TL;DR
- Un environnement réglementé est un environnement où les modifications d’infrastructure doivent suivre des processus documentés et reproductibles produisant des preuves d’audit cohérentes entre les systèmes. Dans des secteurs tels que la finance, l’assurance, la logistique et les services gouvernementaux, l’absence d’application des mêmes contrôles sur les environnements on-premises et cloud conduit fréquemment à des constats d’audit et des incidents de sécurité.
- Le rapport IBM Cost of a Data Breach 2025 montre que les organisations dont les contrôles de sécurité et de conformité sont fragmentés mettent en moyenne 241 jours à identifier et contenir les violations, augmentant leur exposition réglementaire et financière.
- De nombreuses organisations s’appuient sur des revues manuelles après que le travail technique est terminé. Cela ralentit la livraison sans empêcher les violations de politique. Appliquer la conformité au stade de la demande permet de valider l’intention avant toute modification d’infrastructure, réduisant la dépendance aux revues humaines.
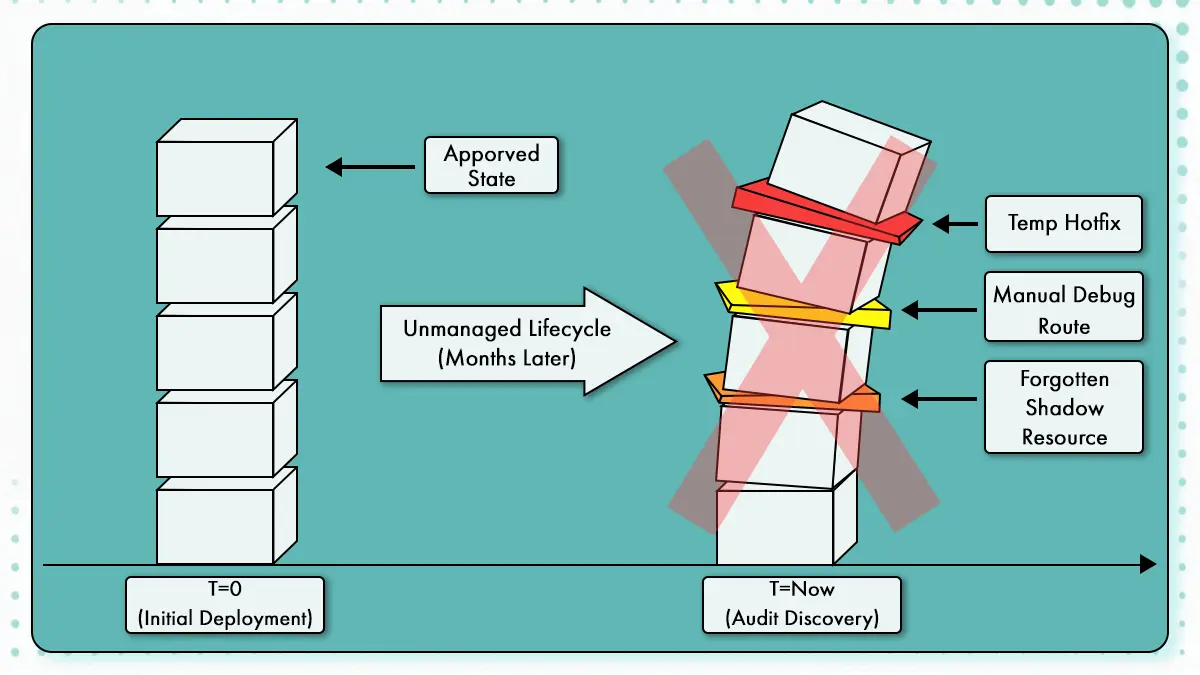
- La conformité ne se limite pas au provisionnement initial. Sans supervision continue, les correctifs temporaires et la dérive de configuration s’accumulent au fil du temps, créant des risques généralement découverts des mois plus tard lors d’audits. Gérer l’infrastructure comme un cycle de vie aide à maintenir l’état approuvé de la création jusqu’à la mise hors service.
- Lorsque la gouvernance dépend des connaissances techniques spécifiques d’ingénieurs individuels, elle devient un goulot d’étranglement. Permettre aux développeurs de demander des résultats au lieu d’écrire du code d’infrastructure bas niveau permet une application cohérente des patterns approuvés entre les environnements.
- L’infrastructure qui échappe à un système gouverné conduit souvent à des dépenses non suivies et à un gaspillage d’énergie, parce que la propriété et l’objet se perdent entre les frontières d’environnement. Une couche de gouvernance permet de relier les ressources à leurs propriétaires, à l’intention métier et aux exigences de conformité.
Dans les environnements réglementés, les défaillances d’audit résultent souvent de petits changements de routine plutôt que d’incidents majeurs. Ce schéma est courant dans les secteurs hautement réglementés tels que les services financiers, l’assurance, la logistique et les plateformes opérées par des administrations publiques, où les modifications d’infrastructure font l’objet d’une supervision formelle. Le rapport IBM Cost of a Data Breach 2025 indique que les organisations dont les contrôles de sécurité et de conformité sont déconnectés entre les environnements mettent plus de temps à détecter et à contenir les problèmes, le cycle de vie moyen d’une violation dépassant 292 jours. Ce délai est rarement causé par un manque de logiciels — il est généralement dû à une application irrégulière dans des systèmes soumis aux mêmes règles de gouvernance.
Opérer sur des environnements matériels et virtualisés expose des différences techniques entre la gestion par tickets et les déploiements automatisés. Une règle de pare-feu on-premises approuvée via un ticket, un plan Terraform exécuté depuis un compte partagé, et un déploiement Kubernetes via un pipeline peuvent tous être des actions valides. Chacune génère des enregistrements d’approbation différents, des journaux différents et des données de propriété différentes. Lors d’un audit, ces différences techniques comptent plus que le changement lui-même. Les auditeurs ne demandent pas si le changement était correct : ils demandent si le processus était identique à chaque fois. Cette distinction est au cœur des programmes de conformité tels que SOC 2, ISO 27001, PCI DSS et les normes de sécurité gouvernementales.
Les ingénieurs dans les secteurs réglementés discutent fréquemment de ces défaillances. Un récent fil de discussion sur Reddit r/devops décrit comment les audits ressemblent à de l’archéologie, car les modifications d’infrastructure dans les clouds publics contournent souvent la gestion formelle des changements.

Même lorsque la configuration technique est sécurisée, l’absence d’enregistrement unifié crée un risque significatif. Les équipes ont signalé des semaines de travail manuel pour créer de la documentation pour des actions déjà en production.
Ajouter des revues manuelles est une réponse courante mais inefficace. Les demandes de changement deviennent plus longues et les chaînes d’approbation plus complexes. Les preuves sont collectées après le changement pour démontrer ce que l’ingénieur avait l’intention de faire. Cela augmente les délais d’attente sans corriger l’écart d’application sous-jacent. Le problème fondamental est que l’infrastructure hybride est gérée comme des entités séparées au lieu d’un environnement gouverné unique.
Cet article examine les environnements hybrides d’un point de vue opérationnel. L’accent est mis sur la façon dont la gouvernance échoue entre les environnements, pourquoi les outils standard ne préviennent pas ces défaillances, et ce dont les équipes réglementées ont besoin pour gérer l’infrastructure hybride sans générer d’exceptions.
Pourquoi les environnements réglementés et gouvernementaux requièrent une application uniforme dans le hybrid cloud
Les environnements réglementés et gouvernementaux nécessitent une application uniforme parce que les modifications d’infrastructure doivent être prouvables, reproductibles et auditables sur tous les systèmes impliqués. Dans les configurations hybrid cloud, les modifications de routine couvrent fréquemment les environnements on-premises, cloud privé et cloud public, chacun régi par des mécanismes de contrôle différents. Sans une application uniforme, les organisations ne peuvent pas démontrer que la même politique a été suivie à chaque fois.
Considérons une plateforme de paiement, un portail de services gouvernementaux ou un système de gestion des sinistres d’assurance où le traitement sensible s’effectue on-premises pour des raisons réglementaires, tandis que les services applicatifs tournent dans le cloud public. Opérationnellement, c’est un seul système qui délivre un service unique. Du point de vue du contrôle, il est géré via des processus de changement, des modèles d’accès et des mécanismes de journalisation séparés.
L’écart apparaît quand un seul changement logique — comme autoriser un service hébergé dans le cloud à accéder à des données réglementées on-premises — est divisé en plusieurs actions indépendantes. Chaque action est approuvée, journalisée et suivie de manière isolée. Aucun système n’évalue si le changement combiné est conforme à la politique dans son ensemble, ni ne produit un enregistrement unique montrant que l’application a été cohérente de bout en bout.
Pour comprendre pourquoi cela se produit, il faut examiner comment l’application est limitée aux plateformes individuelles, comment les équipes compensent lorsqu’aucun contrôle partagé n’existe, et comment la connaissance opérationnelle devient un prérequis pour rester en conformité.
Les plans de contrôle ne traversent pas les frontières d’infrastructure
Dans l’exemple de la plateforme de paiement, un ingénieur doit autoriser un service hébergé dans le cloud à se connecter à une base de données on-premises. Cette seule exigence se traduit par plusieurs modifications techniques. On-premises, une règle de pare-feu doit être mise à jour via un workflow de changement IT avec approbation documentée et fenêtre d’exécution planifiée. Dans le cloud public, une règle de groupe de sécurité est modifiée via des outils d’infrastructure utilisant les permissions d’identité cloud. Dans Kubernetes, un compte de service ou un role binding est ajusté pour permettre à l’application d’initier la connexion.
Ces actions sont directement liées et ensemble, elles permettent un chemin d’accès d’un service spécifique à des données réglementées. Chaque système applique ses propres règles locales. Le changement de pare-feu vérifie si la règle respecte la politique réseau. La plateforme cloud vérifie si l’identité a la permission de modifier les groupes de sécurité. Kubernetes vérifie si le compte de service est autorisé à accéder au namespace.
Le problème est que l’application s’arrête à ces vérifications individuelles. Aucun contrôle n’évalue le changement dans son ensemble. Il n’existe aucun mécanisme qui détermine si ce service spécifique, s’exécutant dans cet environnement, devrait être autorisé à accéder à cet ensemble de données selon la politique organisationnelle et réglementaire en vigueur. Chaque système approuve sa partie sans visibilité sur le résultat combiné.
Lorsque le changement est ensuite examiné, les équipes se retrouvent avec des enregistrements séparés qui décrivent des actions individuelles plutôt que l’intention qu’elles servaient collectivement. Pour compenser cet écart, les organisations introduisent des étapes de coordination manuelle pour relier les éléments, ce qui augmente les délais et déplace l’application des systèmes vers les personnes.
Les revues manuelles remplacent l’application par les systèmes
Lorsqu’aucun système unique n’applique la politique sur un changement complet, les équipes réglementées compensent en ajoutant des étapes de coordination. Ces étapes ne sont pas conçues pour appliquer des règles directement. Elles existent pour réconcilier des actions effectuées sur plusieurs plateformes approuvées indépendamment.
Dans la plateforme de paiement, une seule exigence d’accès couvre la configuration réseau, les règles d’accès cloud et les permissions applicatives. Parce que chaque système n’évalue que son propre changement, les équipes introduisent un processus de revue manuelle pour les relier. Les ingénieurs sont invités à soumettre des preuves montrant ce qui a été modifié dans chaque environnement — mises à jour des règles de pare-feu, modifications des accès cloud et changements de permissions applicatives — sous une seule demande de revue.
Ce processus de revue tente de répondre à une question qu’aucun système n’avait adressée plus tôt : si le changement combiné résulte en un schéma d’accès conforme à la politique organisationnelle et réglementaire. La revue n’empêche pas le changement d’être préparé. Elle l’évalue après que les étapes techniques sont déjà définies, et dans certains cas après que des parties du changement sont déjà en production.
Cette approche introduit deux problèmes structurels. Premièrement, le volume de revues croît avec le nombre de modifications d’infrastructure, pas avec leur risque. Les changements de routine nécessitent le même effort de coordination que les changements sensibles. Deuxièmement, quand une revue identifie un désalignement de politique ou un chemin d’accès non intentionnel, inverser le changement est difficile. Le travail a déjà été distribué entre des systèmes avec des mécanismes de rollback différents.
Au fil du temps, ce schéma remodèle la façon dont la gouvernance est vécue. Les changements sont perçus comme lents parce qu’ils attendent la coordination plutôt que l’application. Les changements à faible risque sont retardés, tandis que les changements à risque élevé dépendent toujours du jugement humain pour détecter des problèmes que les systèmes n’ont pas empêchés. Le processus enregistre ce qui s’est passé, mais il ne contrôle pas de manière fiable ce qui est autorisé. Du point de vue de la conformité, cela crée un état fragile où des contrôles existent et sont documentés, mais sont appliqués après coup et de façon incohérente entre les environnements.
La connaissance de l’infrastructure devient une porte de conformité
À mesure que les revues manuelles deviennent plus lentes et plus lourdes, les équipes cherchent des moyens de réduire la charge de coordination. Dans de nombreux environnements réglementés, cela conduit à intégrer la logique de gouvernance dans les outils d’infrastructure eux-mêmes. Au lieu de s’appuyer sur des comités de revue pour évaluer si un changement est acceptable, les équipes encodent les règles directement dans la façon dont l’infrastructure peut être définie et modifiée.
Dans la plateforme de paiement, cela prend la forme de templates réseau contraints, de schémas d’accès prédéfinis et de politiques de plateforme appliquées au niveau des outils. Les modules Terraform limitent les ressources qui peuvent être créées, les politiques Kubernetes restreignent les actions autorisées dans certains namespaces. Les configurations réseau appliquent des patterns fixes pour connecter les services aux données réglementées.
Ces contrôles réduisent la nécessité de revues manuelles répétées, mais introduisent une nouvelle dépendance. Seuls les ingénieurs qui comprennent comment les règles de gouvernance sont exprimées dans toutes les couches peuvent effectuer des changements efficacement. Les changements qui correspondent aux patterns encodés avancent rapidement. Ceux qui ne correspondent pas nécessitent interprétation, exceptions ou implication de spécialistes. Cela crée à nouveau un modèle opérationnel inégal.
Les spécialistes de la plateforme qui comprennent les outils avancent vite parce qu’ils savent comment travailler dans les contraintes. Les équipes produit attendent de l’aide ou contournent les contrôles via des rôles partagés et des scripts ponctuels pour éviter les délais. Les résultats de conformité commencent à dépendre de qui effectue le changement, et non d’un système appliqué de manière cohérente.
À ce stade, la gouvernance n’est plus principalement appliquée par des contrôles partagés. Elle est appliquée par l’expertise individuelle. À mesure que l’infrastructure s’étend sur davantage d’environnements, cette dépendance aux connaissances spécialisées devient fragile, poussant les organisations vers des décisions architecturales qui privilégient l’applicabilité sur la flexibilité.
L’architecture hybrid cloud sous contraintes réglementaires
L’architecture hybrid cloud dans les organisations réglementées est généralement façonnée par des exigences externes plutôt que par des préférences techniques. Les règles de résidence des données maintiennent les bases de données on-premises. Les contraintes de latence poussent certains services plus près des utilisateurs. Les considérations de coût et de disponibilité orientent le reste vers le cloud public. Ce schéma architectural est courant dans les systèmes gouvernementaux et les industries réglementées où l’infrastructure héritée, les règles nationales de résidence des données et les longs cycles d’audit contraignent les options de refonte.
Le résultat est un système qui doit fonctionner comme une seule plateforme tout en s’exécutant sur plusieurs environnements. Le défi architectural n’est pas de tracer le diagramme. Le défi est d’appliquer les mêmes attentes de gouvernance à chaque partie de ce diagramme sans forcer les équipes à reconstruire ce qui existe déjà.
Les régulateurs se soucient de la cohérence, pas de la topologie
Dans la plateforme de paiement, les auditeurs ne s’opposent pas aux charges de travail s’exécutant à différents endroits. Ce qu’ils examinent, c’est si l’approbation des accès, le suivi des changements et la journalisation suivent les mêmes règles quel que soit l’endroit où la charge de travail s’exécute.
Si un changement de base de données on-premises nécessite une approbation et produit une piste d’audit, mais qu’un changement de service cloud ne le fait pas, l’architecture devient plus difficile à justifier. Le risque n’est pas la conception hybride elle-même. Le risque est que l’application des politiques dépend de l’emplacement. Cette distinction est importante car elle déplace l’attention de la refonte de l’architecture vers la correction de la couverture de gouvernance.
Traiter l’infrastructure existante comme gouvernable, pas immuable
Une erreur courante dans les environnements hybrides réglementés est de traiter l’infrastructure existante comme extérieure au système de gouvernance. Dans la plateforme de paiement, les bases de données on-premises de longue date et les règles réseau héritées sont souvent exclues parce qu’elles ont été créées des années auparavant. Cela crée des angles morts. La propriété est floue. L’historique des changements est incomplet. Les auditeurs élargissent le périmètre pour inclure ces systèmes, augmentant l’effort de revue dans l’ensemble.
Pour éviter cela, l’infrastructure existante doit être placée sous gouvernance sans forcer des reconstructions. La découverte, l’attribution de propriété et le suivi du cycle de vie doivent s’appliquer rétroactivement, pas seulement aux nouveaux déploiements. Une fois que les systèmes existants sont gouvernables, les équipes peuvent arrêter de débattre de la migration et commencer à se concentrer sur la gestion de ce qui tourne déjà.
La stratégie import-first surpasse les stratégies rebuild-first
Reconstruire l’infrastructure pour atteindre la conformité est rarement faisable dans les industries réglementées. Les projets de migration nécessitent des cycles d’approbation prolongés, une planification des temps d’arrêt et une justification budgétaire. En conséquence, les améliorations de gouvernance sont retardées ou abandonnées.
Une approche import-first permet aux équipes de commencer à gouverner immédiatement. Dans la plateforme de paiement, les bases de données on-premises existantes, les services cloud et les chemins réseau sont intégrés dans un système géré où les politiques, la propriété et les règles de cycle de vie peuvent être appliquées de manière cohérente. Cette approche aligne l’architecture avec la réalité opérationnelle. Au lieu d’attendre une plateforme future, la gouvernance commence avec l’infrastructure déjà en production.
Certaines plateformes répondent à cela en important l’infrastructure existante dans un modèle géré plutôt qu’en exigeant un re-provisionnement. Cycloid, par exemple, prend en charge l’import inverse des ressources cloud et on-premises en cours d’exécution dans des définitions d’infrastructure versionnées. Cela permet aux équipes d’appliquer des règles de propriété, de politique et de cycle de vie à une infrastructure déjà existante, au lieu de retarder la gouvernance jusqu’à une future migration.
Gestion du hybrid cloud sans exceptions
L’architecture hybrid cloud décrite précédemment définit où s’exécutent les différentes parties du système — bases de données on-premises, services cloud public et plateformes partagées. La gestion détermine si ce système continue à respecter les exigences réglementaires et organisationnelles après son déploiement.
Dans les environnements hybrides réglementés, les problèmes de conformité émergent le plus souvent lors de changements opérationnels de routine — mise à jour des règles d’accès réseau, ajustement des permissions de service, mise à l’échelle des charges de travail ou modification des configurations applicatives. Ces changements se produisent fréquemment et en dehors des workflows de provisionnement initial. Les opérations day 2 révèlent si la gouvernance est activement appliquée ou simplement enregistrée après coup.
Dans la plateforme de paiement, les services applicatifs dans le cloud public sont mis à jour hebdomadairement, parfois quotidiennement. Les chemins réseau, les règles d’accès et les ressources de calcul changent à mesure que les schémas de trafic évoluent. Si la gouvernance s’applique uniquement au moment de la création, le système dérive progressivement loin de l’état approuvé, même lorsque chaque changement était bien intentionné. Pour éviter cela, la gouvernance doit se déplacer en amont dans la façon dont les changements sont demandés et en aval dans la façon dont l’infrastructure est opérée au fil du temps.
Appliquer la gouvernance au moment de la demande
La section précédente montre pourquoi la gouvernance s’effondre lors des changements opérationnels de routine. Lorsque les décisions d’accès, de configuration et de mise à l’échelle sont prises fréquemment sur plusieurs environnements, appliquer la politique après coup devient peu fiable. L’application au moment de la demande résout ce problème en évaluant les changements avant toute modification du système.
Dans le même exemple de plateforme de paiement, un développeur a besoin de déployer une nouvelle version d’un service nécessitant un accès à une base de données de transactions on-premises. Cette exigence n’est pas une seule action technique. Elle se traduit par plusieurs changements coordonnés : mise à jour d’une règle réseau pour autoriser le trafic, ajustement d’une politique d’accès cloud et modification des permissions applicatives dans Kubernetes. Chaque plateforme n’évalue que son propre changement, car les approbations sont limitées au modèle de contrôle de cette plateforme.
Sans application au moment de la demande, ces actions sont approuvées indépendamment. Le changement réseau est valide en lui-même, la règle d’accès cloud suit la politique d’identité. La permission applicative est autorisée dans le cluster. Ce qui n’est jamais évalué, c’est si ce service spécifique, dans cet environnement, devrait être autorisé à accéder aux données réglementées comme opération complète.
L’application au moment de la demande évalue l’intention derrière le changement avant l’exécution. Au lieu d’approuver des actions individuelles, le système évalue si un service de ce type est autorisé à accéder à cette classe de données selon les règles organisationnelles et réglementaires en vigueur, quel que soit l’endroit où s’exécutent les ressources sous-jacentes. Si la demande n’est pas conforme, elle est rejetée avant toute modification d’infrastructure. Cela remplace la coordination post-changement par le contrôle pré-changement. Les équipes n’ont plus besoin d’expliquer après le déploiement pourquoi une combinaison d’actions approuvées individuellement a abouti à un chemin d’accès non intentionnel. Elles savent à l’avance si la demande est autorisée.
Une fois l’intention appliquée de manière cohérente, le défi suivant est de réduire la charge sur les développeurs en s’assurant qu’ils n’ont pas besoin de comprendre chaque système sous-jacent pour soumettre des demandes conformes.
Séparer l’intention de l’implémentation
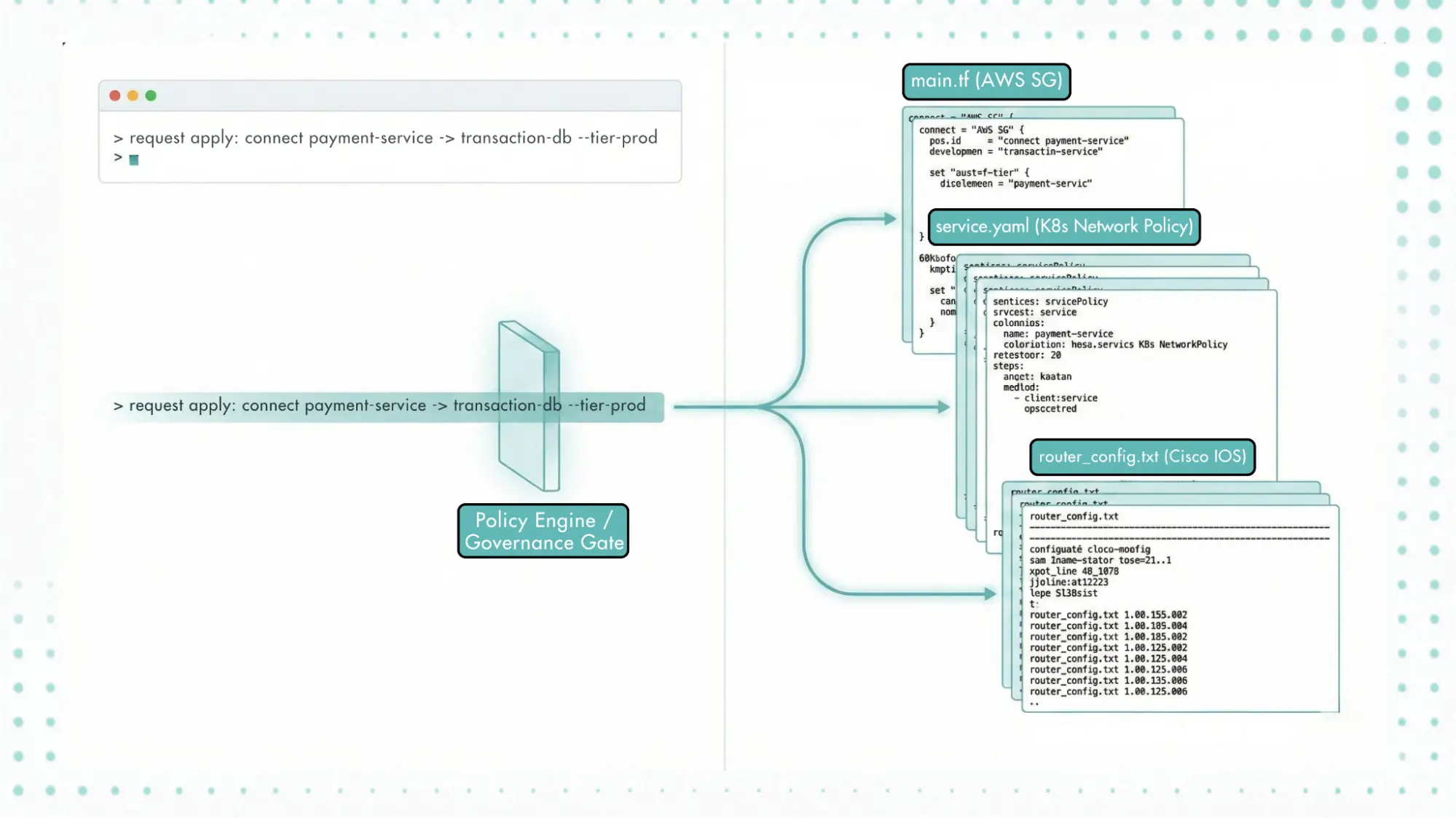
Dans de nombreuses organisations, les modifications d’infrastructure sont effectuées directement via des mécanismes de configuration spécifiques aux fournisseurs. Pour les ressources cloud, cela implique souvent d’écrire des définitions d’infrastructure pour créer ou modifier des services, des réseaux et des règles d’accès. Pour les environnements on-premises, cela implique des outils de configuration réseau et des systèmes de gestion des changements. Pour Kubernetes, cela signifie modifier des manifestes et des role bindings qui contrôlent l’accès applicatif.
Dans la plateforme de paiement, cela signifie qu’un développeur doit comprendre comment exprimer la même exigence dans plusieurs systèmes. Pour autoriser un service à accéder à des données réglementées, il doit savoir comment modifier les règles d’accès cloud, mettre à jour les chemins réseau et ajuster les permissions applicatives. La gouvernance repose sur l’ingénieur qui applique le bon pattern à chaque endroit, à chaque fois.
Ici, l’intention et l’implémentation ne sont pas séparées.
- L’intention est l’exigence au niveau de la politique — par exemple : déployer un service autorisé à accéder aux données de transaction dans des conditions définies.
- L’implémentation est l’ensemble des étapes techniques nécessaires pour réaliser cette intention — telles que les changements de règles réseau, les permissions d’identité et les mises à jour de configuration applicative.
Séparer l’intention de l’implémentation change la façon dont la gouvernance est appliquée. Les développeurs soumettent des demandes qui décrivent ce qu’ils souhaitent accomplir, et non comment configurer chaque système. La plateforme évalue si ce résultat est autorisé et, le cas échéant, applique les modifications d’infrastructure approuvées de manière cohérente entre les environnements.
Cette séparation ne supprime pas les outils d’infrastructure — elle supprime la nécessité que chaque demandeur les comprenne et les opère directement. L’application se produit au niveau de l’intention, avant l’exécution, au lieu de reposer sur l’exactitude de chaque commande individuelle.
La gouvernance basée sur l’intention nécessite une interface structurée qui capture les résultats autorisés tout en maintenant l’exécution standardisée. Cycloid implémente cela en séparant les entrées de demande de l’implémentation d’infrastructure, en utilisant des formulaires contrôlés adossés à des stacks prédéfinis. Par exemple, un développeur demande le déploiement d’un service avec des caractéristiques approuvées d’accès aux données et de journalisation, tandis que la plateforme applique les changements réseau, d’identité et applicatifs correspondants en utilisant des patterns établis entre les environnements.
Une fois l’intention appliquée de cette manière, le défi restant est de s’assurer que l’infrastructure continue à respecter les règles approuvées après le déploiement, ce qui mène à la gestion du cycle de vie.
Choisissez des variables d’environnement prédéfinies et d’autres scénarios spécifiques depuis un simple menu déroulant.
Gérer l’infrastructure comme un cycle de vie, pas un déploiement
Séparer l’intention de l’implémentation garantit que les changements sont approuvés avant d’être exécutés. Cependant, l’application basée sur l’intention seule est insuffisante si la gouvernance s’arrête une fois l’infrastructure créée. Dans les environnements réglementés et gouvernementaux, la plupart des violations de politique émergent après le déploiement, lorsque les systèmes évoluent au gré des changements opérationnels de routine.
Dans la plateforme de paiement, les services déployés avec un accès approuvé changent progressivement au fil du temps. Les règles réseau ajoutées temporairement pour soutenir le dépannage restent en place. Les permissions de service sont élargies pour prendre en charge de nouvelles fonctionnalités et jamais réduites. Les services mis hors service laissent derrière eux des chemins d’accès qui ne servent plus aucun objectif métier. Chaque changement peut être raisonnable isolément, mais ensemble ils éloignent le système de l’intention initialement approuvée.
C’est le point où la gouvernance s’affaiblit souvent : si l’application ne s’applique qu’au moment de la création, il n’existe aucun mécanisme pour s’assurer que le système continue à refléter la politique approuvée à mesure qu’il change. La propriété devient floue et les preuves de pourquoi une ressource existe ou à quoi elle est autorisée à accéder se fragmentent entre les outils et les équipes.
Gérer l’infrastructure comme un cycle de vie signifie que les mises à jour, les rollbacks et la mise hors service sont soumis aux mêmes contrôles que la création initiale. L’état approuvé est traité comme quelque chose qui doit être préservé, pas supposé. Les changements sont évalués par rapport à la politique en vigueur, et l’infrastructure qui ne sert plus un objectif approuvé peut être identifiée et traitée.
L’application du cycle de vie nécessite que l’infrastructure reste sous gestion active après son déploiement. Les stacks Cycloid persistent comme des entités gérées plutôt que des exécutions ponctuelles. Cela permet d’évaluer, d’appliquer et de suivre les changements d’infrastructure de manière cohérente au fil du temps, que les ressources s’exécutent on-premises ou dans le cloud public.
Cette continuité est ce qui permet à la gouvernance basée sur l’intention de tenir au-delà de la demande initiale. Sans elle, l’application se dégrade progressivement à mesure que les systèmes évoluent.
Voir le risque avant qu’il ne devienne un problème de conformité
La gouvernance du cycle de vie dépend de la connaissance de si l’infrastructure reflète encore l’intention approuvée au fur et à mesure de son évolution. Sans visibilité sur la façon dont les systèmes se connectent et changent au fil du temps, l’application se dégrade silencieusement. Les problèmes ne sont pas introduits tous en même temps. Ils émergent à mesure que de petits changements s’accumulent entre les environnements.
Dans les environnements hybrides, ce risque augmente parce que les relations entre les services, les réseaux et les entrepôts de données couvrent plusieurs plateformes. Un système peut toujours paraître conforme lorsqu’il est examiné ressource par ressource, tandis que son comportement combiné ne correspond plus à la politique.
Les dépendances cachées réduisent la confiance dans le contrôle
Dans la plateforme de paiement, un service hébergé dans le cloud atteint une base de données on-premises via une combinaison de chemins réseau, de règles d’accès et de permissions applicatives. Chacun de ces éléments est autorisé indépendamment par la plateforme à laquelle il appartient. Les contrôles réseau valident les règles de routage. Les plateformes cloud valident les permissions d’identité. Les plateformes applicatives valident l’accès aux services.
Ce qui manque, c’est la visibilité sur la dépendance combinée qu’ils créent. Aucun système unique ne montre comment ces autorisations individuelles forment un chemin d’accès de bout en bout vers des données réglementées. En conséquence, les équipes ne peuvent pas facilement vérifier si l’accès d’un service est toujours aligné avec son objectif approuvé.
C’est important parce que les exigences de conformité sont liées à quelles données sont accédées et pourquoi elles sont accédées, pas seulement à la configuration de chaque ressource individuelle. Les relevés de transactions, les données personnelles ou les ensembles de données gouvernementaux ne peuvent être accédés que par des services spécifiques effectuant des fonctions définies. Lorsque les dépendances ne sont pas claires, vérifier cet alignement devient difficile.
La visibilité centralisée aide à réduire cette incertitude. Cycloid fournit une vue unifiée des actifs d’infrastructure et de leurs relations entre environnements on-premises et cloud, rendant les chemins d’accès et les dépendances explicites au lieu d’inférés depuis des tickets et des journaux.
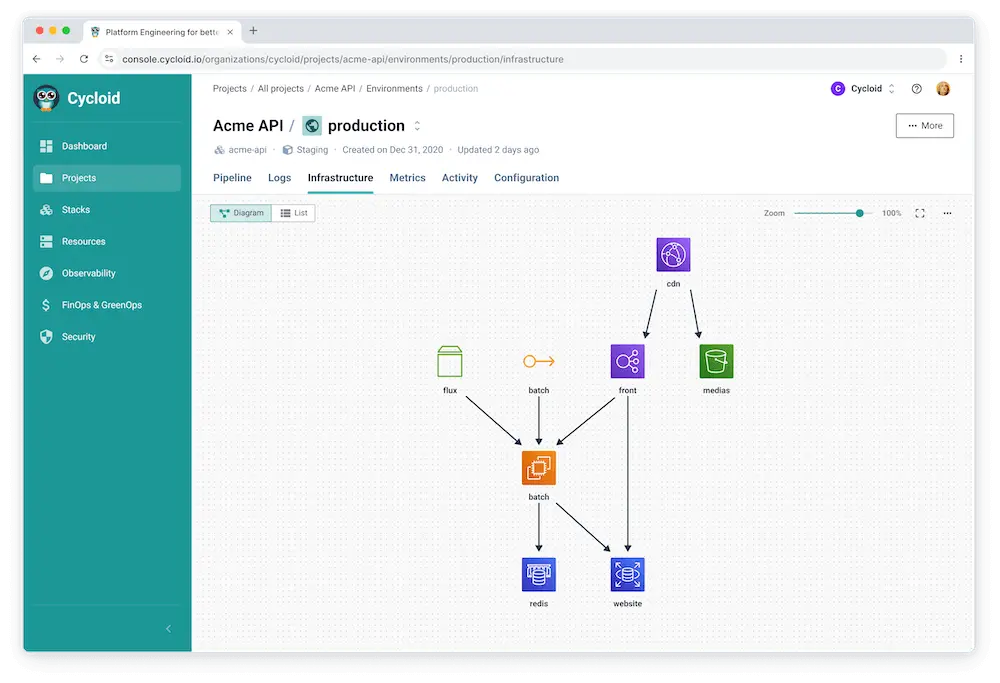
Dans le diagramme ci-dessus, chaque nœud représente un composant déployé — un service, un bucket de stockage, un cache ou une couche de distribution. Les flèches entre eux représentent des dépendances réelles et opérationnelles. Par exemple, un service front-end route le trafic via une couche de distribution de contenu, qui se connecte ensuite aux services backend et aux entrepôts de données. Ces relations ne sont pas inférées depuis la documentation. Elles sont dérivées de l’état réel de l’infrastructure.
C’est important parce que la gouvernance concerne rarement une seule ressource. Elle concerne qui peut atteindre quoi, via quels intermédiaires, et dans quel but. Sans suivi des dépendances, les équipes évaluent les permissions de manière isolée. Avec le suivi des dépendances, elles peuvent tracer un chemin d’accès complet depuis un point d’entrée jusqu’aux données réglementées.
En pratique, cela permet aux équipes de répondre à des questions telles que :
- Quels services peuvent atteindre cet entrepôt de données aujourd’hui ?
- Via quels chemins réseau et dépendances de services ?
- Chaque étape de ce chemin sert-elle encore une fonction métier approuvée ?
Consultez des informations à jour sur les ressources de votre infrastructure cloud pour diffuser l’information au sein de votre équipe.
Pourquoi la gouvernance détermine la responsabilité des coûts et de l’énergie
Les coûts et l’usage d’énergie dans les environnements hybrides réglementés sont le résultat de la façon dont l’infrastructure est gouvernée au fil du temps. Lorsque des systèmes sont créés sans propriété, objectif et contraintes de cycle de vie clairs, la consommation de ressources croît indépendamment du besoin métier.
En pratique, créer de l’infrastructure alloue une capacité réelle. Instancier un cluster Kubernetes réserve des ressources de calcul, de stockage et réseau. Le déployer dans une région spécifique fixe à la fois son profil de coût et ses caractéristiques énergétiques. Si l’objectif, le propriétaire ou la durée de vie prévue de ce cluster ne sont pas gouvernés, il n’y a aucun déclencheur pour réévaluer s’il doit encore exister ou fonctionner à son échelle actuelle. C’est pourquoi les problèmes de coût et d’énergie ne commencent rarement comme des problèmes budgétaires — ils commencent quand la gouvernance s’arrête au déploiement.
Les problèmes de coût et de carbone dans les environnements hybrides réglementés commencent rarement comme des problèmes budgétaires. Ils commencent comme des lacunes de gouvernance. Lorsque l’infrastructure est créée, modifiée ou laissée en fonctionnement en dehors d’un système gouverné, les dépenses et l’utilisation d’énergie deviennent difficiles à expliquer et plus difficiles à contrôler. Dans les plateformes de logistique et de transport, où l’infrastructure évolue avec la demande saisonnière et l’expansion géographique, ces lacunes de gouvernance se manifestent d’abord comme une croissance de coûts inexpliquée plutôt que comme des constats de sécurité. De plus en plus, les régulateurs financiers et les administrations publiques s’attendent à ce que les données de coûts, d’usage énergétique et de propriété soient auditables, et non inférées.
La perte de propriété conduit à une sur-allocation persistante
Dans la plateforme de paiement, la plupart des infrastructures sont justifiées au moment de leur création. Les problèmes apparaissent plus tard lorsque les services évoluent et que la propriété devient floue. Les clusters créés pour des charges de travail spécifiques continuent de fonctionner longtemps après que leur objectif initial a changé. Les environnements de test et de staging sont dupliqués et jamais mis hors service. Les services conservent des allocations de ressources dimensionnées pour des pics d’utilisation qui ne s’appliquent plus.
Parce que ces ressources couvrent des environnements on-premises et cloud, aucun système ne les suit comme faisant partie d’un cycle de vie unifié. Les données d’utilisation existent, mais elles sont déconnectées de l’intention. Les équipes peuvent voir la consommation, mais elles ne peuvent pas facilement répondre pourquoi la ressource existe encore ou qui en est responsable.
Le même schéma s’applique aux environnements on-premises. Les charges de travail héritées continuent de fonctionner avec des allocations de capacité obsolètes parce qu’aucun processus gouverné n’existe pour les réévaluer. L’usage d’énergie augmente non pas parce que les systèmes sont inefficaces, mais parce que rien n’impose un alignement périodique avec le besoin réel.
La gouvernance permet des décisions significatives sur les coûts et l’énergie
Réduire les coûts ou l’usage d’énergie nécessite plus que la visibilité sur la consommation. Cela nécessite de comprendre la propriété, l’objectif et l’état du cycle de vie. Sans ce contexte, les efforts d’optimisation s’enlisent parce que les équipes ne peuvent pas modifier ou mettre hors service des ressources en toute sécurité.
L’analyse des coûts adossée à la gouvernance dépend de la connaissance de qui possède quoi et pourquoi cela existe. Cycloid corrèle les ressources d’infrastructure avec les données de coût et d’utilisation entre les environnements, permettant aux équipes d’examiner les dépenses et l’usage d’énergie dans le contexte de la propriété et de l’état du cycle de vie.
Pourquoi les outils existants ne peuvent pas appliquer la gouvernance dans les environnements hybrides
La plupart des organisations utilisent déjà plusieurs outils pour gérer les environnements hybrides. Les portails offrent de la visibilité, les systèmes de pipeline exécutent les changements, et chaque outil résout bien un problème local. La défaillance apparaît quand les équipes s’attendent à ce que ces outils appliquent la gouvernance sur l’ensemble du cycle de vie de l’infrastructure.
Les portails sans application augmentent la surface d’attaque
De nombreuses équipes déploient des portails internes pour centraliser l’accès aux workflows d’infrastructure. Dans la plateforme de paiement, le portail pointe vers des consoles cloud, des tableaux de bord de pipeline et de la documentation. Cela améliore la découvrabilité mais n’applique pas de politique.
Quand l’application vit en dehors du portail, les équipes s’appuient encore sur la discipline et les vérifications manuelles. Des plugins et des scripts sont ajoutés pour combler les lacunes. Avec le temps, le portail devient une autre surface qui doit être maintenue et auditée. La visibilité sans contrôle ne réduit pas le risque. Elle augmente le nombre d’endroits où la gouvernance doit être expliquée.
C’est là que la distinction entre un framework et une plateforme gérée est importante. Cycloid
combine un catalogue de services avec des workflows appliqués, la gestion du cycle de vie de l’infrastructure et la visibilité des actifs. La gouvernance est appliquée par le système lui-même, pas assemblée depuis des plugins et des scripts.
Les outils de pipeline exécutent des changements, pas la gouvernance
Les systèmes de pipeline sont efficaces pour exécuter des workflows de manière fiable. Dans la plateforme de paiement, ils appliquent des modifications d’infrastructure, déploient des services et déploient des mises à jour de configuration. Ce qu’ils ne font pas, c’est décider si un changement devrait exister en premier lieu.
Les pipelines exécutent ce qu’on leur donne : si un changement viole une politique, le pipeline s’exécutera quand même à moins qu’une application externe ne le bloque. Les étapes d’approbation dans les pipelines deviennent souvent des points de contrôle manuels, recréant les mêmes problèmes de revue observés ailleurs. Les outils d’exécution sont nécessaires, mais ils ne constituent pas un système de gouvernance. Les traiter comme tels transfère la responsabilité aux réviseurs au lieu des contrôles. Cela laisse les équipes réglementées avec de nombreux outils et aucun moyen cohérent d’appliquer des règles entre les environnements.
Conclusion
Le hybrid cloud n’échoue pas aux organisations réglementées parce qu’il est complexe — il échoue surtout parce que la gouvernance est appliquée de manière inégale entre des environnements censés se comporter comme un seul système. Chaque chemin non géré, qu’il s’agisse d’un changement de pare-feu par ticket ou d’une mise à jour cloud directe, crée un écart qui se manifeste plus tard lors d’audits, de revues d’incidents ou d’enquêtes financières.
Le schéma récurrent est cohérent : des contrôles existent, mais ils sont limités aux plateformes individuelles. Des revues sont ajoutées pour compenser, ralentissant la livraison sans empêcher les erreurs. La connaissance de l’infrastructure devient un prérequis pour la conformité, transformant la gouvernance en responsabilité individuelle plutôt qu’organisationnelle.
Gérer un hybrid cloud sans exceptions nécessite que la gouvernance se déplace en amont et persiste en aval. Ce changement est nécessaire pour répondre aux attentes de conformité modernes — non seulement pour passer les audits mais pour les soutenir dans le temps. Les politiques doivent être appliquées avant la création de l’infrastructure et rester appliquées à mesure que cette infrastructure évolue. Les systèmes existants doivent être placés sous contrôle sans nécessiter de reconstructions. La visibilité doit expliquer comment les systèmes se connectent, pas seulement quelles ressources existent.
Lorsque la gouvernance est appliquée de manière cohérente dans l’architecture et les opérations, le hybrid cloud cesse d’être une source de risque d’audit et de friction opérationnelle. Il devient un modèle opérationnel prévisible où conformité, livraison et responsabilité peuvent coexister sans charge manuelle.
FAQ
1. Le hybrid cloud augmente-t-il le risque de conformité ?
Oui, lorsque la gouvernance est appliquée différemment selon les environnements. Le risque ne vient pas du fait d’exécuter des charges de travail à plusieurs endroits. Il vient de l’application incohérente, des chemins d’approbation et des preuves d’audit.
2. L’architecture ou la gestion du hybrid cloud est-elle plus importante pour la conformité ?
La gestion détermine les résultats de conformité au fil du temps. L’architecture définit où s’exécutent les systèmes. Les défaillances de gouvernance apparaissent généralement lors des changements de routine, pas lors de la conception initiale.
3. Les équipes réglementées peuvent-elles éviter entièrement les outils d’infrastructure bas niveau ?
Non. Les outils bas niveau restent nécessaires pour l’exécution. Le problème est d’exposer ces outils directement à chaque demandeur. La gouvernance s’améliore lorsque l’intention est capturée à un niveau supérieur et appliquée de manière cohérente avant l’exécution.
4. Le libre-service est-il compatible avec une gouvernance stricte ?
Oui, lorsque le libre-service est contraint et appliqué plutôt que revu manuellement. Les demandes doivent être évaluées par rapport à la politique avant que les changements soient appliqués, quel que soit l’environnement.


