
TL;DR
- A state file that spans more than one team’s resources is a shared blast radius. Error acquiring the state lock is the polite symptom; a flawed plan that gets approved and applied, touching 200 resources across teams who had no visibility into it, is the expensive one. When the state isn’t split by ownership, any team’s pipeline can detonate another team’s infrastructure.
- .terraform.lock.hcl locks provider versions, not module versions. A module sourced from ?ref=main on Monday and the same ref three weeks later can be entirely different code. Pinning to an exact commit SHA or version tag is the only way to make Terraform build deterministic end-to-end.
- Giving a CI runner AdministratorAccess “just to get it working” is one of the most durable lies in platform engineering. That over-permissioned role gets inherited by every team that picks up the pipeline. OIDC-based short-lived credentials scoped per workspace cost an afternoon to configure and eliminate the blast radius from a compromised CI credential entirely.
- Configuration drift triggers the impulse to automate reconciliation on a schedule, but over-automating the response is what slows teams down. An autoscaler that adjusted capacity overnight, or a cert that rotated automatically, looks identical to a manually added security group rule in a drift report. Teams that auto-remediate everything either break legitimate automated changes or spend two days a week debating which drift entries to suppress
Introduction: Why Terraform Automation Keeps Breaking After You’ve Already Built It
Two years in, your platform team has a working Terraform pipeline. terraform plan runs cleanly on pull requests, terraform apply fires on merge to main, state lives in S3, and the Makefile targets are, well, mostly self-explanatory to the people who wrote them.
Then someone from the application team asks for access to deploy their new service. Or a second cloud account gets added. Or the senior engineer who built the pipeline moves to a different team. Suddenly the automation that worked perfectly stops working. Not because Terraform changed, and not because anyone made a mistake, but because the automation was designed around one team’s mental model of how things should work, not around the reality of five teams sharing infrastructure.
The problem is that “Terraform automation” gets treated as a solved problem the moment terraform apply runs in CI. It isn’t. The full scope of Terraform automation covers state management, credential provisioning, policy enforcement at plan time, module versioning, configuration drift detection, and the human review checkpoints between a plan output and a production apply. Any definition narrower than that describes a component of the system, not the system itself.
This article covers exactly where that narrower model breaks under multi-team load, what the technical mechanics of each failure are, and what a structural fix looks like. There are five failure modes. Each one has a distinct signature, and each one has a different fix.
What Terraform Automation Is Actually Supposed to Cover
Before diagnosing what breaks, it’s worth being precise about what a complete Terraform automation system looks like versus what most teams actually ship.
A complete system handles; remote state with appropriate isolation, credential provisioning scoped to the workload, policy evaluation at plan time before anything touches infrastructure, a versioned module registry, scheduled drift detection with a named owner for reconciliation, and a legible contract between what a developer inputs and what Terraform executes.
What most teams ship is a CI pipeline that wraps terraform init, terraform plan, and terraform apply in sequence, stores state in a shared S3 bucket, uses one IAM role for everything, sources modules from a Git URL, and documents the inputs in a README that was last updated eighteen months ago.
The gap between those two descriptions is where the five failure modes live.
Failure Mode 1: State File Contention: The Global Queue Nobody Planned For
When multiple teams share a single Terraform backend, the state locking mechanism turns every deployment into a queue. Terraform’s S3 backend acquires a lock before modifying state and releases it when done, which is exactly the correct behaviour. The problem isn’t locking; it’s what happens to deployment throughput when three teams’ pipelines compete for the same lock.
The S3 backend previously relied on a DynamoDB table for locking, where Terraform would write a LockID entry before modifying state and delete it afterward. As of Terraform 1.10, S3-native state locking is available using conditional writes, which removes the DynamoDB dependency while preserving the serialisation behaviour. (Terraform S3 backend docs) The mechanic is the same either way: one apply at a time per backend.
When a second terraform apply hits the same backend, it waits. When it waits long enough, the CI pipeline times out and someone has to manually release the lock with terraform force-unlock. In multi-team setups with frequent deployments, this becomes a routine part of the week. It shouldn’t be.
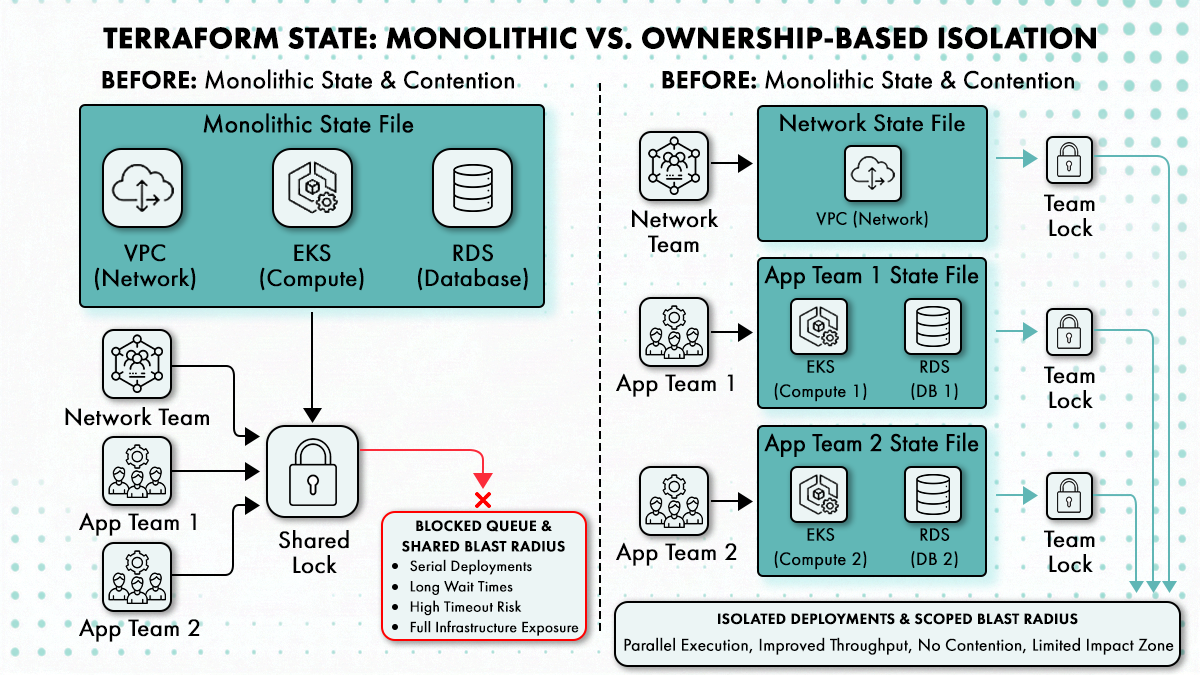
The second problem with shared monolithic state is blast radius. A state file that covers a VPC, three subnets, an EKS cluster, four RDS instances, and all associated security groups means that any engineer who runs terraform apply against it has the ability, whether they intend to or not, to touch all of those resources in a single run. A misconfigured plan won’t damage one subnet; it’ll affect the whole lot.
The fix is not adding more Terraform workspaces. terraform workspace creates isolated state per workspace within the same backend configuration, but if your VPC, networking, and application compute all live in one Terraform root module, switching workspaces doesn’t reduce the blast radius. It just gives you multiple copies of a monolithic state file.
State boundaries need to map to ownership. The network team owns the VPC and subnets; those live in a state file they control, stored in a backend they can access, with credentials scoped only to what they manage. The application team owns their compute; that state is separate. Cross-boundary references work via the terraform_remote_state data source, which reads outputs from another state file without granting write access to it.
The principle is: one team, one blast radius perimeter. Every team that owns infrastructure should own its state, and that state should be inaccessible to teams with no operational reason to modify it.
Failure Mode 2: CI Runner Permissions: The Blast Radius Tax on Inherited Pipelines
The fastest way to get a Terraform CI pipeline running is to give the CI runner AdministratorAccess and move on. Almost every team does this at some point. The reasoning is pragmatic: iterating on IAM permissions is genuinely tedious. Every Terraform provider minor version bump can introduce new API calls that break a tightly scoped policy. The path of least resistance is a permissive role, with a plan to tighten it later. Later doesn’t come.
The actual consequence arrives when a second team inherits the pipeline. They get the same IAM role the first team configured, which means they can provision (or accidentally destroy) anything the first team could. The credentials aren’t scoped to their workload. They’re scoped to whatever the first team needed, which was itself scoped to “whatever made the pipeline work.”
The static access key problem compounds this. An AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY stored as CI secrets are long-lived credentials that don’t expire, can be read by any engineer with access to the workflow logs (many CI systems output environment variables in certain failure modes), and require a manual rotation process that most teams set up but few actually follow. AWS’s own prescriptive guidance on Terraform security explicitly recommends replacing static credentials with OIDC-based short-lived tokens, and the reasoning is simple: a credential that expires after an hour has a window of compromise measured in minutes, not months.
The OIDC approach works by configuring AWS IAM to trust GitHub’s OIDC endpoint (or your CI provider’s equivalent). Each workflow run requests a short-lived JWT from the OIDC provider, presents it to AWS STS, and receives temporary credentials valid for the duration of the run. The trust policy on the IAM role specifies which repository and which branch are permitted to assume it, so a pipeline running from a fork or an unexpected branch can’t get credentials. The GitHub documentation on OIDC and the unfunco/oidc-github Terraform module both cover the IAM configuration in detail.
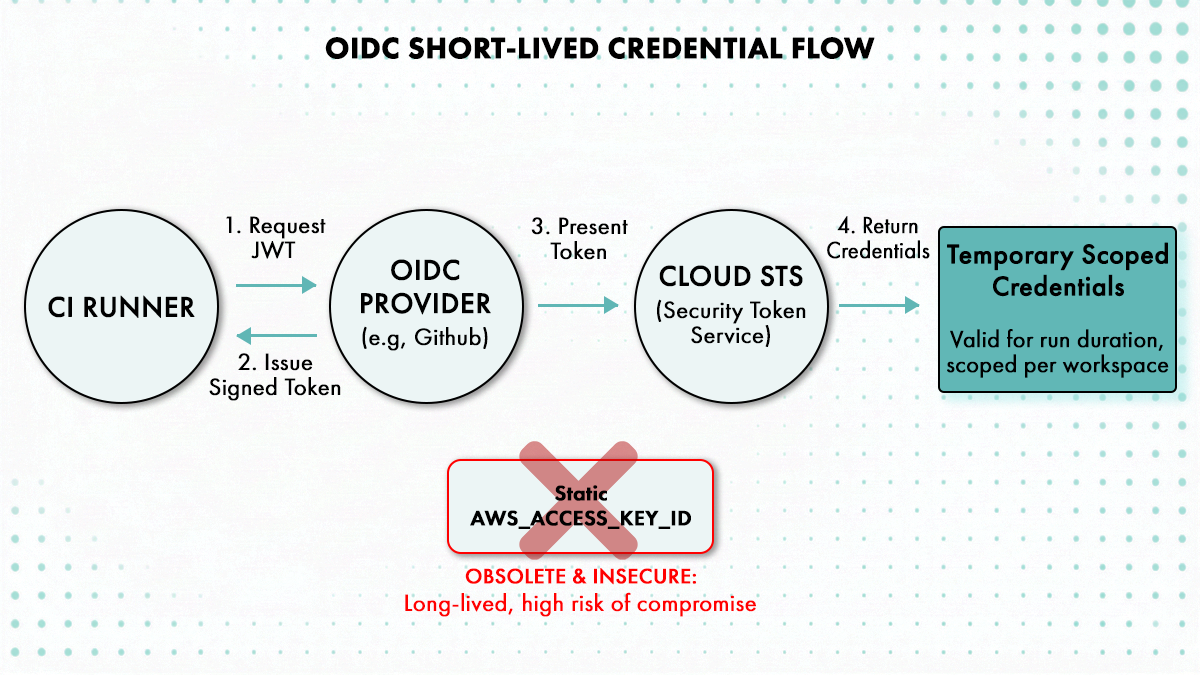
The finer point that most teams miss is that plan and apply don’t need the same permissions. A Terraform plan needs read access and the ability to call terraform show. An apply needs write access to the specific resources being modified. Separating them into two distinct IAM roles, both assumed via OIDC and both scoped to their respective workload, means that a plan phase that somehow executes untrusted code can’t modify anything. It also makes the permission scope of each phase auditable independently.
When combined with state boundaries mapped to team ownership, this model produces a system where each team’s CI pipeline can only touch the resources that team owns, using credentials that expire after the run, with a trust policy that rejects attempts to assume the role from anything outside the expected repository and branch.
Failure Mode 3: Module Version Drift: Determinism Breaks Quietly
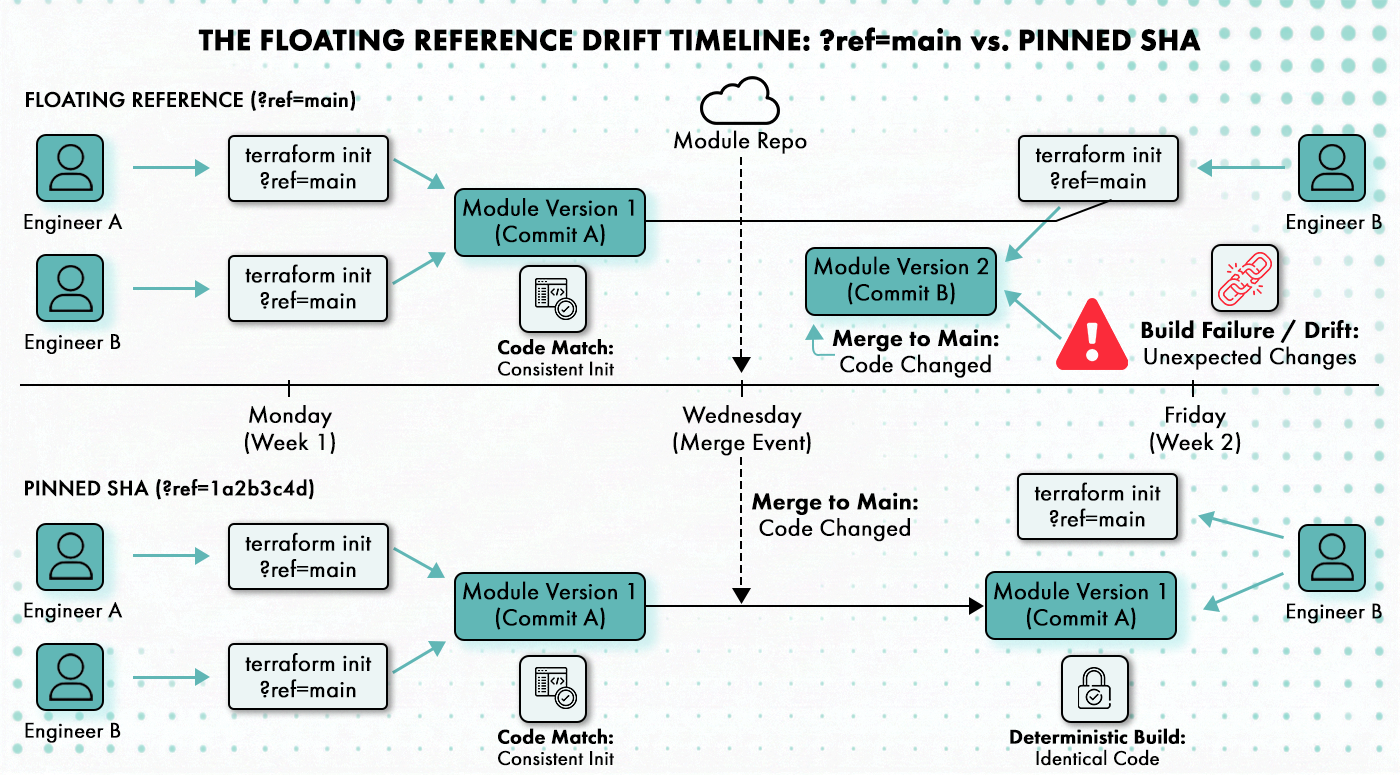
.terraform.lock.hcl locks provider versions; most engineers know this and treat it as Terraform’s answer to deterministic builds. What it doesn’t lock is module versions.
A module sourced from a Git reference like ?ref=main or ?ref=v1 resolves to whatever commit is at that ref when terraform init runs. Two engineers running terraform init against the same configuration three weeks apart can pull different module code if the ref has moved. They’ll get a clean init, a clean plan, and they may not notice the difference until something behaves unexpectedly in production.
The team fork problem is worse. Platform teams often maintain shared modules for common patterns: VPC creation, EKS cluster configuration, RDS setup. When Team A needs a tag that the module doesn’t support, they fork it into their own repository and add the tag. When Team B needs a CIDR calculation that the upstream doesn’t handle, they fork it and patch it. Six months later, there are four incompatible VPC module implementations in production, each maintained by whichever team forked it, none of which has kept pace with the upstream security patches or provider version requirements.
Reconciling four diverged forks of the same module costs more engineering time than the original wait for a review would have. The time pressure that drove the fork feels real in the moment. The total cost only becomes visible in retrospect.
Transitive module dependencies compound this. A root module that calls a networking module may pull in that module’s own dependencies, which are also sourced from floating refs. The lock file doesn’t track any of them.
The correct pattern is exact version pinning. ?ref=v1.4.2 or a specific commit SHA means the module is identical across every terraform init on every machine, regardless of when it runs. Pinning to a commit SHA is the most precise option; pinning to an annotated tag provides slightly less rigidity but is more legible to reviewers. Either is acceptable. Floating refs and branch names are not.
Pinning alone isn’t enforced; it’s a convention, and conventions erode under deadline pressure. What enforces it is a private module registry with an approved version list and a policy gate that rejects plans sourcing modules from unapproved refs. Terraform’s public registry supports versioned modules via semver. Private registries, whether run via Terraform Enterprise, an open source alternative, or a platform layer, can enforce the same constraint. Without a registry, you’re relying on engineers to pin correctly, review to catch them when they don’t, and hope that neither step fails at the same time.
Failure Mode 4: Configuration Drift: Out-of-Band Changes and the Reconciliation Nobody Owns
Terraform tracks what it deployed, not what currently exists. When an engineer adds a security group rule via the AWS console during a 2am incident, Terraform doesn’t know. When a runbook written before the Terraform migration adjusts an autoscaling group’s min/max, Terraform doesn’t know. When the next plan runs, it surfaces these differences as changes it would make to bring the infrastructure back in line with the declared state. Whether that’s the right thing to do depends entirely on context that Terraform can’t evaluate.
There are two meaningfully different categories of drift. Benign drift is changes made by AWS itself or by automation that Terraform doesn’t manage: autoscaler adjustments to capacity counts, CloudWatch alarms modifying cooldown periods, certificate rotation updating ARNs. Running a plan that reverts these is often harmless but sometimes wrong. Control-plane drift is a human making an out-of-band change to a resource that Terraform manages: a manually added ingress rule, a modified IAM policy attachment, a changed security group. This is the category that matters from a security and compliance perspective.
The problem with the “just run terraform plan” advice in multi-team environments is that nobody actually does it systematically. In a single-team setup, the person who runs the plan is also the person who understands what it says. In a multi-team setup, the plan runs against which workspace, how often, on whose authority, and who’s responsible for deciding whether the drift surfaces something that needs remediation or something that should be left alone?
Scheduled drift detection tools can answer the “runs against which workspace” question, but they produce reports. Reports need owners. Drift detection without a named owner and a documented remediation policy is a Slack notification that ages out of relevance.
The operational answer is to assign drift ownership at the workspace level: the team that owns the state file owns the scheduled drift check and owns the decision about what to do with the output. Benign drift gets documented as an exception. Control-plane drift gets remediated within a defined SLA. Teams that don’t have the capacity to own their own drift checks shouldn’t own their own Terraform workspaces yet.
Failure Mode 5: The Onboarding Cliff: When the Pipeline Author Leaves
The most expensive Terraform failure in terms of cumulative engineering hours isn’t a runaway apply. It’s the week that follows a senior engineer moving teams, when everyone who’s left discovers that the pipeline they’ve been trusting for eighteen months is much less legible than they assumed.
Makefile targets accumulate meaning over time that isn’t written down. make apply-prod might apply with auto-approval. make apply-staging might prompt for confirmation. Or the other way around, depending on which environment the team was most worried about when the target was written. CI step names like “Deploy infra” cover a range of possible behaviours. Shell wrappers that started as three lines and grew to sixty contain conditional logic that was obvious to the author and opaque to everyone else.
The new engineer inheriting the pipeline faces a choice: spend a week reverse-engineering what each step does, or run the thing and see what happens. Both paths carry risk. The first delays the work. The second can deploy to the wrong environment or skip a plan review that was supposed to gate the apply.
The organisational response is usually to add more review gates. PRs require two approvals instead of one. Every apply to production requires a manager sign-off. These additions slow delivery without fixing the underlying problem. A pipeline that nobody understands can’t be safely reviewed, because the reviewer doesn’t know what they’re reviewing. They’re approving a PR, not evaluating an infrastructure change.
What actually fixes the onboarding cliff is making the abstraction legible, meaning the contract between “what a developer fills in” and “what Terraform executes” is explicit, visible, and version-controlled, rather than embedded in shell wrappers and Makefile targets. Inputs and their effect on the resulting plan should be readable without tracing through multiple files. The sequence of plan, policy check, optional human approval, and apply should be visible as a structured workflow, not inferred from CI YAML.
The Platform Abstraction Fix: Structural, Not Another Wrapper
All five failure modes have a common root. The Terraform automation was built to solve one team’s operational problems, not to define a repeatable contract that survives team turnover, ownership changes, and scaling to additional cloud accounts.
Adding more shell scripts doesn’t fix this. A shell script that wraps the existing shell wrappers still encodes tribal knowledge. What fixes it is moving the automation to a layer that makes the contract explicit and enforceable, so that any engineer on any team can use the system without first acquiring the institutional memory that built it.
This is where Cycloid’s platform layer is worth understanding technically, because it addresses each failure mode directly rather than patching around it.
Stacks and StackForms: Making the Contract Legible
Cycloid Stacks are the organisational unit of versioned, approved infrastructure. A stack is a Git-backed template that describes infrastructure, services, or workflows using Terraform (and optionally Ansible or Helm), alongside a pipeline that runs it. The key design point is the separation between the stack branch, which contains the generic Terraform modules and pipeline definition, and the config branch, which contains the environment-specific parameters.
StackForms sits on top of this as the input layer. A .forms.yml file declares which variables a stack user needs to provide, what widget type each one uses (dropdown, text input, slider, inventory selector), what the valid values are, and which technology each variable feeds into. Cycloid reads the forms definition and generates a structured UI that maps directly to the Terraform variables, pipeline variables, or Ansible variables that will be used at execution time.
The practical effect is that a developer deploying a new environment fills in a form with labelled, validated inputs, and Cycloid writes the correct Terraform variable files and pipeline configuration into the config branch automatically. The developer doesn’t need to know which workspace maps to which account, which backend key to use, or how to format the input for the Terraform module call. The stack maintainer defines that contract once; every team that uses the stack works within it.
This directly addresses the onboarding cliff. The abstraction is visible (the form and its input descriptions), not tribal knowledge buried in a Makefile. Engineers who didn’t build the stack can use it without a handover session.
InfraPolicies: Enforcement at Plan Time
Cycloid’s InfraPolicies are a Terraform-plan-based implementation of Policy as Code using Open Policy Agent (OPA). Policies are written in Rego and evaluate the JSON output of a terraform plan before an apply runs.
The severity model covers three outcomes: advisory (a warning is sent but apply proceeds), warning (the user is notified and can override), and blocking (apply fails until the plan complies with policy). This means a platform team can write a policy that blocks applies containing security group rules opening port 22 to 0.0.0.0/0, requires approval before any resource destruction in a production workspace, or rejects plans that reference modules from floating Git refs. The policy runs in the pipeline before terraform apply, not in a post-incident review.
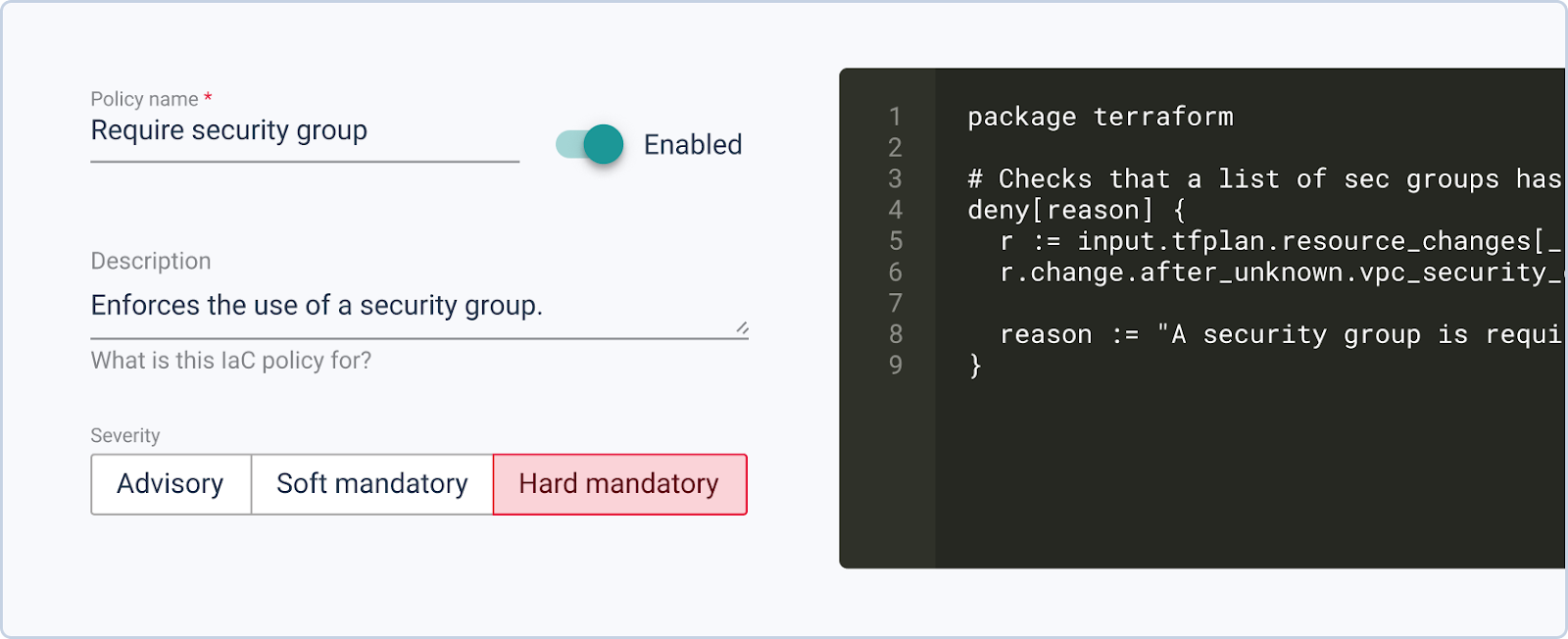
From the InfraPolicies library entry: policies are written in Rego and the severity level determines whether the pipeline blocks or warns. This makes policy enforcement a first-class part of the deployment pipeline, not a separate compliance process that trails behind what’s already in production.
This directly addresses both the module version drift problem (a policy that rejects plans using unapproved module sources runs before anything gets deployed) and the blast radius problem (a policy that limits the number of resources a single plan can destroy enforces the ownership model at execution time).
Infra Import: Getting Unmanaged Infrastructure Under Control
Teams inheriting a cloud environment that wasn’t built under Terraform face the bootstrapping problem. Manually writing Terraform to match what exists is tedious, error-prone, and hard to validate without running a plan against live infrastructure.
Cycloid’s Infra Import uses TerraCognita, an open-source CLI tool built by Cycloid, to generate Terraform code and state files from existing cloud resources on AWS, Azure, GCP, and VMware vSphere. Connect Infra Import to the cloud account, and it generates HCL and pushes the result to the catalog repository as a new Cycloid stack, ready to be managed through the pipeline.
One important note from the docs: Infra Import generates starting-point code, not production-ready code. The Cycloid documentation is explicit that DevOps teams should review and adapt the generated code before using it in production. It’s a way to get unmanaged infrastructure under Terraform management faster than a manual rewrite, not a substitute for engineering review. Given that caveat, it solves the hardest part of the bootstrapping problem: having something to iterate on, with the structure already in place to manage it via Cycloid’s pipeline and policy layers.

InfraView: State as a Diagram
InfraView reads Terraform state files directly from the configured S3 backend and generates a visual diagram of the infrastructure as-deployed, not as-declared. For multi-team environments where the declared configuration and the running infrastructure may have diverged, this provides a view of what’s actually there without requiring engineers to mentally parse a state file.
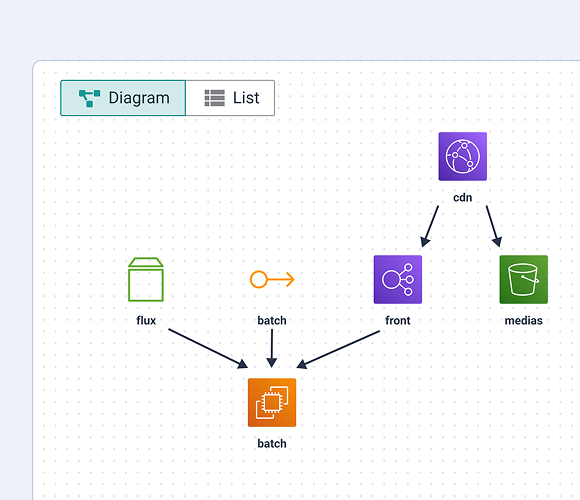
The diagram is generated from the tfstate file at a specific point in time. It won’t detect drift by itself; it represents the state as Terraform last recorded it. But for onboarding engineers or for teams inheriting infrastructure, having a visual representation of what the state file contains is considerably faster than reading raw JSON.
What Fixed Actually Looks Like
There are six concrete signals that Terraform automation has been built to work across team boundaries, not just for the team that built it.
Any engineer on any team can run a plan without contacting the engineer who built the pipeline. State boundaries map to team ownership, not just to environment names. CI uses short-lived OIDC credentials scoped per workspace, with separate IAM roles for plan and apply phases. Module versions are pinned to exact tags or commit SHAs and sourced from an approved registry. Drift detection runs on a defined schedule with a named team owning the remediation decision for each workspace. Policy checks run at plan time and block non-compliant applies before they reach production.
When all six are true, the automation works for the organisation rather than just for the people who built it. Until all six are true, there’s a failure mode waiting to be discovered, usually at the worst possible moment.
Conclusion
Terraform itself isn’t the problem; it does exactly what it promises, it describes infrastructure as code, tracks what it deployed, and applies the difference. The problem is that most Terraform automation was designed to solve one team’s deployment workflow and then inherited by an organisation that has five teams, three cloud accounts, and engineers who joined after the Makefile was written.
Each of the five failure modes covered in this article, state contention, over-permissioned CI runners, module version drift, unowned configuration drift, and the onboarding cliff, share the same root. The automation encodes a single team’s assumptions as implicit defaults rather than as an explicit, enforceable contract. When those assumptions stop being true, the automation breaks in ways that are hard to diagnose because the failure looks like a Terraform problem when it’s actually a design-scope problem.
The structural fix is moving Terraform automation to a layer that makes the contract between “what a team provides” and “what gets deployed” visible, versioned, and enforceable without requiring engineers to carry it in their heads. That’s what separates a working multi-team Terraform setup from a fragile single-team pipeline that everyone is scared to touch. Get the contract right, and the rest of the problems become manageable. Leave it implicit, and you’ll keep discovering the same five failure modes in rotation, usually at the worst possible time.
FAQ
1. When should you split a single Terraform state file into multiple states?
Split when two resources are owned by different teams, or when a change to one group should never be able to affect another. If the team responsible for a resource wouldn’t expect another team’s pipeline to touch it, it belongs in its own state file. terraform_remote_state handles cross-boundary output references cleanly
2. What’s the correct way to scope CI runner permissions per Terraform workspace?
Configure OIDC federation between your CI provider and AWS IAM, create a separate IAM role per workspace, and set the trust policy to allow assumption only from the specific repository and branch tied to that workspace. Attach only the permissions the resources in that workspace actually need. AWS’s prescriptive guidance on Terraform IAM best practices covers the trust policy structure in detail.
3. How should teams handle drift from resources Terraform doesn’t fully manage, such as autoscaling groups?
Classify before acting: autoscaling capacity changes are expected and should be documented as managed exceptions, not reverted. Out-of-band security group changes are control-plane drift and need remediation within a defined window. Write the classification into the workspace-level drift policy so engineers aren’t making judgment calls from scratch every time they read the report.
4. What does a module versioning policy look like in practice, and how do you enforce it in CI?
The policy is two things: a convention (pin to a specific version tag or SHA, never a branch name) and an enforcement gate that rejects plans sourcing modules from floating refs before terraform plan runs. The convention alone erodes under deadline pressure. The gate is what makes it hold. Without it, you’re relying on engineers to remember correctly every time, which they won’t.


