bump and may be done without a deprecation period. The backend system getting promoted to 1.0.0 means the API is now stable and breaking changes should not occur until version 2.0.0, but that stability only applies to the core framework.
Most platforms claim extensibility but actually mean “you can write code that calls our APIs.” Real extensibility means non-platform engineers can contribute templates, policies, or workflows without understanding the platform’s internals. StackForms in Cycloid achieves this by constraining inputs to what teams are allowed to change while fixing everything else at the platform level. Port’s blueprint model lets you define custom entity types and relationships without writing Go or TypeScript.
Infrastructure Provisioning
Does it manage Terraform state? Does it handle drift detection? Can it provision multi-cloud resources or is it Kubernetes-only? Most “platform engineering tools” are really just Kubernetes dashboards wearing trench coats.
Terraform state management is table stakes for infrastructure-first IDPs. State locking prevents concurrent modifications. State history lets you roll back when things break. Remote backends (S3, GCS, Terraform Cloud) enable team collaboration but introduce their own operational complexity.
Drift detection separates platforms that manage infrastructure from those that just deploy it. Terraform plan queries your cloud provider to get the actual state of all managed resources and compares it with the state file. Terraform drift emerges when there’s a disparity between how Terraform understands a resource’s state (based on the state file) and how that resource actually exists in reality.
Developer Experience
CLI support, API quality, and whether the UI actually gets used or becomes shelfware. The best platform in the world is worthless if engineers route around it.
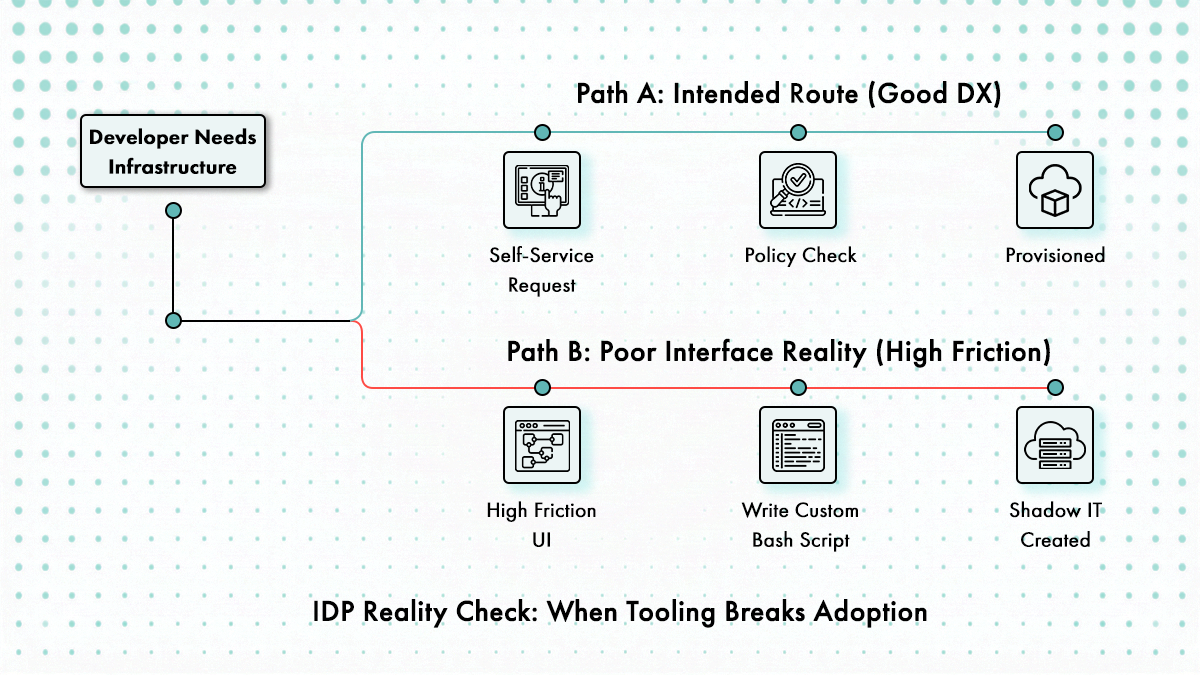
Developer experience determines adoption, and adoption determines ROI. Platforms with clunky UIs get bypassed. Engineers will spend 20 minutes writing a bash script to avoid 5 minutes of clicking through a portal they hate. The CLI needs feature parity with the UI. API-first platforms (Port, Cycloid) let engineers script everything, which means power users stay engaged instead of filing Jira tickets asking for features the UI doesn’t expose.
Operational Overhead
Maintenance burden, upgrade frequency, and how much firefighting the platform team inherits. Every platform promises to reduce toil. Most just move it from app teams to platform teams. Self-hosted platforms incur ongoing operational cost that never appears in vendor comparisons. Don’t run SQLite in production, it doesn’t support concurrent writes. PostgreSQL is non-negotiable for any deployment beyond a single-user demo. You’re managing databases, Kubernetes clusters, secrets rotation, certificate renewals, and disaster recovery.
SaaS platforms eliminate infrastructure maintenance but introduce different overhead. You’re maintaining integrations, not servers. Data sync jobs break when APIs change. Rate limits get hit during batch operations. The platform vendor’s SLA becomes your SLA, and you can’t fix their outage at 2am.
Ecosystem and Maturity
Community size, production references, and whether the vendor will exist in two years. Open-source doesn’t guarantee survival, and proprietary doesn’t guarantee support. As of January 2026, Backstage is used by more than 3,400 organizations and serves over 2 million developers outside of Spotify, commanding 89% market share among internal developer portal frameworks. That adoption creates a self-reinforcing ecosystem. Plugins get maintained because companies have engineers dedicated to Backstage. Bugs get fixed because enough people hit them that GitHub issues don’t rot.
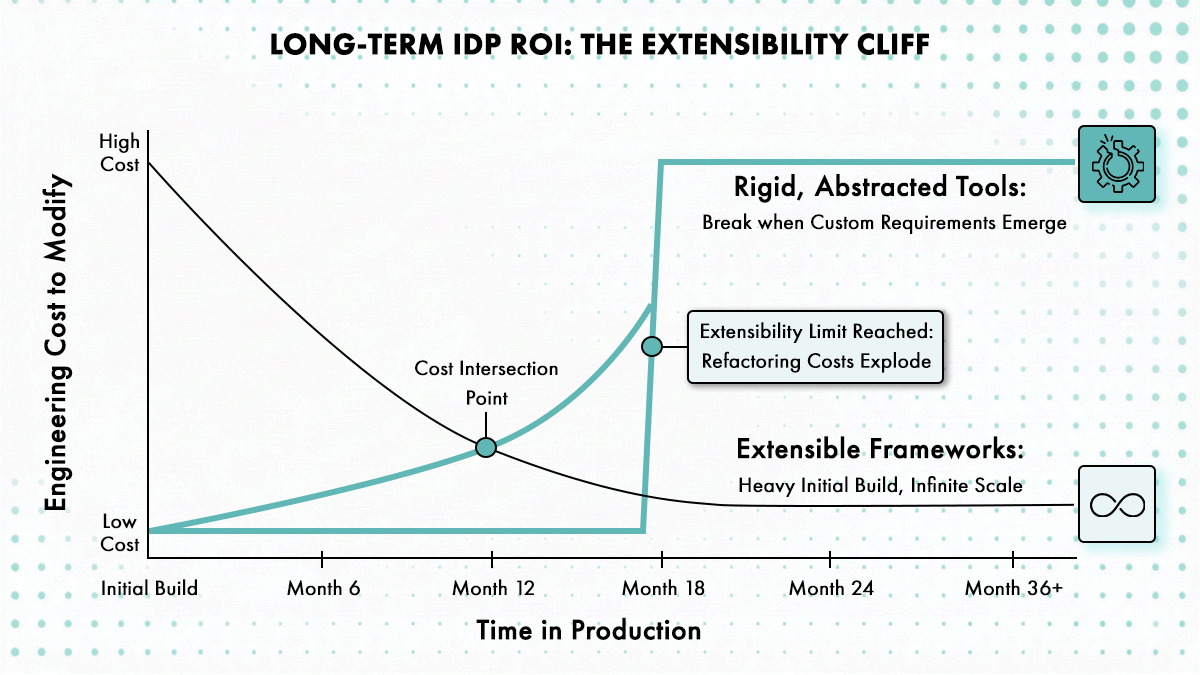
Vendor viability matters for proprietary platforms. Small vendors with single-digit customer counts might ship great products, but if they get acquired or shut down, your platform becomes shelfware. Check funding, revenue model, and whether the product is a core business line or an acquisition that’s being sunsetted.
Top 11 Internal Developer Platforms in 2026
Here’s what each platform actually does, where it fits, and what you’re trading off when you pick it.
1. Cycloid
What It Is
Cycloid is an internal developer platform that combines infrastructure orchestration, governance, and cost visibility into a single system. It uses a concept called “Stacks” to package infrastructure, CI/CD pipelines, and operational workflows into reusable units. Developers interact with these stacks through self-service forms, which trigger deployments without exposing underlying complexity.
Cycloid integrates with Terraform, Kubernetes, and cloud providers while maintaining control through policy enforcement. It includes cost estimation and sustainability metrics, allowing teams to evaluate infrastructure impact before deployment. The platform focuses on reducing ticket-based workflows by giving developers controlled access to infrastructure. It is designed for organizations that want to standardize deployments while maintaining governance and visibility.
Deployment Model
SaaS with optional on-premise workers for sensitive environments. The control plane is managed; execution happens in your infrastructure.
Strengths
Treats infrastructure as a first-class concern, not an afterthought. Built-in Terraform state management, cost tracking per environment, and policy enforcement before apply. Cycloid’s StackForms is a self-service portal that acts as the glue between your workloads, ensuring your services work end-to-end. It provides cost estimation before deployment, giving users visibility into the financial impact of their infrastructure choices.
The StackForms abstraction lets non-platform engineers request infrastructure without writing HCL. Each environment acts like a “mini cloud tenant” within the project, giving MSPs total control over compliance, access, and billing. StackForms are YAML-first stack definitions backed by Terraform, not raw Terraform modules and not just UI forms. Inputs are constrained to what teams are allowed to change. Everything else is fixed by the platform.
InfraView provides a visual representation of the infrastructures deployed on your project’s different environments and inspects the Terraform state information for each instance. You get infrastructure diagrams that auto-generate from live state, not stale wiki pages someone updated six months ago. Cycloid is built with automation-first architecture, using your existing plans and state files to manage infrastructure.
Weaknesses
Smaller plugin ecosystem than Backstage. If your workloads are 100% Kubernetes-native and you don’t care about IaC, this might be overbuilt.
Best For
Teams managing multi-cloud infrastructure where cost control and compliance matter as much as velocity. Works well for orgs with both VMs and containers.
Operational Notes
Low maintenance overhead because the control plane is managed. You maintain workers and pipelines, not the platform itself. Cycloid helps cut repetitive tickets, sometimes up to 70% fewer, and accelerates time-to-delivery from hours (and sometimes days) to minutes.
2. Backstage (Spotify)
What It Is
Backstage is an open source developer portal framework created by Spotify that acts as a central interface for services, documentation, and engineering workflows. It does not provision infrastructure or enforce deployment standards by itself, instead it aggregates existing systems such as CI pipelines, Kubernetes clusters, and monitoring tools into a unified UI. Teams define software templates that standardize how new services are created, including repository structure, CI configuration, and deployment hooks.
Its plugin-based architecture allows integration with internal tools, but also requires ongoing maintenance to keep those integrations working. Backstage is often used as the “front door” of an internal developer platform, while actual provisioning and policy enforcement happen in other systems. It works best in organizations that already have mature infrastructure and want to improve discoverability and consistency across teams.
Deployment Model
Self-hosted; Requires Node.js runtime, PostgreSQL, and persistent storage. Most orgs run it in Kubernetes.
Strengths
Largest plugin ecosystem. As of January 2026, Backstage is used by more than 3,400 organizations and serves over 2 million developers outside of Spotify, commanding 89% market share among internal developer portal frameworks. If you need to integrate with an internal tool, someone’s probably written a plugin.
The software catalog is genuinely useful for microservice sprawl. Adopters span varied sizes and industries, including American Airlines, Expedia, LinkedIn, HP, Booking.com, Siemens, Vodafone, LEGO, Mercedes-Benz, Zalando, IKEA, Wayfair, Splunk, Epic Games, Unity, PagerDuty, Twilio, CVS Health, and many others. American Airlines built “Runway” on Backstage starting in May 2020, enabling teams to deploy applications with public ingress in under 6 minutes.
Weaknesses
Does not provision infrastructure by itself. You’re stitching together plugins for Terraform, ArgoCD, and whatever else you need. Upgrades break plugins constantly because the core API is still moving.
56% of Backstage adopters cite upgrades as their biggest pain point. Breaking changes in plugin APIs mean that upgrading Backstage versions often requires refactoring your entire plugin ecosystem. Internal adoption rates hover around 10% on average, frequently because teams exhaust their capacity on maintenance before delivering the features that developers actually want to use.
Best For
Teams that want control over every integration and have engineers to maintain it. Not a turnkey solution.
Operational Notes
Expect to spend 1-2 FTEs just keeping Backstage running and plugins updated. The plugin model is powerful but fragile. One client’s platform team spent six weeks on a single major version upgrade.
3. Port
What It Is
Port is a developer portal platform that focuses on creating a customizable software catalog and self-service workflows. It allows teams to model entities such as services, environments, and resources as structured objects with defined relationships. These entities are populated using data from existing systems like Kubernetes, CI pipelines, and cloud providers.
Port provides a UI where developers can trigger actions such as creating environments or deploying services, backed by automation scripts or pipelines. It does not replace infrastructure tools, but acts as a control layer that connects them into a consistent interface. The platform emphasizes flexibility, allowing teams to define their own data model instead of adopting a fixed schema. This makes it suitable for organizations that want a portal without committing to a specific infrastructure pattern.
Deployment Model
SaaS. No self-hosting option.
Strengths
Excellent for visibility and discovery. Blueprints are the foundational building blocks of the internal developer portal. They hold the schema of the entities you wish to represent in the software catalog. The entity model makes it easy to answer questions like “which services depend on this database?” or “show me all production resources in AWS us-east-1.”
Relations are the connections between blueprints, capturing the dependencies between them. Relationships can be single (e.g., a package version to a package) or multiple (e.g., the packages used by a service), and they enable the representation of the software catalog as a dynamic graph database. This makes Port particularly good for understanding blast radius and impact analysis.
Weaknesses
Provisioning is secondary. You can trigger workflows, but the platform doesn’t manage state or reconcile drift. It’s a control plane, not an execution engine.
Best For
Teams that already have solid provisioning workflows and need better service catalog and dependency tracking.
Operational Notes
Minimal, since it’s SaaS. You’re maintaining integrations and data sync jobs, not infrastructure.
4. Humanitec
What It Is
Humanitec is a platform orchestration layer that separates application configuration from infrastructure provisioning. Developers define what their application needs, such as a database or message queue, without specifying how it is provisioned. The platform uses a resource definition model to map these requirements to actual infrastructure components across environments. This allows consistent deployments across development, staging, and production without duplicating configuration.
Humanitec integrates with Kubernetes and CI pipelines, acting as a control plane rather than replacing them. It reduces the need for developers to interact directly with Terraform or cloud APIs. The system is designed to prevent configuration drift by enforcing environment-specific mappings centrally.
Deployment Model
SaaS with operator components running in your clusters.
Strengths
Score specification is clean and the resource graph concept works well for preview environments and dynamic scaling. Strong Kubernetes-native workflows.
Weaknesses
Locked into their abstraction model. If you need infrastructure that doesn’t fit the resource graph (legacy VMs, bare metal, etc.), you’re writing custom drivers. Limited Terraform support compared to dedicated IaC platforms.
Best For
Cloud-native orgs running everything in Kubernetes who want opinionated workflows and can live with the abstraction tradeoffs.
Operational Notes
Lower overhead than Backstage, higher than fully managed platforms. You’re maintaining operators and resource definitions.
5. Kratix (Syntasso)
What It Is
Kratix is a Kubernetes-based platform framework that defines platform capabilities as custom resources, called Promises, which developers can request without managing underlying infrastructure. A Promise represents a service such as a database, queue, or application runtime, along with the workflows required to provision and configure it. Platform teams define these Promises once, including validation, provisioning logic, and policy constraints, and developers consume them declaratively.
Kratix runs entirely inside Kubernetes and uses controllers to reconcile requested resources into actual infrastructure or services. It separates the interface developers use from the implementation platform teams manage, which keeps workflows consistent across environments. The system is designed for teams that want Kubernetes to act as the control plane for their internal developer platform.
Deployment Model
Self-hosted. Runs entirely in Kubernetes using CRDs and operators.
Strengths
Clear separation between platform definitions and developer requests reduces repeated infrastructure logic. Native Kubernetes model fits well with teams already running cluster-centric operations. Promises allow standardization of services without exposing implementation details. Works well with GitOps and controller-based reconciliation patterns.
Weaknesses
You’re building the IDP, not buying it. Kratix is a framework, not a product. Expect to write a lot of YAML and custom controllers.
Best For
Platform teams with deep Kubernetes expertise who want full control and don’t mind building abstraction layers themselves.
Operational Notes
High. You’re maintaining the framework, the promises, and all the integration logic. This is DIY with better scaffolding.
6. Cortex
What It Is
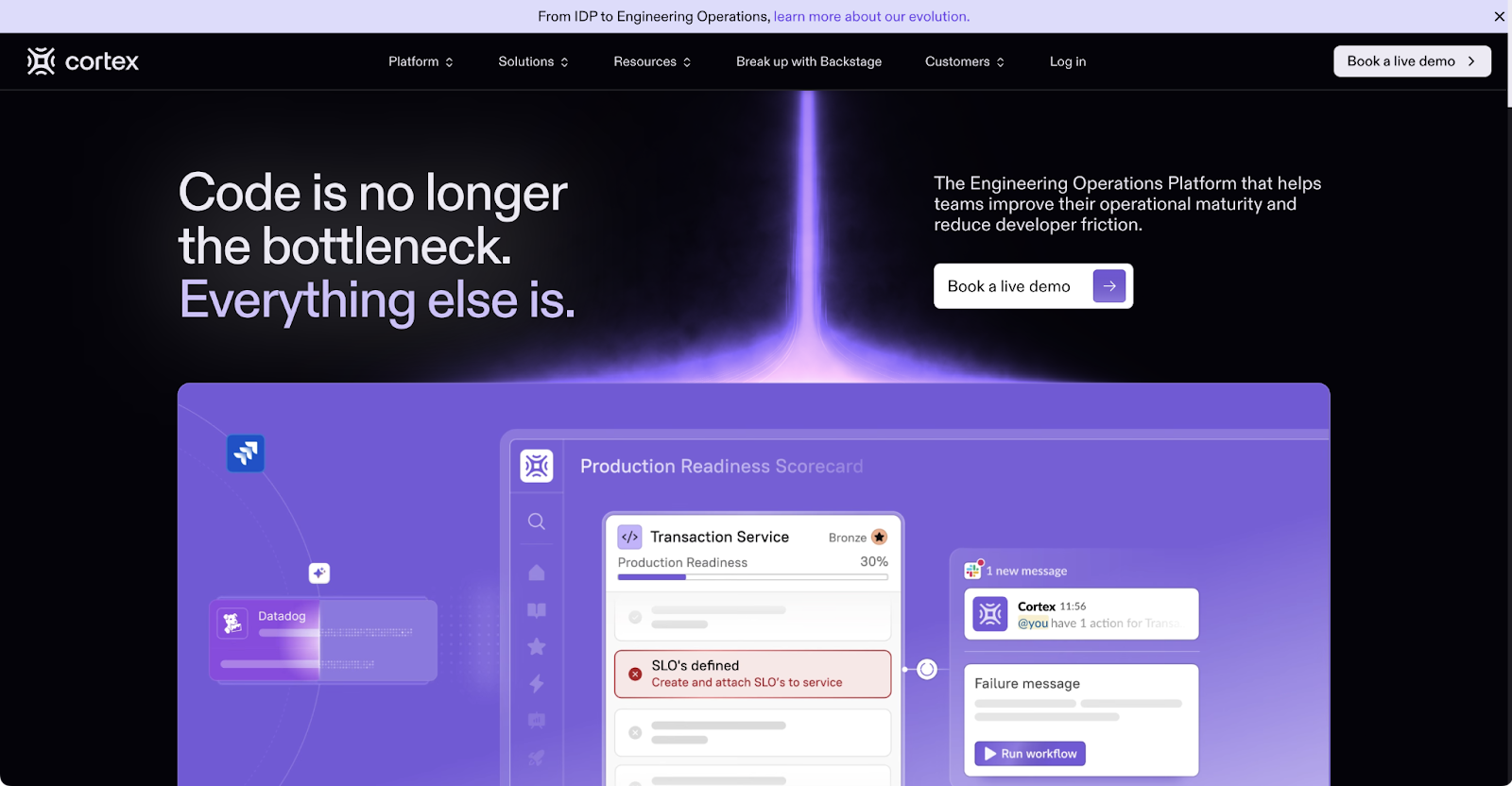
Cortex is a developer portal focused on service ownership, operational maturity, and engineering standards rather than infrastructure provisioning. It ingests metadata from repositories, CI systems, incident tools, and observability platforms to build a real-time catalog of services. Teams can define scorecards that enforce requirements such as test coverage, runbooks, on-call rotations, and security checks.
Cortex does not deploy applications or manage infrastructure directly, instead it provides visibility and governance across existing systems. The platform helps engineering leadership track service health and enforce best practices without blocking developer workflows. It integrates with tools like Datadog, PagerDuty, and GitHub to reflect the actual state of services rather than relying on manual updates. It is often used alongside other IDP components that handle provisioning and deployment.
Deployment Model
SaaS.
Strengths
Best-in-class scorecards. You can define service maturity criteria (has runbook, has oncall rotation, passes security scan) and track compliance across teams. Good for organizational visibility.
Weaknesses
Not a provisioning platform. You can track services and measure health, but Cortex won’t deploy them for you.
Best For
Larger orgs with service sprawl who need standardization and visibility before they tackle self-service provisioning.
Operational Notes
Minimal. SaaS platform with integrations to maintain.
7. Qovery
What It Is
Qovery is a platform layer that abstracts Kubernetes and cloud infrastructure into a developer-facing deployment system. Developers define applications, databases, and environments through a simplified configuration model, while Qovery handles provisioning, networking, and scaling behind the scenes. It maps high-level service definitions to Kubernetes resources without requiring teams to write manifests or manage clusters directly.
The platform integrates with Git workflows, where commits trigger builds and deployments across environments. It supports common components such as managed databases, background jobs, and preview environments as first-class entities. Qovery sits between a traditional Platform-as-a-Service and a custom internal developer platform, giving teams structured environments without building everything from scratch.
Deployment Model
SaaS platform that provisions and manages infrastructure on cloud providers like AWS, using Kubernetes under the hood.
Strengths
Reduces the need to manage Kubernetes directly, which removes a significant operational burden for smaller platform teams. Git-driven workflows align with how developers already ship code, so adoption is straightforward.
Environment management is built in, making it easier to create isolated staging or preview setups without extra tooling. The platform handles infrastructure concerns like scaling and networking without exposing low-level configuration.
Weaknesses
Abstraction comes at the cost of control, which can be limiting for teams with complex infrastructure requirements. Deep customization of Kubernetes behavior or cloud resources is harder compared to managing them directly. It is less suitable for organizations that already have mature platform engineering practices and need fine-grained control.
Best For
Teams that want Kubernetes-backed deployments without managing cluster complexity, especially startups or mid-sized organizations building their first internal platform layer.
Operational Notes
Moderate. While Qovery removes cluster management overhead, teams still need to understand how their services map to underlying infrastructure, especially for performance tuning and cost control.
8. Nullstone
What It Is
Nullstone is a platform that standardizes infrastructure and application deployment by defining environments as structured units with preconfigured components. It uses a layered approach where platform teams define environment blueprints, including networking, compute, and dependencies, and developers deploy services into those environments. Under the hood, it relies on Terraform for infrastructure provisioning and integrates with CI/CD pipelines for application delivery.
Nullstone organizes services, environments, and infrastructure into a consistent model, which reduces configuration drift across stages. Developers interact with the platform through a simplified interface, while the underlying infrastructure remains controlled by predefined templates. The focus is on repeatable environments rather than exposing raw infrastructure controls.
Deployment Model
SaaS platform with Terraform-based provisioning and integration into existing CI/CD systems.
Strengths
Strong environment standardization reduces inconsistencies between staging and production. Terraform integration allows reuse of existing infrastructure modules. Clear separation between platform-managed infrastructure and developer-managed services. Simplifies onboarding for teams deploying into prebuilt environments.
Weaknesses
Heavily tied to Terraform, which limits flexibility for non-IaC workflows. Less suitable for highly dynamic or custom infrastructure setups. Abstraction can hide details that platform teams may still need to troubleshoot.
Best For
Small to mid-size teams deploying standard application patterns who don’t want to become cloud experts.
Operational Notes
Low. SaaS platform; you maintain application definitions and module configurations.
9. OpsLevel
What It Is
OpsLevel is a service catalog and operational maturity platform that focuses on defining and enforcing engineering standards. It tracks services, ownership, dependencies, and operational signals such as incidents and deployments. Teams can define checks that enforce requirements like documentation, monitoring, and incident response readiness.
OpsLevel integrates with tools like GitHub, Datadog, and PagerDuty to reflect real-time service state. It does not provision infrastructure or deploy applications, instead it ensures that services meet defined standards. The platform is used by engineering leadership to maintain consistency across teams without introducing heavy process overhead. It complements other IDP components that handle provisioning and deployment.
Deployment Model
SaaS.
Strengths
Excellent for service ownership and accountability. Integrates with PagerDuty, Jira, and CI/CD tools to build a complete picture of service health and team responsibility.
Weaknesses
Not a provisioning tool. This is about tracking and improving what you’ve already deployed, not deploying new services.
Best For
Orgs with mature microservice architectures where ownership and operational standards need enforcement.
Operational Notes
Minimal. Integration setup and ongoing metadata curation.
10. Mia-Platform

What It Is
Mia-Platform is an internal developer platform focused on building and managing microservices architectures with predefined templates and governance controls. It provides a developer portal where teams can create services using standardized templates that include runtime configuration, CI/CD pipelines, and deployment rules. The platform integrates with Kubernetes and API gateways, allowing teams to manage service exposure, routing, and dependencies in a structured way.
It also includes governance features such as service lifecycle management and policy enforcement. Mia-Platform emphasizes consistency across microservices, ensuring that new services follow the same patterns as existing ones. It acts as both a developer portal and an orchestration layer for microservice-based systems.
Deployment Model
SaaS or self-hosted, typically deployed on Kubernetes with integrations into CI/CD and API management systems.
Strengths
Strong focus on microservices standardization and governance. Templates reduce duplication in service creation and deployment workflows. Integrated API management simplifies service exposure and routing. Supports both developer self-service and platform-level control.
Weaknesses
Primarily designed for microservices architectures, less suitable for simpler or non-service-based systems. Requires alignment with its opinionated structure, which may not fit all teams. Can introduce overhead for smaller teams with fewer services.
Best For
Greenfield projects or teams willing to adopt Mia’s architectural opinions wholesale.
Operational Notes
Medium (self-hosted) to low (SaaS). More maintenance if you’re running the full stack yourself.
11. Upbound
What It Is
Upbound is a control plane platform built on Crossplane that allows teams to manage cloud infrastructure using Kubernetes APIs. It extends Kubernetes by enabling infrastructure resources such as databases, networks, and storage to be defined and managed as custom resources. Platform teams define compositions that map high-level abstractions to cloud provider resources, while developers interact with simplified APIs.
Upbound provides a managed control plane that handles provisioning, updates, and lifecycle management of infrastructure across clouds. It allows infrastructure and application workflows to be unified under the same Kubernetes-based model. The system focuses on treating infrastructure as part of the control plane rather than as external configuration.
Deployment Model
SaaS control plane with agents running in Kubernetes clusters, or self-hosted using Crossplane.
Strengths
Unifies infrastructure and application management under Kubernetes APIs. Supports multi-cloud environments with consistent abstractions. Compositions allow reusable infrastructure patterns across teams. Strong alignment with GitOps and declarative workflows.
Weaknesses
Requires deep understanding of Kubernetes and Crossplane concepts. Debugging infrastructure issues through custom resources can be complex. Not ideal for teams without Kubernetes maturity.
Best For
Cloud-native teams that want infrastructure-as-Kubernetes-resources and are willing to invest in Crossplane expertise.
Operational Notes
Medium. Managed control planes reduce overhead, but you’re still writing and maintaining compositions and provider configs.
How to Choose the Right IDP for Your Organisation
Start with your provisioning model, not your wishlist. If you’re Terraform-first, prioritize platforms that treat IaC as a core capability (Cycloid, Resourcely).
If you’re Kubernetes-native, look at Kratix, Humanitec, or Upbound. Next, evaluate operational cost. Can your team maintain a self-hosted platform, or do you need SaaS? Backstage gives you control but demands FTEs. Port and Cortex give you visibility with minimal overhead.
Finally, check extensibility; Will this platform grow with your needs, or will you outgrow it in 18 months? Open-source platforms (Backstage, Kratix) have an infinite ceiling but high cost. SaaS platforms have lower ceilings but faster time-to-value. There’s no universal winner. The right platform depends on your stack, team size, and where you are in platform maturity.
Conclusion
This comparison covered 11 production-grade internal developer platforms, evaluated on architecture, extensibility, provisioning capabilities, and operational overhead. Each platform makes different tradeoffs between control and convenience, open-source flexibility and SaaS simplicity, Kubernetes-native workflows and multi-cloud infrastructure management. Internal developer platforms succeed when they remove friction without removing control.
If you’re managing multi-cloud infrastructure and care about cost and compliance, Cycloid’s IaC-first model with built-in FinOps fits. If you need service catalog and plugin flexibility, Backstage is still the standard. If you’re Kubernetes-native and want infrastructure-as-code through K8s APIs, Upbound delivers. Pick the platform that aligns with how your team already works, not the one with the longest feature list. The best IDP is the one engineers actually use.
Frequently Asked Questions
1. Do I need an IDP if I already have CI/CD pipelines?
CI/CD deploys code; an IDP provisions infrastructure, manages environments, and exposes self-service workflows. They solve adjacent problems. Most teams need both.
2. Can I build an IDP instead of buying one?
Yes, but expect 2-4 FTEs minimum to build and maintain it. Most teams underestimate the operational cost of homegrown platforms. Maintenance compounds faster than features.
3. Is Backstage production-ready in 2026?
Yes, but with caveats. The plugin ecosystem is mature, but core API stability is still evolving. Budget engineering time for plugin maintenance and version upgrades.
4. What’s the difference between an IDP and a PaaS?
A PaaS (Heroku, Render) is opinionated and managed. An IDP is a framework for building self-service on your own infrastructure. You control the abstractions.
5. How long does IDP adoption take?
6-18 months depending on org size and existing tooling. Most teams underestimate change management; the technical integration is faster than getting engineers to use it.


