TL;DR
- La gouvernance échoue quand le Day 0 est traité comme un lancement plutôt qu’un événement générateur d’artefacts. Encoder dès le départ les frontières RBAC, la topologie réseau et les contraintes .forms.yml garantit que chaque environnement en aval hérite d’une base sécurisée qui ne peut être contournée.
- Les files de revue croissent linéairement avec les effectifs et finissent par s’effondrer sous le poids des tickets répétitifs. En encodant la politique directement dans les StackForms, on passe de « vérifier le travail » à « définir les frontières », permettant aux ingénieurs d’avancer à pleine vitesse sans avoir besoin d’un humain pour cliquer sur « Approuver ».
- La plupart des équipes sur-investissent dans le déploiement initial mais sous-traitent les années d’entropie qui suivent. Une plateforme n’est aussi solide que sa capacité à gouverner les actions post-provisionnement — montée en charge, correctifs, rotation des secrets — via les mêmes chemins GitOps utilisés au lancement.
- Les « hotfixes » manuels via la console créent un delta entre votre dépôt Git et la réalité, entraînant des défaillances en cascade lors de la prochaine exécution automatisée. La détection continue de la dérive est indispensable ; elle transforme la stack versionnée en vérité terrain vivante plutôt qu’en template figé.
- Les tableaux de bord de dépenses mensuels sont des post-mortems sur du capital gaspillé. Une vraie gouvernance requiert un FinOps opérationnel, où les plafonds budgétaires et les estimations d’empreinte carbone sont exposés dans le formulaire de provisionnement pour bloquer le sur-provisionnement avant que la ressource n’existe.
- La gouvernance ne devrait pas exiger une ardoise vierge ou une réécriture complète de l’infrastructure existante. Des outils comme InfraImport permettent de rétro-ingénier les ressources cloud existantes en Stacks versionnées, ramenant l’infrastructure non gérée sous le contrôle et la visibilité de la plateforme.
Ce que signifient réellement les opérations Day 0, Day 1 et Day 2 pour les équipes platform
Les équipes platform maîtrisent bien le Day 1. Les pipelines CI/CD sont construits, les modules Terraform écrits, le provisionnement automatisé. La vérité inconfortable est que le Day 1 est la partie facile — il est délimité dans le temps. Le Day 2 ne l’est pas, et l’investissement en gouvernance ne correspond presque jamais à la durée opérationnelle.
Gartner prévoit que d’ici 2026, 80 % des grandes organisations d’ingénierie logicielle auront constitué des équipes platform en tant que fournisseurs internes de services et d’outils réutilisables, contre 45 % en 2022. La pression de déployer rapidement ces plateformes crée un schéma où la gouvernance Day 2 est reportée jusqu’à ce que la douleur d’en être dépourvu soit suffisamment forte pour justifier l’investissement. À ce stade, il y a déjà de la dérive à corriger, des dépassements de coûts à expliquer et des lacunes de conformité à documenter. Selon l’enquête de Spacelift auprès de 413 décideurs en infrastructure, 45 % des organisations affirment avoir atteint des niveaux élevés d’automatisation, mais seulement 14 % démontrent les pratiques d’une excellence réelle en automatisation d’infrastructure. L’écart réside presque entièrement dans le Day 2.
Le modèle Day 0/1/2 ne fonctionne que si la gouvernance est continue sur les trois phases, pas appliquée au provisionnement puis silencieusement abandonnée. Cet article couvre ce que chaque phase possède réellement, où la gouvernance s’effondre entre les phases, et à quoi ressemble une plateforme conçue pour couvrir l’intégralité du cycle de vie — des définitions .forms.yml qui encodent la politique Day 0 aux mécanismes de détection de dérive et de gouvernance des coûts qui rendent le Day 2 gérable à l’échelle.
Ce qui appartient au Day 0, Day 1 et Day 2
Le Day 0 n’est pas une réunion de planification ; il produit des artefacts d’ingénierie : frontières RBAC, templates IaC, politiques de conformité, stratégie d’identité, décisions de topologie réseau et structures de dépôts de catalogue. Tout ce qui suit hérite de ces contraintes, ce qui rend leur erreur coûteuse. Modifier rétroactivement la segmentation VPC dans un environnement de production ou restructurer une hiérarchie de catalogue après l’import de dizaines de stacks sont le type de correctifs qui prennent des semaines et génèrent des incidents en chemin.
Le Day 1 est la fenêtre de déploiement initial. L’infrastructure est provisionnée, les services déployés, les pipelines CI/CD câblés. Les contraintes Day 0 doivent arriver ici intactes, encodées dans les templates et formulaires avec lesquels les ingénieurs interagissent lors du provisionnement.
Le Day 2 commence au moment où le premier changement post-déploiement est appliqué et dure jusqu’à la mise hors service de l’environnement. Il couvre la supervision, le patching, la rotation des secrets, les événements de montée en charge, les mises à jour de charts Helm, la gestion des coûts et le travail de nettoyage lié à la mise hors service propre des environnements. L’appeler une « phase » est généreux — c’est l’état par défaut de tout système en production et la seule phase sans date de fin définie. Une équipe qui investit massivement dans les jours 0 et 1, puis traite le Day 2 comme le problème de quelqu’un d’autre, passera la majorité de son temps opérationnel dans un état qu’elle n’a jamais conçu.
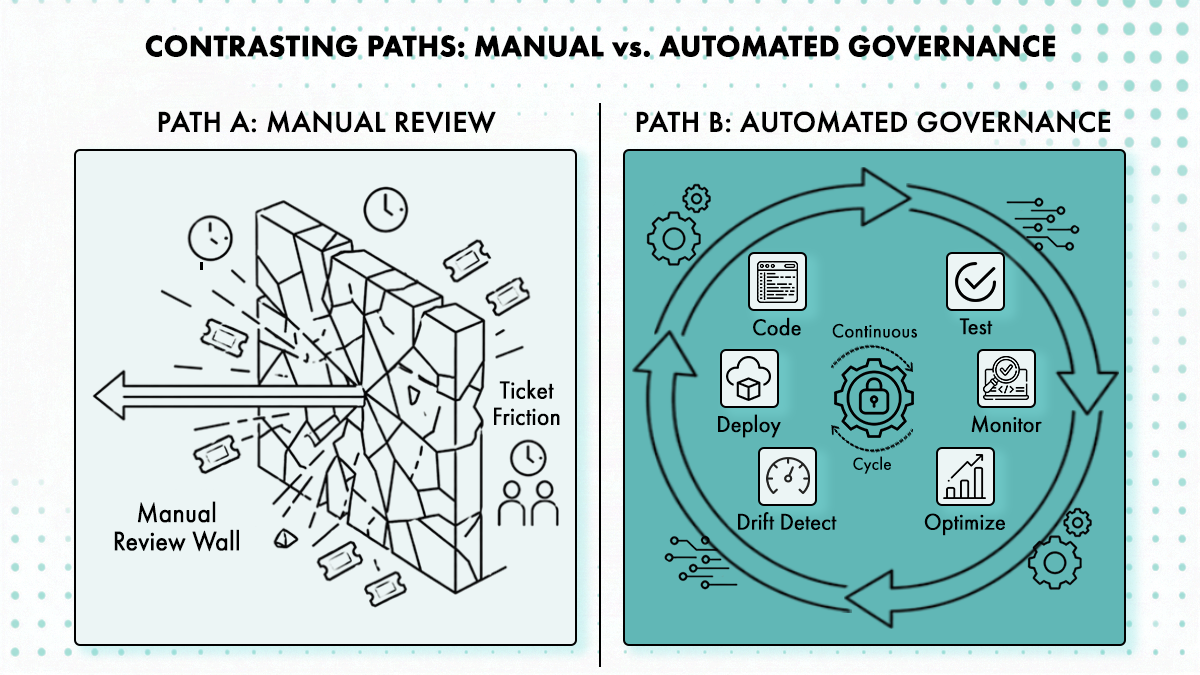
Pourquoi les files de revue manuelle s’effondrent à 100+ ingénieurs
Le schéma d’échec est cohérent : les équipes platform appliquent les standards à la création via des modules Terraform approuvés et des portes de pipeline, puis laissent les opérations Day 2 retomber dans les tickets. Monter en charge un environnement, faire pivoter un secret, mettre à jour un chart Helm ou décommissionner un service contourne les mêmes garde-fous qui régissaient le provisionnement initial.
Comme le documentent les recherches de Cycloid en platform engineering, la gouvernance qui dépend de la revue humaine évolue linéairement avec l’usage. À 100+ ingénieurs, les files de revue deviennent le goulot d’étranglement, pas les outils manquants. Une équipe data qui provisionne un nouvel entrepôt déclenche une revue d’ingénieur platform pour le placement réseau Terraform, une revue de sécurité pour les chemins d’accès aux données et un contrôle budgétaire pour la taille de l’entrepôt — tout cela séquentiellement, tout cela pour une demande structurellement identique aux vingt précédentes. Ajouter plus de réviseurs dans la boucle ne résout pas le problème structurel ; cela ne fait que retarder le moment où la file s’effondre.
Comment la dérive de configuration entre dans les environnements de production
Les modes de défaillance sont spécifiques et cumulatifs. La dérive de configuration entre par les modifications manuelles via la console effectuées pour débloquer des incidents — des modifications qui ne retournent jamais dans le contrôle de version. L’exposition aux coûts se construit depuis les ressources sur-provisionnées correctement dimensionnées au Day 1 mais jamais réévaluées à mesure que les schémas d’utilisation évoluent. Les lacunes de conformité émergent des politiques appliquées à la création mais pas à la mise à jour ni à la mise hors service. Un environnement qui a passé sa revue de sécurité initiale peut accumuler des mois de modifications non gouvernées avant que le prochain audit ne révèle le problème.
Le plancher opérationnel s’effondre quand les runbooks manuels sont le mécanisme de réponse principal au Day 2. Personne ne veut fouiller une page Notion à 2h du matin en cherchant la procédure de redémarrage d’un service qu’il n’a pas écrit.
Opérations Day 0 : RBAC, topologie réseau et décisions IaC avant le provisionnement
Le Day 0 est là où le modèle de gouvernance tient la route ou s’effondre silencieusement. Les décisions prises ici n’affectent pas seulement le premier déploiement — elles contraignent chaque environnement, chaque mise à jour et chaque événement de mise hors service sur la durée de vie de la plateforme.
Traiter les livrables Day 0 comme des artefacts d’ingénierie durables plutôt que comme des documents provisoires à réviser plus tard est ce qui distingue une plateforme qui vieillit bien d’une qui accumule une dette structurelle à un rythme prévisible.
Décisions Day 0 difficiles à modifier ultérieurement
Les décisions de topologie réseau et de segmentation VPC prises pendant le Day 0 sont coûteuses à modifier après déploiement. Isoler rétroactivement un niveau de données provisionné sur le même sous-réseau que les charges de travail applicatives n’est pas un changement de configuration — c’est une ré-architecture avec des implications d’indisponibilité. La stratégie d’identité et la conception du modèle RBAC ont le même poids. Un modèle RBAC construit autour de comptes de service trop larges ne peut pas facilement être durci après que des dizaines de charges de travail ont été déployées dessus. Le choix de la chaîne d’outils IaC entraîne des implications de lock-in qui façonnent l’automatisation Day 2 pendant des années ; les changements de chaîne en milieu de cycle signifient réécrire le modèle de gestion d’état pour chaque environnement existant.
Cycloid traite Git comme le store d’état autoritatif dès le Day 0, où les dépôts de catalogue, les définitions de Stacks et les fichiers de configuration sont versionnés avant qu’un environnement n’existe. Les dépôts de catalogue, les définitions de stacks et les configurations .cycloid.yml sont versionnés avant qu’un environnement n’existe. Les décisions prises en dehors de Git pendant le Day 0 créent un état non documenté que le Day 2 ne peut pas réconcilier — la détection de dérive nécessite un enregistrement canonique de l’état souhaité à comparer à l’état déployé réel. Sans lui, la plateforme n’a pas de baseline.
Comment .forms.yml applique la conformité au moment du provisionnement
Dans Cycloid, le fichier .forms.yml d’une Stack définit quels inputs sont exposés à l’ingénieur qui déploie, quelles valeurs sont bornées à une plage approuvée et quelles options sont entièrement verrouillées. Les décisions de conformité prises pendant le Day 0 déterminent ce que les opérateurs Day 1 et Day 2 peuvent faire — non pas via des documents de politique, mais via ce que l’interface permet littéralement.
StackForms lit la configuration .forms.yml et ne présente que des inputs bornés et approuvés. Un ingénieur provisionnant un entrepôt de données ne choisit pas la classe d’instance dans un champ texte libre — il choisit parmi un petit ensemble pré-approuvé. L’attachement réseau externe n’est pas un choix possible car l’option n’est pas exposée. Seuls les éléments définis dans .forms.yml sont remplaçables dans la configuration générée ; tout le reste reste fixé par la définition de la stack. Sous le capot, Terraform continue de tourner. La forme de ce que Terraform peut produire est simplement contrainte avant l’exécution.
Le compromis mérite d’être nommé clairement : sur-contraindre les inputs de stack pendant le Day 0 crée l’inflexibilité que les équipes contournent via l’accès console et des changements hors bande. Sous-les contraindre recrée la charge de revue que la plateforme était censée éliminer. Le bon calibrage est des inputs suffisamment bornés pour supprimer la revue manuelle du chemin standard mais suffisamment flexibles pour que les ingénieurs n’aient pas besoin de contourner le système pour faire un travail légitime.
Hiérarchie des catalogues et héritage RBAC dans les organisations enfants
Les décisions de structure organisationnelle sont des livrables Day 0 dans le modèle de Cycloid : quelles équipes partagent quelles stacks, quels dépôts de catalogue sont visibles par quelles organisations enfants, quelles credentials sont scopées à quels environnements. Les stacks partagées se propagent des organisations parentes aux organisations enfants, jamais l’inverse. Pour une gouvernance optimale, les stacks partagées doivent être définies au niveau de l’organisation racine pour garantir un accès standardisé et une maintenance rationalisée. Une hiérarchie de catalogue construite sans référence à la structure organisationnelle réelle signifie que des stacks finissent partagées avec des équipes qui n’y ont pas accès, ou isolées des équipes qui en ont besoin.
La visibilité par défaut des stacks hérite également du dépôt de catalogue au moment de l’import et ne peut être modifiée rétroactivement par lot — seulement stack par stack. Mal configurer la hiérarchie des catalogues au Day 0 signifie la ré-architecturer plus tard, une stack à la fois.
Provisionnement Day 1 : comment StackForms applique la politique Day 0 au déploiement
Un Day 1 gouverné diffère d’un Day 1 non gouverné d’une manière spécifique et mesurable : l’ingénieur qui déploie l’environnement ne peut pas faire des choix qui violent la politique Day 0 parce que ces choix ne lui sont pas disponibles. La gouvernance n’est pas une porte à la fin du workflow de provisionnement — elle est intégrée dans l’interface qu’il utilise.
Les mécanismes qui transportent les contraintes Day 0 jusqu’à l’environnement provisionné sont ce qui distingue un IDP d’une collection de modules Terraform enveloppés dans un formulaire web.
Comment StackForms lit .forms.yml pour contraindre les inputs Terraform
La relation mécanique entre le Day 0 et le Day 1 fonctionne ainsi : un StackForm lit le .forms.yml défini dans le dépôt de catalogue pendant le Day 0 et ne présente que des inputs bornés et approuvés à l’ingénieur qui déploie. Le Terraform sous-jacent s’exécute quand même, mais la forme de ce qu’il peut produire est contrainte avant que l’exécution commence. Les ingénieurs interagissent avec le formulaire — ils ne voient pas la sortie brute du plan Terraform et n’ont pas accès aux paramètres de configuration qui n’ont pas été délibérément exposés.
Les définitions de stacks et la configuration runtime sont réparties dans deux dépôts. Le dépôt de catalogue contient la définition de stack (.cycloid.yml, .forms.yml, modules Terraform/OpenTofu et pipelines). Le dépôt de configuration stocke les inputs utilisateur capturés via StackForms pour chaque environnement. Cette séparation impose une frontière entre les auteurs de plateforme et les consommateurs de plateforme.
Le pipeline déclenché par la soumission d’un StackForm tourne sur la couche CI/CD de Cycloid, construite sur Concourse et exécutée par des workers Cycloid (des workers Concourse configurés avec l’outillage Cycloid).
Les ingénieurs platform n’ont plus besoin de passer en revue chaque diff Terraform pour vérifier que quelqu’un a choisi le bon module, la bonne classe d’instance ou le bon attachement réseau. Ces choix ne sont tout simplement pas disponibles dès le départ. Les demandes de provisionnement standard cessent de générer du travail de revue parce que la plateforme a déjà pris les décisions contestées.
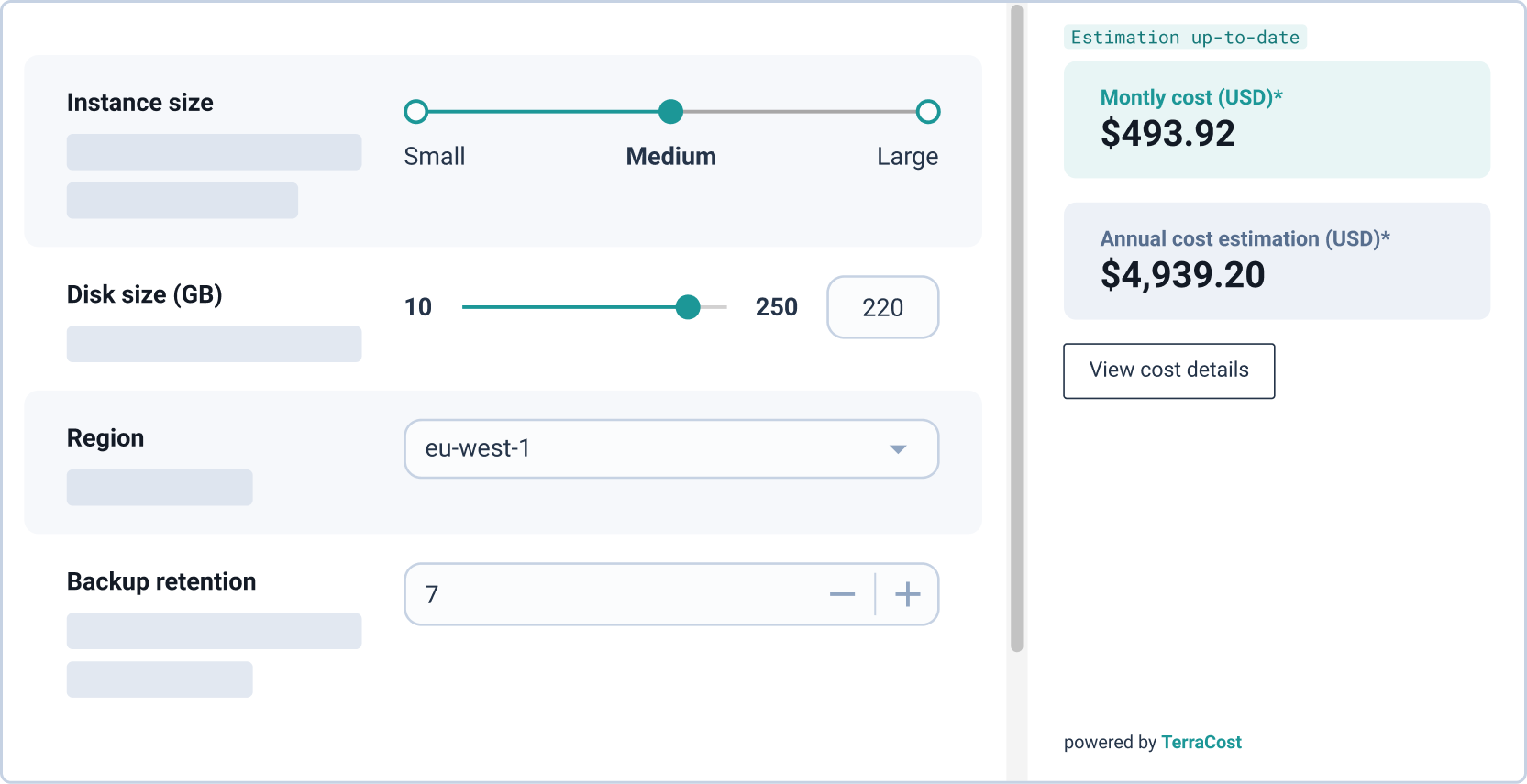
Les StackForms de Cycloid s’intègrent également avec TerraCost pour afficher une estimation de coût d’infrastructure en direct avant que l’ingénieur ne valide la configuration. Cette estimation est visible au moment du provisionnement, et la configuration finale est écrite automatiquement dans le dépôt de configuration Git. La visibilité des coûts au Day 1 prévient le problème Day 2 de découvrir des environnements sur-provisionnés des semaines après le déploiement quand la revue FinOps rattrape enfin.
Pourquoi les configs StackForm sauvegardées dans Git sont la source de vérité pour la détection de dérive
Chaque configuration StackForm sauvegarde automatiquement les inputs utilisateur dans le dépôt de configuration. L’état déployé dispose d’un historique Git traçable dès le moment de la création de l’environnement. La détection de dérive au Day 2 nécessite une vérité terrain à comparer à l’état réel de l’infrastructure — l’enregistrement de commit Git est cette vérité terrain.
Les équipes qui provisionnent en dehors du modèle gouverné (modifications manuelles via la console, terraform apply direct sans pipeline, commandes kubectl ad hoc en production) créent des environnements que l’outillage Day 2 ne peut pas réconcilier. Il n’y a pas d’enregistrement autoritatif de l’état souhaité, donc la détection de dérive n’a rien à mesurer. L’environnement existe, mais du point de vue de la plateforme, sa configuration est un mystère.
Évaluation des politiques avant apply : bloquer les violations avant terraform apply
Cycloid applique la gouvernance à deux points distincts, qui servent des objectifs différents. La première couche est .forms.yml, qui contraint les inputs au moment du rendu du formulaire. Les ingénieurs ne peuvent pas sélectionner des valeurs hors des plages prédéfinies parce que ces options ne sont jamais exposées dans l’interface. C’est une application au niveau des inputs, pas une évaluation de politique.
La deuxième couche est InfraPolicies, écrites en Rego (le langage de politique d’Open Policy Agent) et évaluées contre la sortie du plan Terraform ou OpenTofu avant l’apply. Ces politiques opèrent sur le graphe d’infrastructure entièrement résolu, pas sur l’input utilisateur. Chaque politique est assignée un niveau de sévérité : Advisory, Soft Mandatory ou Hard Mandatory, suivant le même modèle d’application qu’HashiCorp Sentinel. Cette distinction est importante car elle sépare la validation des inputs de l’application policy-as-code au stade du plan.
Opérations Day 2 : détection de dérive, gouvernance des coûts et gestion du cycle de vie
Le Day 2 est la phase la plus longue de loin, et celle où la dette de gouvernance accumulée lors des jours 0 et 1 devient visible opérationnellement. Chaque raccourci pris pendant la conception Day 0 et chaque contournement manuel accepté pendant le provisionnement Day 1 se manifeste ici — sous forme de dérive, de coûts inexpliqués, d’un environnement qui se comporte différemment de ce que sa définition de stack indique.
Le périmètre du Day 2 est large : supervision, patching, montée en charge, gestion de la dérive de configuration, rotation des secrets, mises à jour d’environnement, optimisation des coûts et mise hors service. Le défi n’est pas de définir ce que le Day 2 inclut. C’est de s’assurer que le même modèle de gouvernance qui s’appliquait au provisionnement s’applique encore à chacune de ces activités.
Comment la détection de dérive réconcilie l’état déployé avec les définitions de Stack
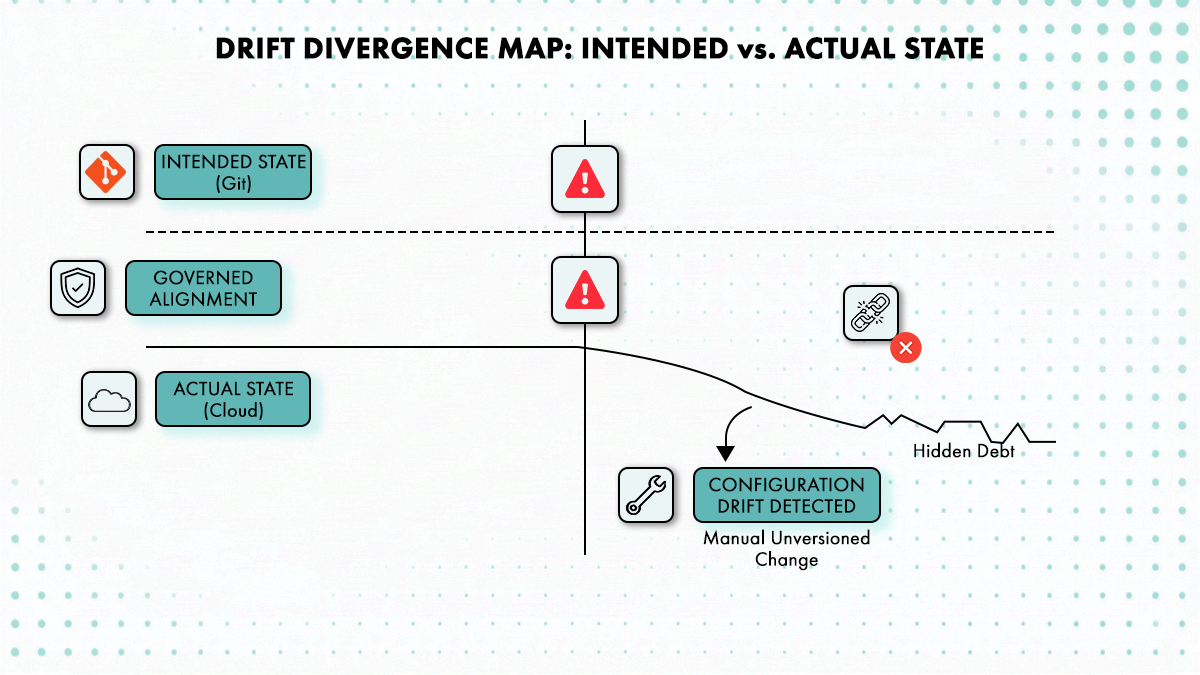
Cycloid ne fait pas tourner une boucle de réconciliation continue comme les contrôleurs natifs Kubernetes tels que Flux ou Argo CD. La dérive est plutôt remontée lors de l’exécution du plan Terraform ou OpenTofu. InfraPolicies évalue l’état planifié par rapport aux contraintes attendues, et les écarts causés par des modifications manuelles apparaissent comme des différences de plan. La détection de dérive est donc liée aux événements d’exécution plutôt qu’à une réconciliation continue. La plateforme repose sur une évaluation au moment du plan plutôt que sur un modèle de contrôleur toujours actif — ce qui représente un compromis opérationnel différent.
La détection de dérive de Cycloid alerte quand l’infrastructure déployée diverge de la configuration de stack versionnée, donnant aux équipes platform l’opportunité de réaligner les états avant que la divergence ne se transforme en constat de conformité ou en incident.
Kubernetes amplifie considérablement la complexité Day 2. Un HorizontalPodAutoscaler mal configuré peut provoquer des défaillances en cascade sous charge. Les mises à jour de cluster, la rotation des certificats et la maintenance des politiques RBAC nécessitent une attention continue. Un seul HPA mal configuré peut déclencher des chaînes de défaillance entre services difficiles à retracer a posteriori. La gouvernance Day 2 pour Kubernetes signifie une réconciliation continue de l’état du cluster par rapport à la politique définie, pas des audits périodiques post-incident.
Gouverner la montée en charge Day 2, les mises à jour Helm et la mise hors service via les pipelines
La lacune de gouvernance que la plupart des implémentations IDP laissent ouverte est visible dans le cycle de vie post-provisionnement. Le libre-service gouverné s’arrête à la création. Monter en charge un environnement retombe dans un ticket. Mettre à jour un chart Helm se gère avec une commande helm upgrade directe depuis une machine locale. Décommissionner un service devient une série non documentée de suppressions manuelles dans trois consoles cloud.
Cycloid s’intègre avec HashiCorp Vault pour la gestion des credentials, qui sous-tend les workflows de rotation des secrets décrits dans les opérations Day 2. Les mises à jour suivent des workflows de pipeline définis. La mise hors service applique la vérification de propriété et les règles de nettoyage avant la suppression des ressources. La gouvernance reste cohérente sur l’ensemble du cycle de vie, pas seulement à la création. Quand les opérations Day 2 sont traitées comme des actions platform de première classe plutôt que comme du travail hors bande, la gouvernance reste appliquée sans ajouter de nouvelles boucles de revue.
Estimation des coûts avant déploiement avec TerraCost (et suivi carbone GreenOps)
Le FinOps d’observation et le FinOps opérationnel sont deux disciplines différentes avec des résultats différents. Un tableau de bord montrant ce qui a été dépensé le mois dernier vous indique ce qui s’est passé. Des plafonds budgétaires attachés à chaque environnement empêchent le sur-provisionnement de se produire en premier lieu.
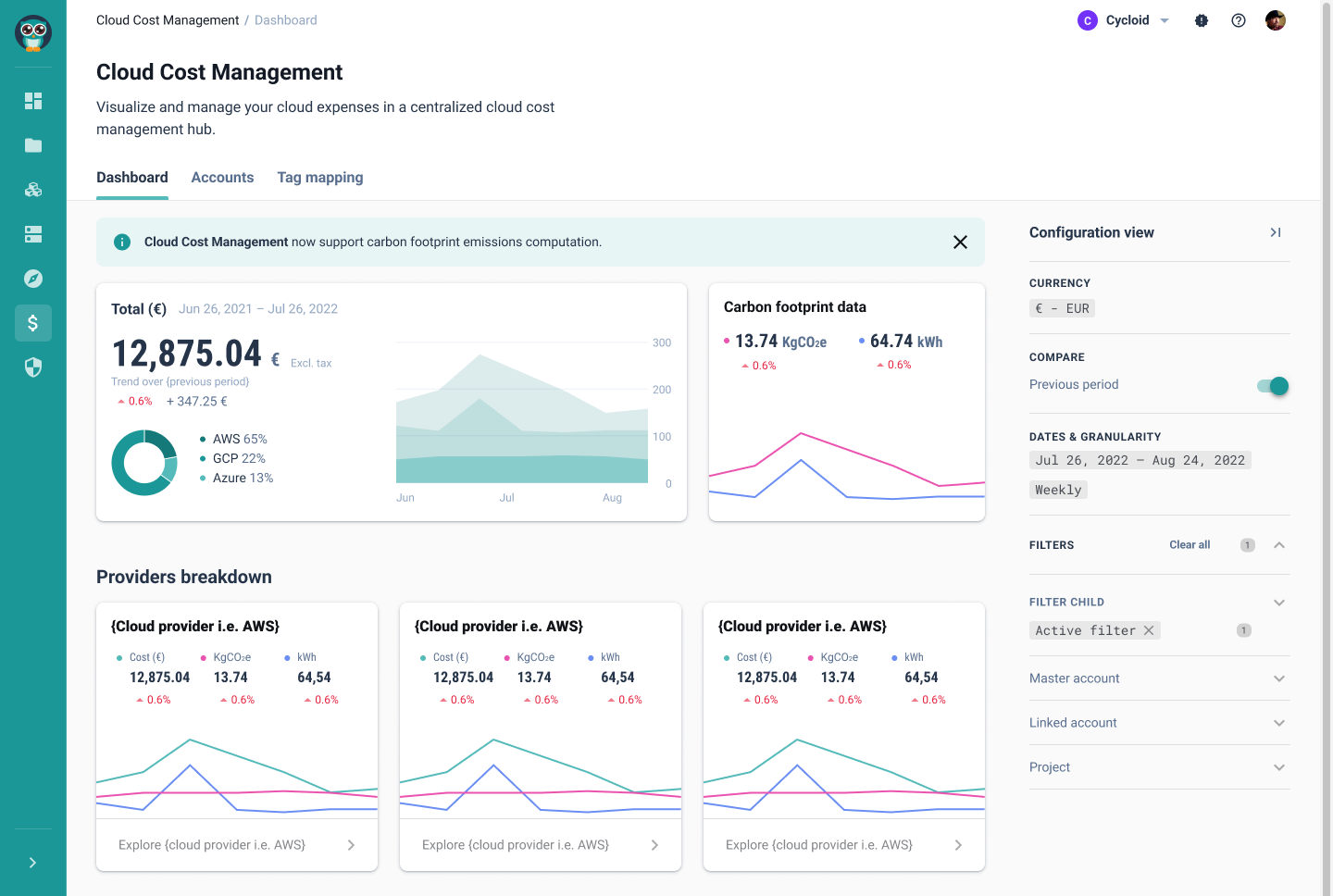
Le module GreenOps de Cycloid s’appuie sur le projet open-source Cloud Carbon Footprint, intégré dans sa couche de gestion des coûts cloud FinOps. Les estimations carbone sont dérivées parallèlement aux données de coût, en utilisant les mêmes inputs d’infrastructure. Les ingénieurs voient le coût estimé généré depuis le plan Terraform ou OpenTofu avant l’apply. TerraCost analyse le JSON du plan et produit une estimation de coût au même stade où InfraPolicies est évalué. Les plafonds budgétaires empêchent la création de ressources hors des plages de coût approuvées, plutôt que de les signaler pour remédiation après que la dépense a déjà eu lieu.
L’implication GreenOps suit directement : le calcul sur-provisionné génère des émissions carbone sur-provisionnées. Cycloid suit les données d’empreinte carbone filtrées par projet, région, date et fournisseur depuis le même module qui gère les données de coût. Le coût environnemental des décisions d’infrastructure est exposé au même point de décision que le coût financier — au moment du provisionnement, avant que l’environnement n’existe.
L’outillage plateforme qui couvre les trois phases : Stacks, StackForms, Asset Inventory et InfraView ensemble
L’Asset Inventory de Cycloid n’est pas une liste passive de ressources. Il est alimenté via le backend HTTP Terraform de Cycloid, où l’état Terraform ou OpenTofu est stocké via un token JWT (inventory_jwt). Les ressources flux dans l’inventaire directement depuis l’état, en faisant l’enregistrement autoritatif de l’infrastructure gérée. Cycloid expose également un CLI (cycloid-cli) et un provider Terraform (cycloidio/cycloid), permettant aux équipes platform de gérer les ressources Cycloid de façon programmatique.
Cet inventaire est également exposé aux StackForms via le widget cy_inventory_resource, permettant aux ingénieurs de référencer des ressources existantes comme des VPCs lors du provisionnement de nouveaux environnements. C’est ainsi que l’état Day 2 devient un input réutilisable pour les workflows Day 1.
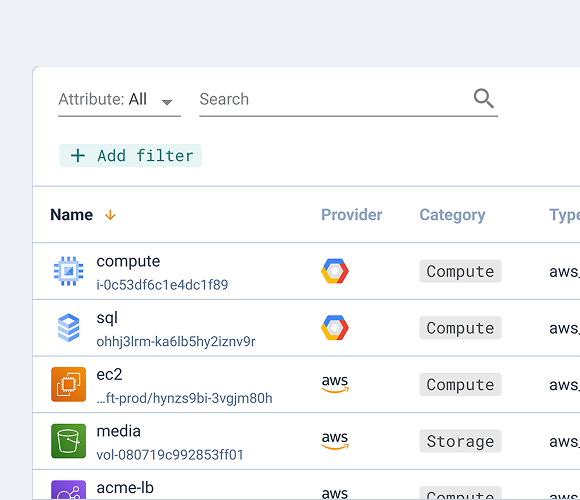
InfraView s’appuie sur cela en lisant directement le fichier .tfstate pour restituer les relations d’infrastructure. Il ne consulte pas les APIs des fournisseurs cloud, ce qui signifie qu’il ne reflète que ce qui est géré via Terraform ou OpenTofu. Les ressources créées en dehors de la plateforme n’apparaissent pas — contrainte intentionnelle liée à la visibilité basée sur l’état.
Cycle de vie d’une Stack : définition dans le catalogue → provisionnement → mises à jour Day 2
Le cycle de vie d’une Stack Cycloid se déroule ainsi : définie pendant le Day 0 dans un dépôt de catalogue avec un .forms.yml qui encode les inputs approuvés, consommée pendant le provisionnement Day 1 via StackForms, et référencée pendant le Day 2 pour les mises à jour, la réconciliation de dérive et la mise hors service. Contrairement à un fichier de configuration YAML générique, .forms.yml définit le contrat côté utilisateur de la stack — quels inputs sont exposés, comment ils sont validés et quelles valeurs sont contraintes avant que Terraform ne tourne. Une Stack n’est pas qu’un template de provisionnement. C’est la description canonique de l’état souhaité sur l’ensemble du cycle de vie. Quand un environnement dérive, c’est par rapport à la définition de la Stack qu’il a dévié.
Un exemple minimal de .yml ressemble à ceci :
| version: « 1 » use_cases: – name: « deploy » sections: – name: « Compute » groups: – name: « Instance configuration » fields: – name: « instance_type » label: « Instance Type » type: « select » values: – « t3.medium » – « t3.large » default: « t3.medium » required: true – name: « disk_size » label: « Disk Size (GB) » type: « number » min: 20 max: 200 default: 50 |
Cette structure diffère des variables Terraform ou d’une configuration YAML standard de deux façons. Le fichier ne décrit pas l’infrastructure — il définit ce qu’un ingénieur est autorisé à choisir lorsqu’il demande de l’infrastructure. Des champs comme values, min et max appliquent des frontières au moment de la saisie, pas lors du plan ou de l’apply.
Le résultat est que .forms.yml agit comme une couche de contrôle devant Terraform. Au lieu de revoir un plan pour repérer un type d’instance invalide ou un disque surdimensionné, ces options ne sont jamais exposées en premier lieu. Cette distinction est ce qui permet au provisionnement Day 1 de fonctionner sans revue manuelle tout en appliquant la politique Day 0.
Les stacks partagées définies au niveau de l’organisation racine se propagent aux organisations enfants. Une modification de politique apportée à une stack partagée au niveau racine se propage à chaque environnement Day 2 qui l’utilise — ce qui signifie qu’une mise à jour de gouvernance effectuée lors d’une revue Day 0 périodique s’applique rétroactivement aux environnements en cours d’exécution au prochain cycle de mise à jour, sans nécessiter de correctifs individuels par environnement.
InfraView pour la propriété des ressources Day 2, la dérive et la visibilité des coûts
L’ Asset Inventory de Cycloid maintient la visibilité sur toutes les ressources d’infrastructure déployées, liées à la Stack qui les a provisionnées. Les ingénieurs peuvent voir ce qui existe, qui en est propriétaire et à quelle version de Stack cela correspond — sans nécessiter d’accès direct à la console cloud. L’accès direct à la console est lui-même un risque de dérive — chaque ingénieur avec accès console est un ingénieur qui peut faire des modifications qui contournent le modèle de gouvernance.
InfraView expose la propriété, la dérive et l’impact sur les coûts dans les environnements dans une vue unique. Les équipes platform l’utilisent pendant le Day 2 pour identifier les environnements qui ont divergé de leur définition de stack, confirmer la propriété avant la mise hors service et valider que les plafonds budgétaires sont respectés dans l’ensemble du parc.
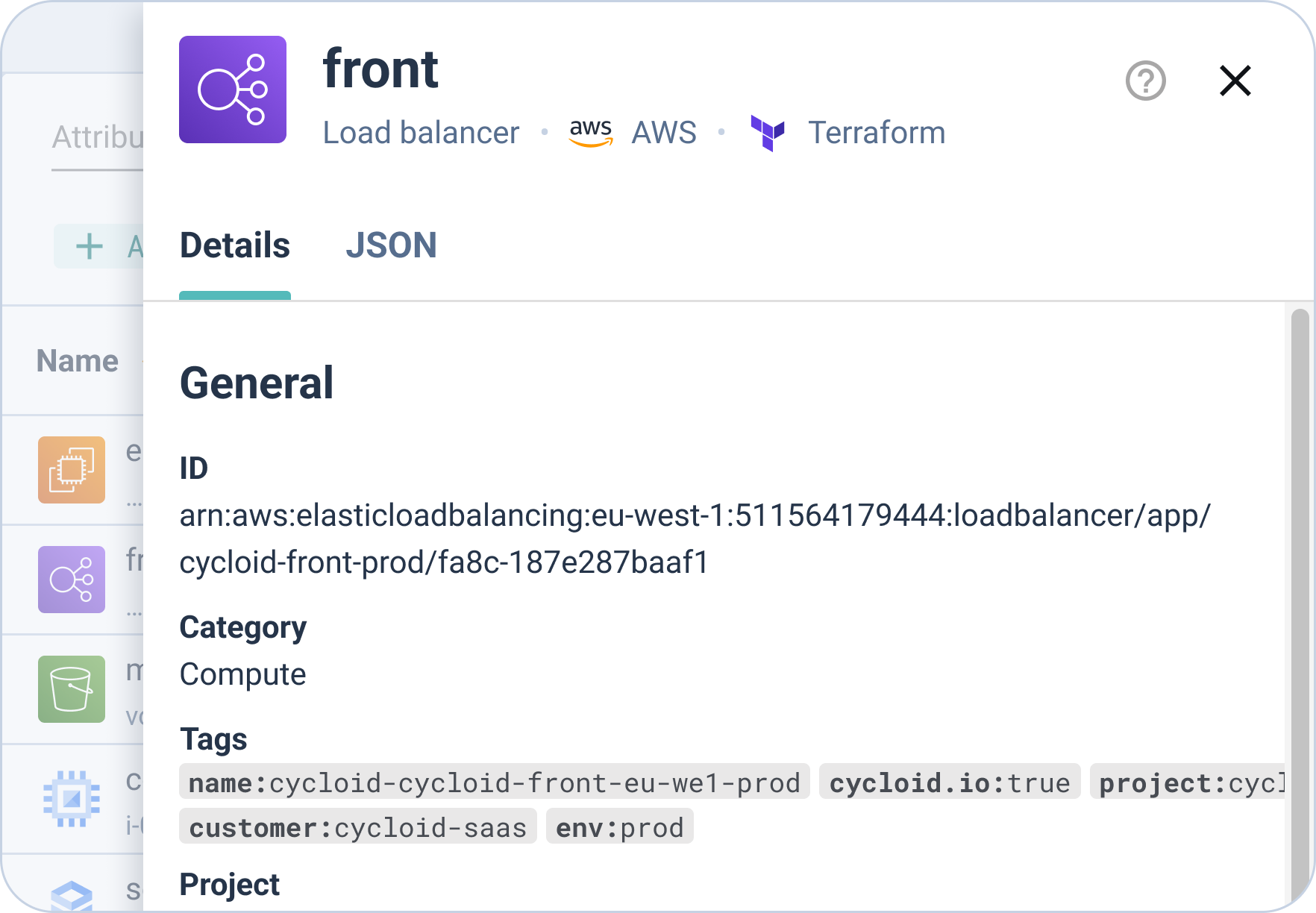
En pratique : un SRE d’astreinte peut retracer un environnement défaillant jusqu’à sa version de Stack, son commit dans le dépôt de configuration et sa configuration StackForm sans ouvrir la console du fournisseur cloud. L’investigation commence dans la plateforme, pas avec une série d’appels API ad hoc.
Les pipelines CI/CD comme couche d’exécution pour l’automatisation Day 2
La couche pipeline de Cycloid tourne sur Concourse, avec des pipelines exécutés par des workers Cycloid. Le même runtime exécute à la fois le provisionnement Day 1 et les actions du cycle de vie Day 2 — ce qui maintient la cohérence de l’application sur tout le cycle de vie. Les pipelines CI/CD managés de Cycloid servent de couche d’exécution pour l’automatisation Day 2 : mises à jour de charts Helm, rotations de secrets, correctifs d’environnement et actions de récupération codifiées dans des runbooks. Ces pipelines sont versionnés, réutilisables entre stacks et modulaires. Les opérations Day 2 qui nécessitaient auparavant une intervention manuelle peuvent être codifiées et déclenchées via le même modèle libre-service utilisé pour le provisionnement Day 1.
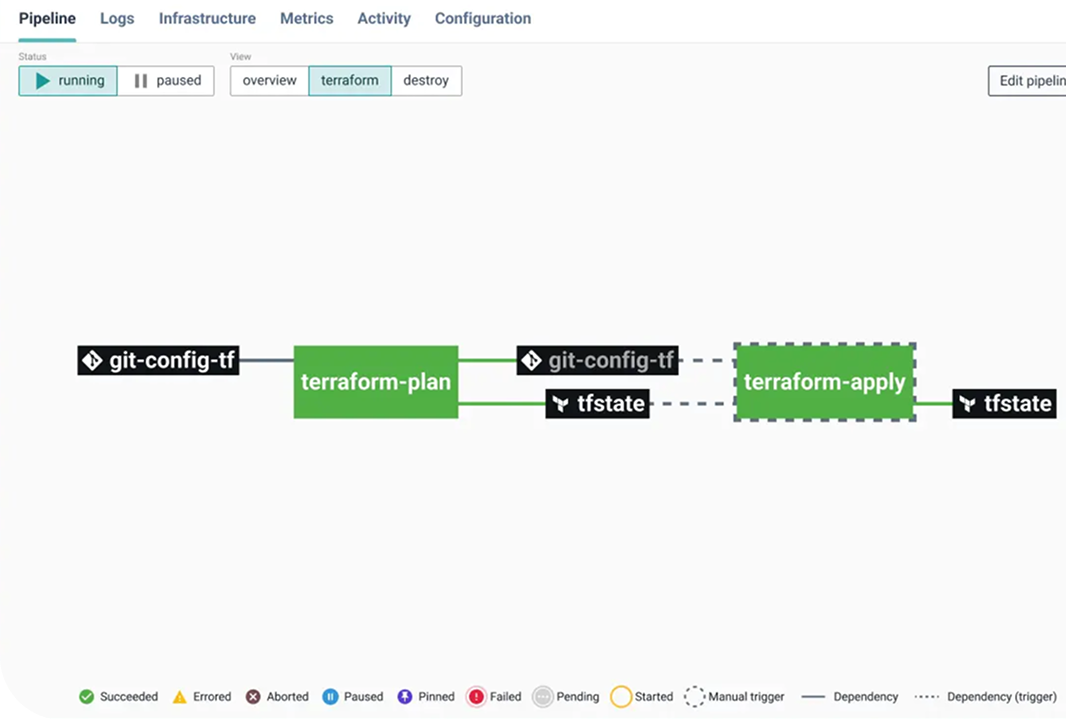
Les équipes qui utilisent des outils séparés pour les tâches Day 2 (Rundeck pour les runbooks, kubectl manuel pour les changements Kubernetes, accès console direct pour la montée en charge) créent le même problème de fragmentation que les IDPs existent pour résoudre. Des outils Day 2 séparés génèrent des pistes d’audit séparées, des lacunes de gouvernance séparées et une charge cognitive séparée. L’ingénieur qui doit répondre à un incident Day 2 ne devrait pas avoir à se souvenir lequel de quatre systèmes contient l’action pertinente.
Où la gouvernance Day 0/1/2 s’effondre réellement dans les déploiements enterprise
Les modes de défaillance qui apparaissent à l’échelle ou dans les environnements brownfield partagent généralement une cause commune : le modèle de gouvernance supposait un départ à zéro que l’environnement réel n’a jamais eu.
Comprendre ces modes de défaillance est important non seulement pour diagnostiquer les problèmes existants, mais pour concevoir les artefacts Day 0 qui les préviendront dans les futurs déploiements.
Les environnements brownfield où le Day 0 n’a jamais eu lieu
De nombreuses organisations exploitent une infrastructure cloud significative provisionnée avant qu’un IDP gouverné n’existe. Il n’y a pas d’artefact Day 0 à référencer, pas de définition de stack canonique, pas d’historique Git de l’état souhaité. La gouvernance Day 2 pour ces environnements ne peut pas partir d’une définition de Stack parce qu’il n’en existe aucune.
InfraImport est actuellement une fonctionnalité en bêta et fonctionne selon le principe du meilleur effort. Le code Terraform généré nécessite une revue et une adaptation par les équipes platform avant d’être utilisé dans les workflows de production. InfraImport de Cycloid répond à cela directement. Le générateur Terraform inverse, construit sur les mêmes concepts que le projet open-source TerraCognita de Cycloid (plus de 2 400 étoiles GitHub), lit les ressources cloud existantes et génère la configuration IaC et les templates de Stack à partir de ce qui est déjà déployé. La sortie est un artefact Day 0 rétroactif depuis lequel la gouvernance Day 2 peut démarrer. Il ne reconstruira pas l’intention originale derrière chaque décision de configuration, mais il crée la baseline versionnée que la détection de dérive et la gouvernance continue nécessitent.
Les environnements multi-cloud et hybrides où les politiques de gouvernance divergent
Les grandes entreprises exécutent des charges de travail sur plusieurs fournisseurs cloud et des environnements on-premises. Les politiques de gouvernance conçues pour AWS ne se traduisent pas automatiquement en Azure ou GCP. Les données de coût vivent dans des systèmes de facturation séparés. Les modèles RBAC diffèrent entre fournisseurs. Les équipes gérant des charges de travail sur plusieurs environnements appliquent fréquemment des standards de gouvernance différents selon les environnements — non pas parce qu’elles veulent de l’incohérence, mais parce que leurs outils n’unifient pas le modèle de gouvernance entre fournisseurs.
Les stacks Cycloid supportent AWS, Azure, GCP et VMware vSphere via Terraform ou OpenTofu. InfraImport (basé sur TerraCognita) cible les mêmes fournisseurs, tandis que le backend HTTP Terraform utilisé par Asset Inventory supporte le stockage compatible S3 tel qu’AWS S3, Google Cloud Storage, Azure Blob Storage et MinIO. Le module FinOps centralise les données de coût de tous les fournisseurs cloud dans une vue unique, filtrée par projet, région et fournisseur. Le modèle de gouvernance encodé dans une définition de Stack ne change pas selon l’endroit où la Stack est déployée — ce qui signifie que les problèmes de dérive et de gestion des coûts Day 2 ne nécessitent pas d’outillage séparé par cloud.
Le problème d’adoption du libre-service qui fait s’effondrer la gouvernance Day 2
Un IDP avec libre-service gouverné ne contrôle les opérations Day 2 que pour les environnements provisionnés via lui. Les équipes qui adoptent des contournements — accès console direct, exécutions terraform apply ad hoc hors pipeline, commandes kubectl contre des clusters de production — créent des environnements non gouvernés qui se trouvent entièrement en dehors de la couche d’observabilité et de gouvernance. La plateforme ne sait pas que ces environnements existent sous leur forme actuelle, donc elle ne peut ni détecter la dérive, ni appliquer les plafonds budgétaires, ni leur appliquer la gouvernance du cycle de vie.
Le signal organisationnel documenté par Cycloid vaut d’être noté : les demandes de revue manuelle que la plateforme ne peut pas résoudre seule représentent un contexte manquant, des contraintes manquantes ou des valeurs par défaut manquantes dans les définitions de Stack. Chacune est un signal d’améliorer l’artefact Day 0, de resserrer le .forms.yml, d’ajouter une valeur par défaut manquante, d’étendre la gouvernance à une action du cycle de vie qui sort actuellement du périmètre. Ajouter un réviseur humain pour gérer l’écart est la réponse la plus coûteuse — et elle ne résout pas le problème sous-jacent.
Conclusion
Le modèle Day 0/1/2 n’est aussi durable que la couche de gouvernance qui couvre les trois phases. Cet article a couvert comment le Day 0 produit les artefacts d’ingénierie — frontières RBAC, définitions de stacks .forms.yml, hiérarchies de visibilité des catalogues — qui contraignent chaque opération en aval. Le provisionnement Day 1, gouverné via StackForms et les enregistrements de commit GitOps, transporte ces contraintes dans l’environnement déployé sans nécessiter de revue manuelle pour les demandes standard. Les opérations Day 2, lorsqu’elles sont traitées comme des actions platform de première classe plutôt que comme du travail hors bande, appliquent les mêmes chemins appliqués à la montée en charge, aux mises à jour et à la mise hors service qu’à la création.
L’outillage de Cycloid — Stacks, StackForms, Asset Inventory, InfraView et pipelines CI/CD managés — couvre les trois phases, avec la détection de dérive et la gouvernance FinOps maintenant la plateforme alignée sur l’état souhaité qu’elle a été conçue pour maintenir. La plateforme ne remplace pas le jugement des ingénieurs. Elle cesse de demander un jugement sur des décisions qui ont déjà été prises au Day 0.
FAQ
1. Quelle est la différence entre les opérations Day 0, Day 1 et Day 2 ?
Le Day 0 est la phase de conception où vous construisez les templates, le RBAC et les politiques qui contraignent tout ce qui suit. Le Day 1 est la fenêtre de déploiement où vous provisionnez l’infrastructure initiale. Le Day 2 est l’état durable — la phase la plus longue, couvrant la montée en charge, le patching et la gestion de la dérive jusqu’à la mise hors service du système.
2. Comment les IDPs appliquent-ils la gouvernance pendant le Day 2 ?
La gouvernance reste active en forçant les modifications post-provisionnement (comme la montée en charge ou les mises à jour) à passer par les mêmes workflows protégés utilisés au lancement. Au lieu de modifications manuelles via la console, les changements doivent passer par des formulaires versionnés et des pipelines qui respectent les plafonds budgétaires et les frontières de sécurité prédéfinies.
3. Qu’est-ce qui cause la dérive de configuration et comment la résout-on ?
La dérive se produit quand des « hotfixes » manuels sont effectués directement dans la console cloud, contournant le contrôle de version. Les équipes platform résolvent cela via la détection continue de dérive, qui compare l’environnement réel à la définition de Stack sauvegardée dans Git et alerte les équipes pour réconcilier les états avant que des défaillances ne surviennent.
4. Comment la gouvernance Day 2 fonctionne-t-elle pour Kubernetes à l’échelle ?
Parce que Kubernetes comporte de nombreux composants mobiles comme les HPA et les politiques réseau, la gouvernance est intégrée dans les templates de déploiement. Cela garantit que la rotation des certificats, les limites de montée en charge et les mises à jour de cluster sont gérées automatiquement et de façon cohérente entre toutes les équipes, empêchant des erreurs de configuration mineures de devenir des pannes majeures.


