
TL;DR
- Data sovereignty is no longer just a legal concern, it is a core infrastructure requirement for 71% of enterprises. Teams must now engineer around a complex matrix of external laws (EU GDPR, Schrems II, HIPAA), certification standards (SOC2, ISO 27001), and high-stakes industry constraints (Finance, Healthcare, Defense).
- Sovereignty dictates where you can legally deploy. Effective residency controls allow the organization to enter regulated markets that require strict data boundaries. They also enforce internal “golden path” standards and restrict infrastructure spend to authorized regions, preventing accidental cross-border costs.
- Relying on manual security reviews and static documentation is the fastest way to kill developer velocity. We explore why the “Reactive Compliance” model fails and how shifting to Embedded Controls, where rules are baked into the platform, removes the friction between speed and safety.
- Governance must move from trust-based systems to executable logic. We cover how to implement checks that flag region or encryption violations at the commit stage, giving developers instant feedback before they break a rule.
- There is no one-size-fits-all topology. We analyze the trade-offs of Region-Isolated Stacks, Federated Control Planes, and Hybrid Trust Boundaries to help you choose the right design for your specific jurisdiction needs.
- Strict rules don’t have to mean slow delivery. We explain how unified platforms (like Cycloid) enable teams to bake in defaults, like region pinning and encryption, allowing developers to deploy confidently via self-service templates without waiting for approval.
Introduction
An industry report from Capgemini referencing IDC data from 2024 that 71 percent of enterprises now enforce data residency controls across more than three cloud regions, which shows how quickly jurisdiction-bound rules have become part of day-to-day engineering. Across r/devops, engineers frequently describe how compliance steps can slow delivery when each deployment triggers several approval tickets, especially in larger organisations with multi-region workloads.
The rise of residency, access, and audit obligations means sovereign data is no longer a narrow legal discussion; it actively shapes how engineering platforms are planned and operated.
This article explains how sovereign data influences platform strategy, development workflows, and infrastructure choices. It looks at how platform teams arrange governance across pipelines and runtime environments, where automation reduces manual audits, and how the right controls keep developers moving without breaking compliance expectations.
Architecting Infrastructure for Data Sovereignty and Residency
Sovereign data refers to information that must stay within boundaries set by a specific jurisdiction, with rules covering where it can be stored, who can access it, how it may be processed, and how evidence of compliance is recorded. For engineering specs teams, this translates into strict region scoping, encryption expectations, and controls that prevent cross-border transfers unless they are explicitly approved. These constraints shape everything from deployment patterns to data movement between services.
To enforce these boundaries, organizations often deploy distinct platform stacks for different jurisdictions. For example, a team using Cycloid might operate one isolated stack specifically for EU customers and a separate, disconnected stack for APAC. This physical separation ensures that management planes do not accidentally bridge regulatory zones. Infrastructure state, secrets, and deployment targets remain confined to their designated region, preventing a developer from accidentally deploying a GDPR-regulated database into a US-based cluster.
Legacy “global-by-default” environments allowed workloads to drift between regions, a model that fails under current regulations. Teams now require explicit region pinning and verifiable lineage. Cycloid addresses this by binding infrastructure state directly to the pipeline and committing history. It tracks exactly which stack version deployed a resource and where that resource lives. This creates a permanent, audit-ready record of data location and movement, ensuring that every change to the infrastructure is traceable back to a specific policy and region.
Before sovereignty rules became widespread, many organisations built global-by-default environments where workloads moved freely across regions. That model no longer works for regulated data sets. Teams now require explicit region pinning, clear lineage tracking, and predictable patterns for how information moves between internal and third-party systems.
Typical requirements include statements such as “All analytics workloads must remain within EU West,” “Logs older than 30 days must not leave the customer’s region,” and “Secrets must be encrypted with region-scoped keys.” These expectations influence architecture design as well as how developers interact with the platform.
To operationalise these strict residency boundaries, organisations typically gravitate toward one of two distinct governance strategies.
Governance Models: Reactive Compliance vs. Embedded Controls
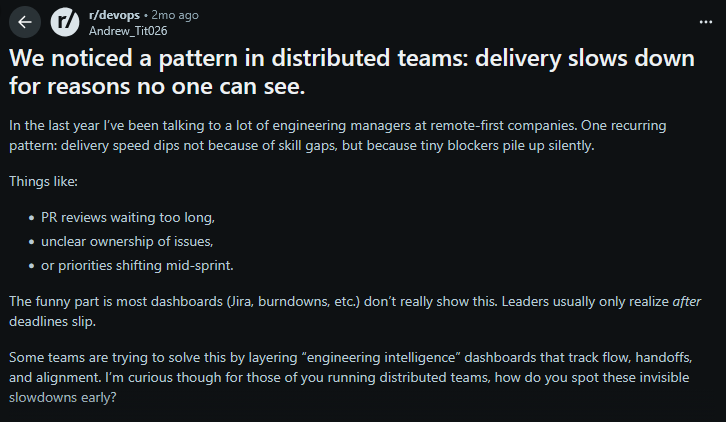
Teams usually encounter two governance patterns when dealing with sovereignty requirements. The reactive compliance model leans on ticket queues and manual reviews. A developer submits a deployment request, waits for a security or audit team to check jurisdiction rules, and only then receives approval. This process depends heavily on individuals interpreting the rules correctly. It also amplifies cycle time, increases the chance of inconsistent decisions, and creates uncertainty about whether the deployment will pass or be delayed.
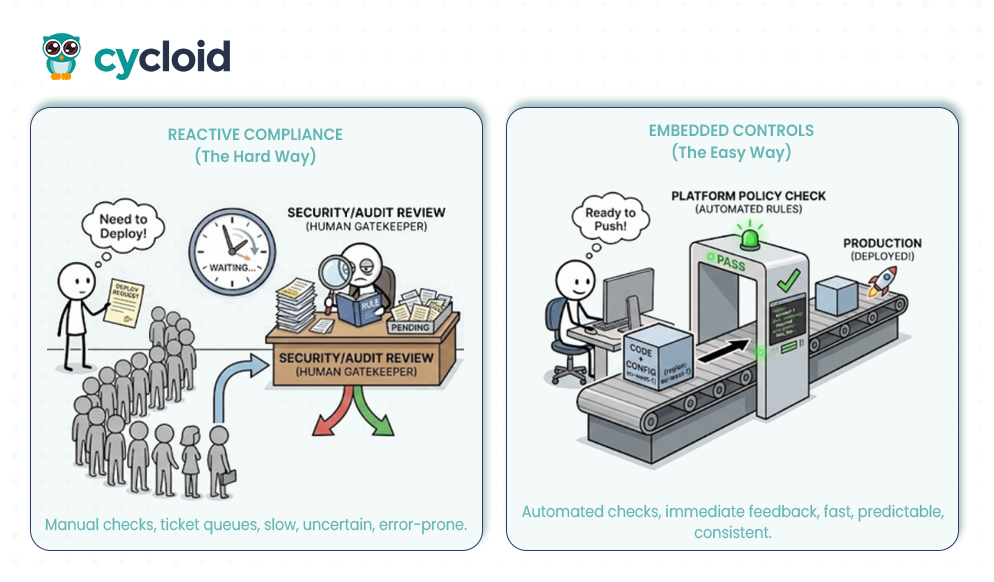
The embedded controls model integrates sovereignty constraints directly into the infrastructure definitions. Rather than focusing solely on access or encryption, this approach enforces jurisdictional boundaries at the configuration level. Infrastructure templates define rigid location parameters, and pipelines reject any configuration that attempts to provision resources outside designated legal zones. This ensures that governance is active; a developer cannot accidentally deploy a German customer database to a US region because the platform logic validates the destination before provisioning begins. This generates a continuous chain of custody for compliance auditors, proving that data physically resides in the correct location according to the governing law.
A simple template illustrates how residency constraints can be encoded directly in a self-service workflow:
| environment: region: eu-west-1 data_residency: required encryption: kms_key: eu-managed-key |
From a developer’s perspective, this approach eliminates surprises. They see exactly which values are enforced, which fields are mandatory, and which regions are valid before any workload is deployed. This results in clearer expectations and a smoother delivery path, especially in multi-region environments where small misconfigurations can break compliance rules.
The most robust mechanism for enforcing these guardrails is to shift governance from static documentation to executable logic that lives alongside your infrastructure.
Policy-as-Code for Data Sovereignty
Policy-as-code provides a structured way to express residency, access, and processing rules as executable logic instead of static guidelines. Engineering, security, and compliance teams store these rules in version control, review changes through pull requests, and let policy engines evaluate them during provisioning and pipeline execution. This removes the ambiguity that appears when rules live only in documents or spreadsheets.
A residency rule can be expressed with a simple Rego policy:
| deny[msg] { input.resource.region != “eu-west-1” input.resource.data_classification == “sensitive” msg := “Sensitive workloads must stay in EU West” } |
When a workload targets a non-approved region, the pipeline fails with a clear message. Developers receive feedback early, security teams receive reproducible evidence for audits, and platform teams gain a predictable enforcement layer that behaves the same way across all environments.
These checks usually run in three places:
- Provisioning stage: Validating infrastructure definitions before resources are created.
- Pipeline stage: Inspecting manifests, templates, and deployment plans during build and deployment steps.
- Runtime stage: Verifying environment drift, tag accuracy, retention rules, and access patterns.
With this model, teams reduce dependence on manual gatekeeping. Every rule is visible, trackable, and testable. As sovereignty requirements change, the updates happen in code rather than in unstructured documents, giving the platform a stable foundation for long-term compliance.
Once these logical guardrails are defined, the focus shifts to selecting an architectural topology that physically enforces these jurisdiction boundaries across the infrastructure.
Comparing Data Residency Patterns in Real Platform Setups
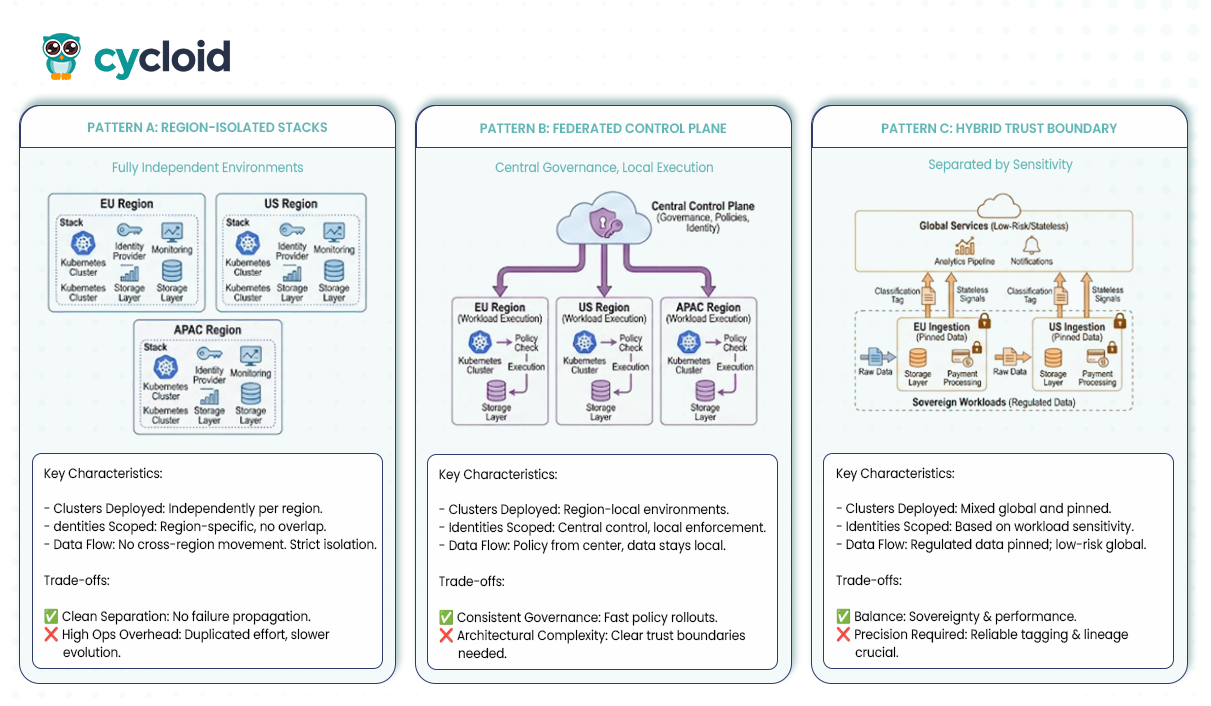
Engineering teams usually fall into one of three residency patterns when building platforms across multiple jurisdictions. The differences between them show up in how clusters are deployed, how identities are scoped, and how data flows between services.
Pattern A: Region-Isolated Stacks
In this model, each region operates as a fully independent environment with its own Kubernetes cluster, identity provider footprint, monitoring stack, and storage layer. Teams use this pattern when strict regulatory boundaries prevent any cross-region movement of sensitive workloads. The strength of this approach is clean separation: a failure or misconfiguration in one region cannot accidentally propagate into another.
The trade-off is operational overhead. Every improvement to pipelines, secrets management, or observability must be applied region by region. Real-world teams often compare this to “managing several mini-platforms instead of one,” which slows platform evolution. A common example is global SaaS providers serving European and Asia-Pacific customers from separate clusters, where audit bodies require no shared control plane.
Pattern B: Federated Control Plane
A federated approach keeps governance, policies, and identity in a central control plane, while actual workload execution happens in region-local environments. This pattern gives teams a consistent way to enforce residency, encryption, and access boundaries while allowing each region to run independently. It supports fast policy rollouts because updates to rules propagate from the central layer without requiring manual regional updates.
The trade-off is architectural complexity. Engineering teams must understand trust boundaries clearly: how tokens are issued, where policy decisions are evaluated, and how regional components validate those decisions. A familiar example is organisations using a central OPA (Open Policy Agent) bundle distribution service while running region-scoped Kubernetes clusters. Developers submit builds once, and policy evaluation happens before execution in any region. This gives teams consistent enforcement with less duplicated effort.
Pattern C: Hybrid Trust Boundary
The hybrid pattern separates workloads by sensitivity. Highly regulated or customer-identifiable data stays pinned to a specific region, while stateless or low-risk services run globally. This approach offers a balance between sovereignty requirements and performance needs. It is common for analytics or ML pipelines to run globally while raw customer data remains fixed at the ingestion region.
The trade-off is precision. The platform must reliably tag workloads, classify data paths, and maintain lineage so that sensitive components never depend on global services by accident. A practical example is payment systems: payment data is processed in-region, but auxiliary services like email notifications, dashboards, or monitoring run globally without holding regulated data. The platform enforces this split through classification tags, region constraints, and regular verification of data flow paths.
However, enforcing these strict architectural boundaries often disrupts the natural flow of engineering, creating a tension that directly impacts how quickly teams can ship software.
How Sovereign Data Impacts Developer Velocity
Sovereign data requirements often collide with the way developers ship software. They want short iteration loops and predictable deployments. Teams responsible for compliance need evidence, strict residency boundaries, and confidence that workloads stay within approved regions. The tension appears when these controls depend on manual review or tools spread across several systems.
Slow governance usually comes from four sources.
- Fragmented toolchains force developers to move between cloud consoles, security portals, and separate audit dashboards to confirm residency and classification rules.
- Inconsistent rules make it unclear which environments require additional checks.
- Unclear ownership leads to duplicated effort between development, security, and operations.
- Manually enforced data policies cause long review cycles because each deployment requires a one-off interpretation of the rules.
Many organisations are shifting toward patterns that reduce this friction. Unified platforms like Cycloid give developers a single place to validate region placement, encryption expectations, deployment history, and environment lineage. Embedded checks catch residency or classification mistakes early in the pipeline instead of late in the release process. Self-service infrastructure ensures new environments inherit residency and encryption defaults automatically. Instant policy feedback during commit, build, or deployment steps lets developers correct issues without filing tickets.
A typical self-service template for a sovereignty-aware workload looks like this:
| project: name: ml-service region: eu-west-1 data_classification: sensitive storage: type: s3 encryption: kms |
This pattern gives developers a clear starting point. The template encodes region boundaries, classification, and encryption rules directly into the provisioning workflow. On Cycloid, this style matches how stack templates and environment views are used: developers can create a project from a predefined stack, see which region it targets, view associated resources, and understand the residency implications without switching between several tools. The value is not in automation alone, but in reducing uncertainty. The platform carries the enforcement logic, and developers see the outcome before deploying anything.
To ensure these embedded controls are effectively balancing regulatory rigor with operational speed, platform teams validate their impact through a specific set of dual-purpose metrics.
How Platform Teams Measure Sovereignty and Velocity Together
Sovereignty controls only work if they support reliable delivery. Because of this, platform teams track both compliance outcomes and developer flow. A common metric is mean-time-to-approval, measured before and after policy-as-code is introduced. When manual reviews are replaced with automated residency and encryption checks, approval time usually becomes predictable and significantly lower. Teams also track audit accuracy rate, which reflects how often residency or classification rules are applied correctly across pipelines and infrastructure definitions.
Another metric is policy violation reductions. Once templates and pipeline checks embed region boundaries, the number of deployments failing late-stage compliance reviews drops. Platform teams also measure deployment throughput per developer, which shows whether sovereignty rules slow delivery or whether governance has been embedded in a way that supports rapid iteration. Finally, onboarding time for new services with residency requirements shows how accessible the platform is; long onboarding cycles typically indicate gaps in templates, guidance, or tooling.
These metrics reflect a shift-left model for governance. Instead of validating sovereignty at the end of a release, rules are checked during build, provisioning, and runtime stages. Developers receive immediate feedback and do not depend on a separate compliance queue. This approach supports accuracy and reduces operational load, especially as new regions, data classes, or retention expectations come into scope.
Implementation Guidance for Teams Starting Now
Teams building sovereignty-aware platforms usually begin with data classification and residency mapping. This provides a clear definition of which workloads fall under strict jurisdictional controls and which can run in global or multi-region setups. Without this mapping, platforms risk enforcing rules unevenly or blocking deployments unnecessarily.
The “Spreadsheet Trap” vs. Workflow Attributes
Most teams start by creating a static governance spreadsheet that says:
- PII → Must stay in EU
- Telemetry → Global allowed
- Logs → Restricted per retention window
However, none of this matters unless classification becomes an attribute in the development workflow. A spreadsheet cannot stop a developer from deploying a PII-heavy database to us-east-1. To fix this, classification must be treated as a configuration input, not a documentation footnote.
Step 1: Build Region-Bound Cycloid Stacks
The most effective enforcement mechanism is to abstract infrastructure into region-bound templates. These templates define region choices, encryption defaults, data paths, and access expectations.
- Hard-Coded Constraints: Cycloid Stacks should expose only residency-compliant regions based on the selected data class.
- Non-Editable Defaults: Critical security parameters, encryption settings (KMS keys, rotation policies), HSM boundaries, and backup behaviors, should be pre-configured and non-editable by the consuming developer.
- Predefined Paths: Templates must explicitly define valid IAM boundaries, networking zones, logging destinations, and any allowed cross-region flows.
Step 2: Enforce Classification at Scaffolding
Sovereignty begins at the first commit.
- Required Fields: Add data_classification as a mandatory field in Cycloid Stack templates.
- Pipeline Validation: Configure pipelines to validate this classification against the target infrastructure before Terraform applies. If a service is tagged data_classification: pii, the pipeline must reject any plan that targets non-sovereign regions or global storage buckets.
- Service Declaration: Require every new microservice to declare its data handling expectations during the initial scaffolding phase.
Step 3: Staged Rollout (Report then Enforce)
After templates are established, introduce policy-as-code with visibility before enforcement.
- Report-Only Mode: Pipelines surface residency or encryption violations as warnings without blocking deployments. This highlights where violations appear most often and identifies where templates need adjustment.
- Visibility: Use Cycloid’s project-level views to display pipeline results, environment regions, and infrastructure state in one place, so developers can see boundaries at a glance.
- Gradual Enforcement: Once the violation rate decreases, switch rules to enforce mode. Start by migrating high-sensitivity services first, then roll out blocking policies to lower-risk workloads.
Closing Takeaways
The shift from traditional governance to sovereignty-aware engineering platforms changes how teams think about enforcement, and developer flow. The table below outlines the contrast across the operational areas most affected by data residency requirements:
| Dimension | Traditional Governance | Sovereignty-Aware Platform Governance |
| Policy Enforcement | Manual, ticket-driven | Automated policy-as-code |
| Developer Flow | Slower, unclear rules | Faster, predictable rules |
| Data Residency | Checked after deployment | Checked on every commit |
| Visibility | Fragmented tools | Unified control plane |
| Compliance Evidence | Manual collection | Automatically generated |
A sovereignty-aware engineering platform depends on four things: accurate data classification, region-bound environment patterns, policy-as-code that evaluates every change, and a developer workflow that makes these controls visible early.
The patterns we explored; isolated stacks, federated control planes, and hybrid trust boundaries, show how different teams structure their environments to meet residency rules. We also covered how embedded checks, unified dashboards, and self-service templates reduce friction while keeping deployments predictable. When these elements work together, platform teams can meet jurisdiction requirements and maintain steady delivery across multiple regions.
FAQs
1. What is Sovereign Data Governance in an Engineering Platform?
Sovereign data governance refers to the controls that ensure data stays within the jurisdiction it belongs to, with rules covering residency, access, processing, and audit expectations. In an engineering platform, this includes region pinning, encrypted storage, identity boundaries, and automated checks across pipelines and runtime environments.
2. What Are the 4 Pillars of Data Governance?
Data governance pillars are the foundational components that support effective data management within an organization. They include data quality, data stewardship, data protection and compliance, and data management. Each pillar plays a vital role in ensuring the integrity, security, and usability of data.
3. What is the Difference Between Data Sovereignty and Data Governance?
Under the concept of data sovereignty, data that is generated or collected in a specific country is subject to the laws of that location. Data governance is a framework that organizations use to manage their data effectively and meet sovereignty requirements.
4. How Can Platform Teams Maintain Developer Velocity While Meeting Strict Compliance Rules?
Velocity improves when sovereignty checks run early in the workflow. Templates apply residency and encryption defaults automatically, and developers receive immediate feedback if a change violates governance rules. This removes ticket queues and late-stage manual review, which are the biggest sources of delay.


