TLDR
- L’ingénierie de plateforme ne vise plus à réduire le volume de tickets Jira, mais à créer des contrats stables et réutilisables. Une IDP réussie sépare le « comment » de l’infrastructure du « quoi » de la livraison, permettant aux développeurs de déployer sans maîtriser la complexité cloud sous-jacente.
- La plupart des plateformes échouent soit en construisant des portails ignorés, soit en créant des abstractions « boîte noire » qui rendent le débogage impossible. Les meilleures stacks 2026 équilibrent l’échafaudage de services et une visibilité d’exécution approfondie, garantissant que la plateforme est un outil de rapidité plutôt qu’un obstacle au dépannage.
- Avec près de 90 % de parts de marché, Backstage est incontestablement la « porte d’entrée » du secteur, mais reste un framework et non un produit clé en main. Son adoption nécessite des effectifs dédiés pour gérer des écosystèmes de plugins fragiles et des changements majeurs fréquents qui peuvent bloquer la progression interne pendant des semaines.
- Choisissez votre plateforme en fonction de votre principal point de blocage : utilisez Cycloid ou Humanitec si le provisionnement d’infrastructure et la gestion d’état sont vos problèmes. Optez pour Port, Cortex ou OpsLevel si votre objectif est de cartographier la prolifération des microservices et d’appliquer des tableaux de bord de maturité opérationnelle.
- Pour les puristes cloud-native, des outils comme Kratix et Upbound transforment Kubernetes en orchestrateur universel pour toutes les ressources. Cette approche « Infrastructure-as-Code-as-API » offre le plus haut potentiel de personnalisation, mais exige une équipe de plateforme disposant d’une expertise approfondie au niveau des contrôleurs.
- Les IDP SaaS offrent une valeur immédiate en déchargeant la gestion des bases de données et le verrouillage d’état sur les fournisseurs. Les solutions auto-hébergées offrent une totale souveraineté des données, mais héritent d’une charge permanente de maintenance, de mises à niveau et de reprise après sinistre que beaucoup d’équipes sous-estiment.
L’état des plateformes développeur internes en 2026
Les équipes de plateforme déploient des IDP pour réduire la charge cognitive, pas le volume de tickets. L’objectif est de permettre aux ingénieurs de déployer sans avoir besoin de comprendre les verrous d’état Terraform, les contrôleurs d’admission Kubernetes ou le chaînage des rôles IAM AWS.
D’ici 2026, 80 % des grandes organisations de développement logiciel auront mis en place des équipes d’ingénierie de plateforme pour fournir des services, composants et outils réutilisables via des plateformes de livraison d’applications, selon Gartner. En 2025 seulement, plus de 55 % des organisations ont déjà adopté l’ingénierie de plateforme. Il ne s’agit pas d’une tendance à suivre. C’est une nécessité absolue.
La plupart des IDP échouent parce qu’elles résolvent le mauvais problème — elles construisent des portails que les ingénieurs ignorent, ou elles abstraient tellement que le débogage devient une véritable archéologie. Cette comparaison se concentre sur la façon dont chaque plateforme gère trois aspects : l’échafaudage de services, le provisionnement d’infrastructure et la visibilité d’exécution. Nous évaluerons 11 plateformes sur le modèle de déploiement, l’extensibilité, le coût opérationnel et les points de blocage, sur la base de la documentation et de références de production.
Ce que fait une plateforme développeur interne
Une IDP se situe entre vos ingénieurs et votre infrastructure. Elle modélise les workflows courants, applique des garde-fous et expose des actions en libre-service sans nécessiter d’expertise en infrastructure.
La plateforme ne remplace pas Kubernetes, Terraform ou votre pipeline CI/CD. Elle les enveloppe dans un contrat que les ingénieurs peuvent utiliser sans lire 400 pages de documentation AWS. Une IDP fonctionnelle comporte trois couches : un catalogue de services (que puis-je déployer), un moteur d’orchestration (comment est-ce déployé) et une surface d’intégration (où cela s’exécute). La plupart des produits ne résolvent bien qu’une seule de ces couches.
Pourquoi la plupart des comparatifs d’IDP sont inutiles
Les matrices de fonctionnalités comptent les intégrations, pas les capacités réelles ; elles listent « support GitOps » sans expliquer si cela signifie une prise en charge native d’ArgoCD ou un webhook qui déclenche un script bash.
Les vraies différences apparaissent sous la charge. La plateforme peut-elle gérer 50 équipes déployant 200 services sur 12 comptes AWS ? Est-ce qu’elle casse quand quelqu’un a besoin d’une extension Postgres non standard ? Cet article évalue les plateformes sur le modèle de déploiement, les points d’extension, le coût opérationnel et les points de blocage.
Critères d’évaluation pour cette comparaison
Six dimensions séparent les plateformes fonctionnelles des solutions vaporeuses. Voici comment cette comparaison mesure chacune d’elles.
Architecture et modèle de déploiement
Les plateformes auto-hébergées exigent une infrastructure que vous maintenez indéfiniment. Les plateformes SaaS externalisent cette charge mais vous enferment dans leur rythme de mises à jour. Les modèles hybrides trouvent un compromis, généralement avec un plan de contrôle géré et des workers auto-hébergés.
]
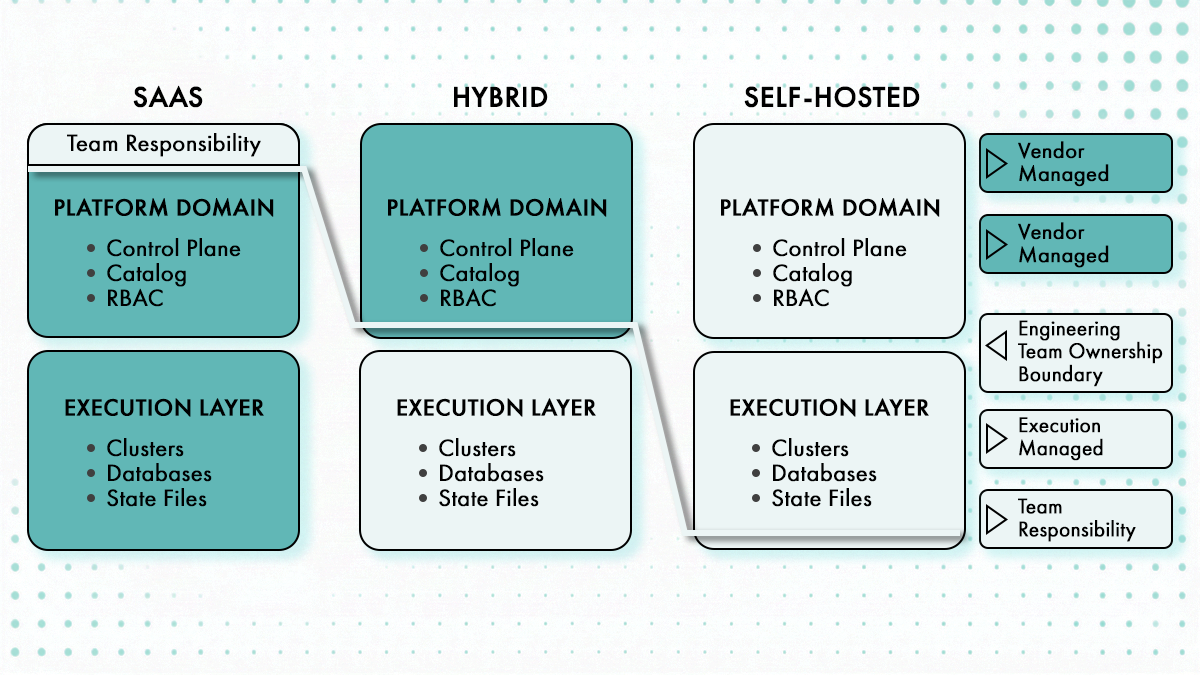
Le modèle de déploiement détermine la charge opérationnelle avant même d’écrire une seule ligne de configuration. Backstage nécessite PostgreSQL (non hébergé sur le même serveur que l’application Backstage, le port PostgreSQL doit être accessible, par défaut 5432 ou 5433), des volumes persistants pour l’état, et une plateforme d’orchestration de conteneurs. Les déploiements en production nécessitent PostgreSQL, l’authentification via GitHub App, RBAC et un hébergement Kubernetes. SQLite et l’authentification invité sont réservés aux démonstrations.
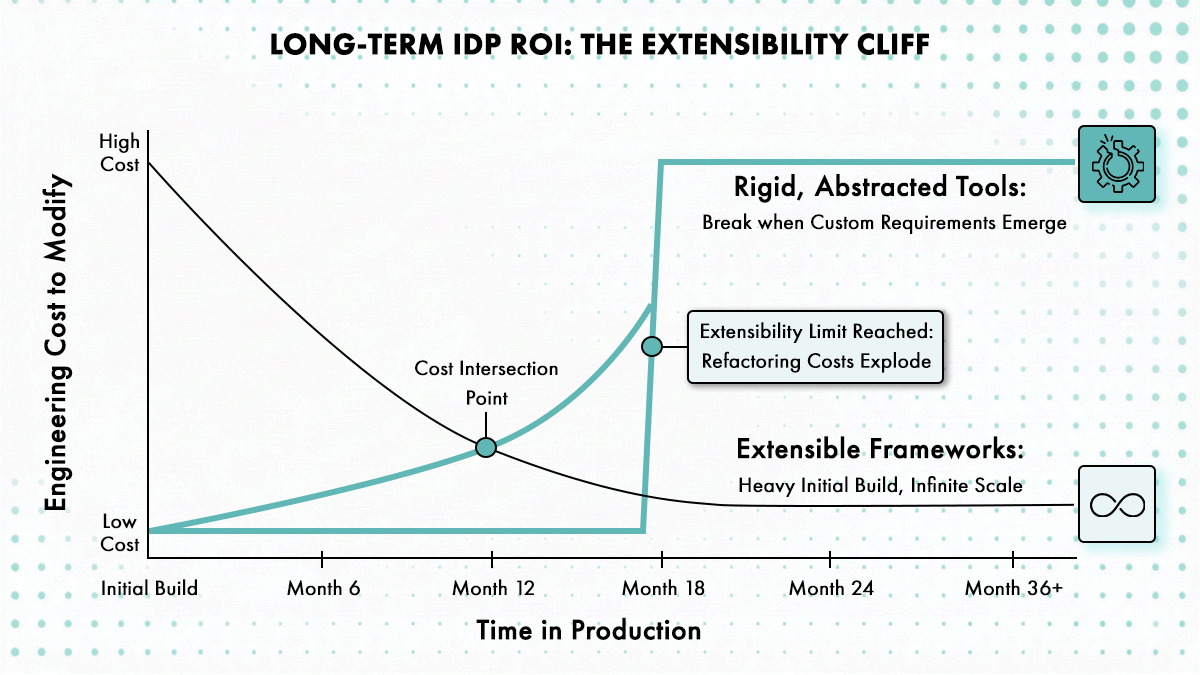
Extensibilité et personnalisation
Pouvez-vous ajouter des workflows personnalisés sans forker le code source ? Quel est le modèle de plugin ? Les ingénieurs non-plateforme peuvent-ils contribuer des templates ? L’extensibilité détermine si vous utiliserez encore cette plateforme dans 18 mois ou si vous la réécrirez de zéro.
Le modèle de plugin de Backstage est le plus mature, mais aussi le plus fragile. Les changements majeurs dans les exports alpha ou bêta doivent entraîner au minimum une montée de version mineure et peuvent être effectués sans période de dépréciation. Le système backend promu en version 1.0.0 signifie que l’API est désormais stable et que les changements majeurs ne devraient pas survenir avant la version 2.0.0, mais cette stabilité ne s’applique qu’au framework de base.
La plupart des plateformes revendiquent l’extensibilité mais entendent en réalité « vous pouvez écrire du code qui appelle nos APIs ». La vraie extensibilité signifie que les ingénieurs non-plateforme peuvent contribuer des templates, des politiques ou des workflows sans comprendre les rouages internes de la plateforme. StackForms dans Cycloid y parvient en limitant les entrées à ce que les équipes sont autorisées à modifier, tout en fixant tout le reste au niveau de la plateforme. Le modèle blueprint de Port vous permet de définir des types d’entités et des relations personnalisés sans écrire du Go ou du TypeScript.
Provisionnement d’infrastructure
Gère-t-elle l’état Terraform ? Effectue-t-elle la détection de dérive ? Peut-elle provisionner des ressources multi-cloud ou est-elle uniquement Kubernetes ? La plupart des « outils d’ingénierie de plateforme » ne sont en réalité que des tableaux de bord Kubernetes déguisés.
La gestion de l’état Terraform est le minimum requis pour les IDP axées sur l’infrastructure. Le verrouillage d’état prévient les modifications concurrentes. L’historique d’état permet de revenir en arrière en cas de problème. Les backends distants (S3, GCS, Terraform Cloud) permettent la collaboration en équipe, mais introduisent leur propre complexité opérationnelle.
La détection de dérive distingue les plateformes qui gèrent l’infrastructure de celles qui se contentent de la déployer. Terraform plan interroge votre fournisseur cloud pour obtenir l’état réel de toutes les ressources gérées et le compare avec le fichier d’état. La dérive Terraform apparaît lorsqu’il y a un écart entre la façon dont Terraform comprend l’état d’une ressource (basé sur le fichier d’état) et la façon dont cette ressource existe réellement.
Expérience développeur
Support CLI, qualité de l’API, et si l’interface est réellement utilisée ou finit par prendre la poussière. La meilleure plateforme du monde ne vaut rien si les ingénieurs la contournent.
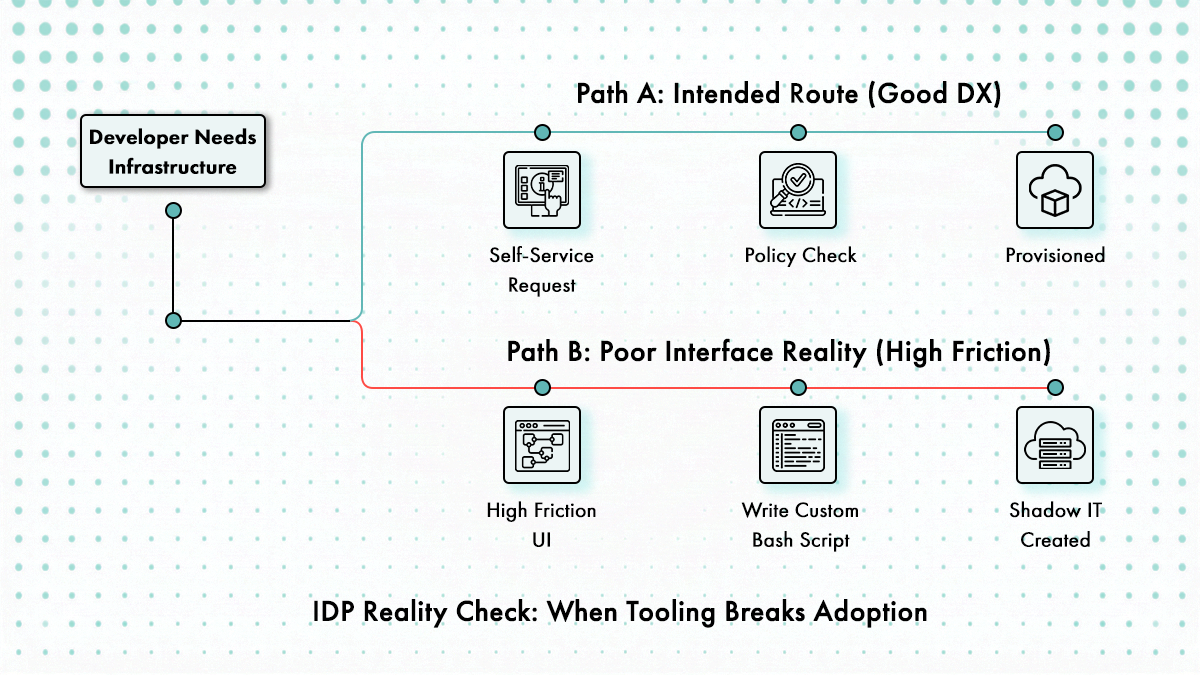
L’expérience développeur détermine l’adoption, et l’adoption détermine le retour sur investissement. Les plateformes avec des interfaces maladroites sont contournées. Les ingénieurs passeront 20 minutes à écrire un script bash pour éviter 5 minutes de clics dans un portail qu’ils n’apprécient pas. Le CLI doit avoir la parité de fonctionnalités avec l’interface. Les plateformes API-first (Port, Cycloid) permettent aux ingénieurs de tout scripter, ce qui maintient l’engagement des utilisateurs avancés au lieu de générer des tickets Jira demandant des fonctionnalités que l’interface n’expose pas.
Charge opérationnelle
Charge de maintenance, fréquence des mises à niveau et quantité de gestion de crise héritée par l’équipe de plateforme. Chaque plateforme promet de réduire la corvée. La plupart ne font que la déplacer des équipes applicatives vers les équipes de plateforme. Les plateformes auto-hébergées génèrent un coût opérationnel continu qui n’apparaît jamais dans les comparatifs des fournisseurs. N’utilisez pas SQLite en production, elle ne supporte pas les écritures concurrentes. PostgreSQL est incontournable pour tout déploiement au-delà d’une démo mono-utilisateur. Vous gérez des bases de données, des clusters Kubernetes, la rotation des secrets, les renouvellements de certificats et la reprise après sinistre.
Les plateformes SaaS éliminent la maintenance d’infrastructure mais introduisent une charge différente. Vous maintenez des intégrations, pas des serveurs. Les jobs de synchronisation de données se cassent quand les APIs changent. Les limites de débit sont atteintes lors des opérations par lots. Le SLA du fournisseur devient votre SLA, et vous ne pouvez pas résoudre leur panne à 2h du matin.
Écosystème et maturité
Taille de la communauté, références de production, et si le fournisseur existera dans deux ans. L’open-source ne garantit pas la survie, et le propriétaire ne garantit pas le support. En janvier 2026, Backstage est utilisé par plus de 3 400 organisations et sert plus de 2 millions de développeurs en dehors de Spotify, commandant 89 % de parts de marché parmi les frameworks de portail développeur interne. Cette adoption crée un écosystème auto-renforçant. Les plugins sont maintenus parce que des entreprises ont des ingénieurs dédiés à Backstage. Les bugs sont corrigés parce que suffisamment de personnes les rencontrent pour que les issues GitHub ne soient pas ignorées.
La viabilité du fournisseur est importante pour les plateformes propriétaires. Les petits fournisseurs avec un nombre limité de clients peuvent proposer d’excellents produits, mais si ils sont rachetés ou ferment, votre plateforme devient un investissement perdu. Vérifiez le financement, le modèle de revenus et si le produit est une activité principale ou une acquisition en cours d’abandon.
Les 11 meilleures plateformes développeur internes en 2026
Voici ce que fait réellement chaque plateforme, où elle s’intègre et ce que vous sacrifiez en la choisissant.
1. Cycloid
Présentation
Cycloid est une plateforme développeur interne qui combine orchestration d’infrastructure, gouvernance et visibilité des coûts en un seul système. Elle utilise un concept appelé « Stacks » pour regrouper infrastructure, pipelines CI/CD et workflows opérationnels en unités réutilisables. Les développeurs interagissent avec ces stacks via des formulaires en libre-service, qui déclenchent des déploiements sans exposer la complexité sous-jacente.
Cycloid s’intègre avec Terraform, Kubernetes et les fournisseurs cloud tout en maintenant le contrôle via l’application de politiques. Elle inclut l’estimation des coûts et des métriques de durabilité, permettant aux équipes d’évaluer l’impact de l’infrastructure avant le déploiement. La plateforme se concentre sur la réduction des workflows basés sur les tickets en donnant aux développeurs un accès contrôlé à l’infrastructure. Elle est conçue pour les organisations qui souhaitent standardiser les déploiements tout en maintenant gouvernance et visibilité.
Modèle de déploiement
SaaS avec des workers optionnels on-premise pour les environnements sensibles. Le plan de contrôle est géré ; l’exécution s’effectue dans votre infrastructure.
Points forts
Traite l’infrastructure comme une préoccupation de premier ordre, pas comme un aspect secondaire. Gestion de l’état Terraform intégrée, suivi des coûts par environnement et application des politiques avant les déploiements. StackForms de Cycloid est un portail en libre-service qui fait le lien entre vos workloads, garantissant que vos services fonctionnent de bout en bout. Il fournit une estimation des coûts avant le déploiement, offrant aux utilisateurs une visibilité sur l’impact financier de leurs choix d’infrastructure.
L’abstraction StackForms permet aux ingénieurs non-plateforme de demander de l’infrastructure sans écrire du HCL. Chaque environnement agit comme un « mini-locataire cloud » au sein du projet, offrant aux MSPs un contrôle total sur la conformité, les accès et la facturation. Les StackForms sont des définitions de stack YAML-first soutenues par Terraform, et non de simples modules Terraform ou formulaires UI. Les entrées sont limitées à ce que les équipes sont autorisées à modifier. Tout le reste est fixé au niveau de la plateforme.
InfraView fournit une représentation visuelle des infrastructures déployées sur les différents environnements de votre projet et inspecte les informations d’état Terraform pour chaque instance. Vous obtenez des diagrammes d’infrastructure générés automatiquement à partir de l’état en direct, et non des pages wiki obsolètes mises à jour il y a six mois. Cycloid est construite avec une architecture automation-first, utilisant vos plans et fichiers d’état existants pour gérer l’infrastructure.
Points faibles
Écosystème de plugins plus restreint que Backstage. Si vos workloads sont 100 % Kubernetes-native et que l’IaC ne vous préoccupe pas, la plateforme pourrait être surdimensionnée.
Idéal pour
Les équipes gérant une infrastructure multi-cloud où le contrôle des coûts et la conformité sont aussi importants que la vélocité. Fonctionne bien pour les organisations combinant VMs et conteneurs.
Notes opérationnelles
Faible charge de maintenance car le plan de contrôle est géré. Vous maintenez les workers et les pipelines, pas la plateforme elle-même. Cycloid aide à réduire les tickets répétitifs, parfois jusqu’à 70 % de moins, et accélère le time-to-delivery de plusieurs heures (voire jours) à quelques minutes.
2. Backstage (Spotify)
Présentation
Backstage est un framework de portail développeur open source créé par Spotify qui sert d’interface centrale pour les services, la documentation et les workflows d’ingénierie. Il ne provisionne pas d’infrastructure ni n’applique de standards de déploiement par lui-même ; il agrège plutôt des systèmes existants tels que les pipelines CI, les clusters Kubernetes et les outils de monitoring dans une interface unifiée. Les équipes définissent des templates logiciels qui standardisent la création de nouveaux services, incluant la structure des dépôts, la configuration CI et les hooks de déploiement.
Son architecture basée sur des plugins permet l’intégration avec des outils internes, mais nécessite également une maintenance continue pour maintenir ces intégrations fonctionnelles. Backstage est souvent utilisé comme la « porte d’entrée » d’une plateforme développeur interne, tandis que le provisionnement réel et l’application des politiques s’effectuent dans d’autres systèmes. Il fonctionne mieux dans les organisations disposant déjà d’une infrastructure mature et souhaitant améliorer la découvrabilité et la cohérence entre les équipes.
Modèle de déploiement
Auto-hébergé ; nécessite un runtime Node.js, PostgreSQL et un stockage persistant. La plupart des organisations le déploient sur Kubernetes.
Points forts
Plus grand écosystème de plugins. En janvier 2026, Backstage est utilisé par plus de 3 400 organisations et sert plus de 2 millions de développeurs en dehors de Spotify, commandant 89 % de parts de marché parmi les frameworks de portail développeur interne. Si vous devez intégrer un outil interne, quelqu’un a probablement déjà écrit un plugin.
Le catalogue de services est véritablement utile pour gérer la prolifération des microservices. Les adoptants couvrent des tailles et secteurs variés, notamment American Airlines, Expedia, LinkedIn, HP, Booking.com, Siemens, Vodafone, LEGO, Mercedes-Benz, Zalando, IKEA, Wayfair, Splunk, Epic Games, Unity, PagerDuty, Twilio, CVS Health, et bien d’autres. American Airlines a construit « Runway » sur Backstage à partir de mai 2020, permettant aux équipes de déployer des applications avec ingress public en moins de 6 minutes.
Points faibles
Ne provisionne pas d’infrastructure par lui-même. Vous assemblez des plugins pour Terraform, ArgoCD et tout ce dont vous avez besoin. Les mises à niveau cassent constamment les plugins car l’API de base évolue encore.
56 % des adoptants de Backstage citent les mises à niveau comme leur principal point de douleur. Les changements majeurs dans les APIs de plugins signifient que la mise à niveau de Backstage nécessite souvent de refactoriser l’ensemble de l’écosystème de plugins. Les taux d’adoption interne tournent autour de 10 % en moyenne, fréquemment parce que les équipes épuisent leur capacité en maintenance avant de livrer les fonctionnalités que les développeurs souhaitent réellement utiliser.
Idéal pour
Les équipes qui souhaitent contrôler chaque intégration et disposent d’ingénieurs pour la maintenir. Pas une solution clé en main.
Notes opérationnelles
Prévoyez de consacrer 1 à 2 ETP rien que pour maintenir Backstage en fonctionnement et les plugins à jour. Le modèle de plugin est puissant mais fragile. L’équipe de plateforme d’un client a passé six semaines sur une seule mise à niveau de version majeure.
3. Port
Présentation
Port est une plateforme de portail développeur axée sur la création d’un catalogue de services personnalisable et de workflows en libre-service. Elle permet aux équipes de modéliser des entités telles que les services, environnements et ressources sous forme d’objets structurés avec des relations définies. Ces entités sont alimentées par des données provenant de systèmes existants comme Kubernetes, les pipelines CI et les fournisseurs cloud.
Port fournit une interface permettant aux développeurs de déclencher des actions telles que la création d’environnements ou le déploiement de services, appuyées par des scripts d’automatisation ou des pipelines. Elle ne remplace pas les outils d’infrastructure, mais agit comme une couche de contrôle qui les connecte dans une interface cohérente. La plateforme met l’accent sur la flexibilité, permettant aux équipes de définir leur propre modèle de données plutôt que d’adopter un schéma fixe. Cela la rend adaptée aux organisations qui souhaitent un portail sans s’engager dans un modèle d’infrastructure spécifique.
Modèle de déploiement
SaaS. Aucune option d’auto-hébergement.
Points forts
Excellente visibilité et découverte. Les blueprints sont les blocs de construction fondamentaux du portail développeur interne. Ils contiennent le schéma des entités que vous souhaitez représenter dans le catalogue de services. Le modèle d’entités facilite la réponse à des questions telles que « quels services dépendent de cette base de données ? » ou « montrez-moi toutes les ressources de production dans AWS us-east-1 ».
Les relations sont les connexions entre les blueprints, capturant les dépendances entre eux. Elles peuvent être simples (ex. : une version de package à un package) ou multiples (ex. : les packages utilisés par un service), et permettent de représenter le catalogue de services comme une base de données graphe dynamique. Port est particulièrement performant pour comprendre le rayon d’impact et l’analyse d’impact.
Points faibles
Le provisionnement est secondaire. Vous pouvez déclencher des workflows, mais la plateforme ne gère pas l’état ni ne réconcilie la dérive. C’est un plan de contrôle, pas un moteur d’exécution.
Idéal pour
Les équipes disposant déjà de workflows de provisionnement solides et ayant besoin d’un meilleur catalogue de services et d’un suivi des dépendances.
Notes opérationnelles
Minimales, car c’est un SaaS. Vous maintenez des intégrations et des jobs de synchronisation de données, pas d’infrastructure.
4. Humanitec
Présentation
Humanitec est une couche d’orchestration de plateforme qui sépare la configuration des applications du provisionnement d’infrastructure. Les développeurs définissent ce dont leur application a besoin, comme une base de données ou une file de messages, sans spécifier comment elle est provisionnée. La plateforme utilise un modèle de définition de ressources pour mapper ces besoins à des composants d’infrastructure réels à travers les environnements. Cela permet des déploiements cohérents entre développement, préproduction et production sans dupliquer la configuration.
Humanitec s’intègre avec Kubernetes et les pipelines CI, agissant comme un plan de contrôle plutôt que de les remplacer. Elle réduit le besoin pour les développeurs d’interagir directement avec Terraform ou les APIs cloud. Le système est conçu pour prévenir la dérive de configuration en appliquant centralement des mappings spécifiques aux environnements.
Modèle de déploiement
SaaS avec des composants opérateur s’exécutant dans vos clusters.
Points forts
La spécification Score est propre et le concept de graphe de ressources fonctionne bien pour les environnements de prévisualisation et le scaling dynamique. Workflows Kubernetes-native solides.
Points faibles
Enfermé dans leur modèle d’abstraction. Si vous avez besoin d’une infrastructure qui ne s’adapte pas au graphe de ressources (VMs legacy, bare metal, etc.), vous devez écrire des drivers personnalisés. Support Terraform limité par rapport aux plateformes IaC dédiées.
Idéal pour
Les organisations cloud-native qui exécutent tout sur Kubernetes, souhaitent des workflows opinionnés et peuvent vivre avec les compromis d’abstraction.
Notes opérationnelles
Charge inférieure à Backstage, supérieure aux plateformes entièrement gérées. Vous maintenez les opérateurs et les définitions de ressources.
5. Kratix (Syntasso)
Présentation
Kratix est un framework de plateforme basé sur Kubernetes qui définit les capacités de plateforme comme des ressources personnalisées, appelées Promises, que les développeurs peuvent demander sans gérer l’infrastructure sous-jacente. Une Promise représente un service tel qu’une base de données, une file d’attente ou un runtime d’application, ainsi que les workflows nécessaires à son provisionnement et sa configuration. Les équipes de plateforme définissent ces Promises une fois, incluant validation, logique de provisionnement et contraintes de politique, et les développeurs les consomment de manière déclarative.
Kratix s’exécute entièrement dans Kubernetes et utilise des contrôleurs pour réconcilier les ressources demandées en infrastructure ou services réels. Il sépare l’interface que les développeurs utilisent de l’implémentation que les équipes de plateforme gèrent, ce qui maintient la cohérence des workflows entre les environnements. Le système est conçu pour les équipes qui veulent que Kubernetes serve de plan de contrôle pour leur plateforme développeur interne.
Modèle de déploiement
Auto-hébergé. S’exécute entièrement dans Kubernetes en utilisant des CRDs et des opérateurs.
Points forts
Séparation claire entre les définitions de plateforme et les demandes des développeurs, réduisant la logique d’infrastructure répétée. Le modèle Kubernetes natif s’adapte bien aux équipes déjà orientées cluster. Les Promises permettent la standardisation des services sans exposer les détails d’implémentation. Fonctionne bien avec les patterns GitOps et de réconciliation par contrôleurs.
Points faibles
Vous construisez l’IDP, vous ne l’achetez pas. Kratix est un framework, pas un produit. Attendez-vous à écrire beaucoup de YAML et de contrôleurs personnalisés.
Idéal pour
Les équipes de plateforme avec une expertise approfondie en Kubernetes qui souhaitent un contrôle total et n’ont pas peur de construire elles-mêmes les couches d’abstraction.
Notes opérationnelles
Élevée. Vous maintenez le framework, les promises et toute la logique d’intégration. C’est du DIY avec un meilleur échafaudage.
6. Cortex
Présentation
Cortex est un portail développeur axé sur la propriété des services, la maturité opérationnelle et les standards d’ingénierie plutôt que sur le provisionnement d’infrastructure. Il ingère des métadonnées provenant des dépôts, des systèmes CI, des outils d’incident et des plateformes d’observabilité pour construire un catalogue de services en temps réel. Les équipes peuvent définir des scorecards qui appliquent des exigences telles que la couverture de tests, les runbooks, les rotations d’astreinte et les vérifications de sécurité.
Cortex ne déploie pas d’applications ni ne gère directement l’infrastructure ; il fournit plutôt de la visibilité et de la gouvernance sur les systèmes existants. La plateforme aide les responsables d’ingénierie à suivre la santé des services et à appliquer les bonnes pratiques sans bloquer les workflows des développeurs. Elle s’intègre avec des outils comme Datadog, PagerDuty et GitHub pour refléter l’état réel des services plutôt que de s’appuyer sur des mises à jour manuelles. Elle est souvent utilisée aux côtés d’autres composants IDP qui gèrent le provisionnement et le déploiement.
Modèle de déploiement
SaaS.
Points forts
Scorecards de première classe. Vous pouvez définir des critères de maturité des services (a un runbook, a une rotation d’astreinte, passe le scan de sécurité) et suivre la conformité entre les équipes. Bonne visibilité organisationnelle.
Points faibles
Ce n’est pas une plateforme de provisionnement. Vous pouvez suivre les services et mesurer leur santé, mais Cortex ne les déploiera pas pour vous.
Idéal pour
Les grandes organisations avec une prolifération de services qui ont besoin de standardisation et de visibilité avant de s’attaquer au provisionnement en libre-service.
Notes opérationnelles
Minimales. Plateforme SaaS avec des intégrations à maintenir.
7. Qovery
Présentation
Qovery est une couche de plateforme qui abstrait Kubernetes et l’infrastructure cloud en un système de déploiement orienté développeurs. Les développeurs définissent des applications, bases de données et environnements via un modèle de configuration simplifié, tandis que Qovery gère le provisionnement, la mise en réseau et le scaling en coulisses. Elle mappe des définitions de services de haut niveau à des ressources Kubernetes sans que les équipes aient besoin d’écrire des manifests ou de gérer directement des clusters.
La plateforme s’intègre avec les workflows Git, où les commits déclenchent des builds et des déploiements entre environnements. Elle supporte les composants courants tels que les bases de données gérées, les jobs en arrière-plan et les environnements de prévisualisation comme entités de premier ordre. Qovery se situe entre un Platform-as-a-Service traditionnel et une plateforme développeur interne personnalisée, offrant aux équipes des environnements structurés sans tout construire de zéro.
Modèle de déploiement
Plateforme SaaS qui provisionne et gère l’infrastructure sur des fournisseurs cloud comme AWS, en utilisant Kubernetes sous le capot.
Points forts
Réduit le besoin de gérer Kubernetes directement, ce qui supprime une charge opérationnelle significative pour les petites équipes de plateforme. Les workflows pilotés par Git s’alignent sur la façon dont les développeurs livrent déjà du code, ce qui facilite l’adoption.
La gestion des environnements est intégrée, ce qui facilite la création d’environnements de staging ou de prévisualisation isolés sans outillage supplémentaire. La plateforme gère les préoccupations d’infrastructure comme le scaling et la mise en réseau sans exposer une configuration de bas niveau.
Points faibles
L’abstraction se fait au détriment du contrôle, ce qui peut être limitant pour les équipes ayant des besoins d’infrastructure complexes. La personnalisation approfondie du comportement Kubernetes ou des ressources cloud est plus difficile par rapport à leur gestion directe. Elle est moins adaptée aux organisations disposant déjà de pratiques d’ingénierie de plateforme matures nécessitant un contrôle fin.
Idéal pour
Les équipes qui souhaitent des déploiements Kubernetes sans gérer la complexité des clusters, notamment les startups ou organisations de taille moyenne construisant leur première couche de plateforme interne.
Notes opérationnelles
Modérée. Bien que Qovery supprime la charge de gestion des clusters, les équipes doivent encore comprendre comment leurs services correspondent à l’infrastructure sous-jacente, notamment pour l’optimisation des performances et le contrôle des coûts.
8. Nullstone
Présentation
Nullstone est une plateforme qui standardise le déploiement d’infrastructure et d’applications en définissant les environnements comme des unités structurées avec des composants préconfigurés. Elle utilise une approche par couches où les équipes de plateforme définissent des blueprints d’environnement, incluant réseau, calcul et dépendances, et les développeurs déploient des services dans ces environnements. Sous le capot, elle s’appuie sur Terraform pour le provisionnement d’infrastructure et s’intègre avec les pipelines CI/CD pour la livraison des applications.
Nullstone organise les services, environnements et infrastructure dans un modèle cohérent, ce qui réduit la dérive de configuration entre les étapes. Les développeurs interagissent avec la plateforme via une interface simplifiée, tandis que l’infrastructure sous-jacente reste contrôlée par des templates prédéfinis. L’accent est mis sur des environnements reproductibles plutôt que sur l’exposition de contrôles d’infrastructure bruts.
Modèle de déploiement
Plateforme SaaS avec provisionnement basé sur Terraform et intégration dans les systèmes CI/CD existants.
Points forts
Forte standardisation des environnements, réduisant les incohérences entre staging et production. L’intégration Terraform permet la réutilisation des modules d’infrastructure existants. Séparation claire entre l’infrastructure gérée par la plateforme et les services gérés par les développeurs. Simplifie l’onboarding des équipes qui déploient dans des environnements préexistants.
Points faibles
Fortement lié à Terraform, ce qui limite la flexibilité pour les workflows non-IaC. Moins adapté aux setups d’infrastructure très dynamiques ou personnalisés. L’abstraction peut masquer des détails que les équipes de plateforme pourraient encore avoir besoin de déboguer.
Idéal pour
Les équipes de petite à moyenne taille déployant des patterns d’applications standard qui ne souhaitent pas devenir des experts cloud.
Notes opérationnelles
Faible. Plateforme SaaS ; vous maintenez les définitions d’applications et les configurations de modules.
9. OpsLevel
Présentation
OpsLevel est un catalogue de services et une plateforme de maturité opérationnelle axée sur la définition et l’application de standards d’ingénierie. Elle suit les services, la propriété, les dépendances et les signaux opérationnels tels que les incidents et les déploiements. Les équipes peuvent définir des vérifications qui imposent des exigences comme la documentation, le monitoring et la préparation aux incidents.
OpsLevel s’intègre avec des outils comme GitHub, Datadog et PagerDuty pour refléter l’état des services en temps réel. Elle ne provisionne pas d’infrastructure ni ne déploie des applications ; elle s’assure plutôt que les services respectent les standards définis. La plateforme est utilisée par les responsables d’ingénierie pour maintenir la cohérence entre les équipes sans introduire de lourdes surcharges de processus. Elle complète d’autres composants IDP qui gèrent le provisionnement et le déploiement.
Modèle de déploiement
SaaS.
Points forts
Excellent pour la propriété des services et la responsabilisation. S’intègre avec PagerDuty, Jira et les outils CI/CD pour bâtir une image complète de la santé des services et des responsabilités des équipes.
Points faibles
Pas un outil de provisionnement. Il s’agit de suivre et d’améliorer ce que vous avez déjà déployé, pas de déployer de nouveaux services.
Idéal pour
Les organisations avec des architectures microservices matures où la propriété et les standards opérationnels doivent être appliqués.
Notes opérationnelles
Minimales. Configuration des intégrations et curation continue des métadonnées.
10. Mia-Platform

Présentation
Mia-Platform est une plateforme développeur interne axée sur la création et la gestion d’architectures microservices avec des templates prédéfinis et des contrôles de gouvernance. Elle fournit un portail développeur où les équipes peuvent créer des services en utilisant des templates standardisés incluant la configuration d’exécution, les pipelines CI/CD et les règles de déploiement. La plateforme s’intègre avec Kubernetes et les API gateways, permettant aux équipes de gérer l’exposition des services, le routage et les dépendances de manière structurée.
Elle inclut également des fonctionnalités de gouvernance telles que la gestion du cycle de vie des services et l’application des politiques. Mia-Platform met l’accent sur la cohérence entre les microservices, garantissant que les nouveaux services suivent les mêmes patterns que les services existants. Elle agit à la fois comme portail développeur et comme couche d’orchestration pour les systèmes basés sur les microservices.
Modèle de déploiement
SaaS ou auto-hébergé, généralement déployé sur Kubernetes avec des intégrations dans les systèmes CI/CD et de gestion des APIs.
Points forts
Fort accent sur la standardisation et la gouvernance des microservices. Les templates réduisent la duplication dans la création et les workflows de déploiement des services. La gestion intégrée des APIs simplifie l’exposition et le routage des services. Supporte à la fois le libre-service des développeurs et le contrôle au niveau de la plateforme.
Points faibles
Principalement conçu pour les architectures microservices, moins adapté aux systèmes plus simples ou non orientés services. Nécessite un alignement avec sa structure opinionnée, qui peut ne pas convenir à toutes les équipes. Peut introduire une surcharge pour les petites équipes avec peu de services.
Idéal pour
Les projets greenfield ou les équipes prêtes à adopter entièrement les opinions architecturales de Mia.
Notes opérationnelles
Moyen (auto-hébergé) à faible (SaaS). Plus de maintenance si vous gérez la stack complète vous-même.
11. Upbound
Présentation
Upbound est une plateforme de plan de contrôle construite sur Crossplane qui permet aux équipes de gérer l’infrastructure cloud en utilisant des APIs Kubernetes. Elle étend Kubernetes en permettant à des ressources d’infrastructure telles que les bases de données, les réseaux et le stockage d’être définies et gérées comme des ressources personnalisées. Les équipes de plateforme définissent des compositions qui mappent des abstractions de haut niveau à des ressources de fournisseurs cloud, tandis que les développeurs interagissent avec des APIs simplifiées.
Upbound fournit un plan de contrôle géré qui gère le provisionnement, les mises à jour et la gestion du cycle de vie de l’infrastructure entre les clouds. Il permet aux workflows d’infrastructure et d’application d’être unifiés sous le même modèle basé sur Kubernetes. Le système se concentre sur le traitement de l’infrastructure comme faisant partie du plan de contrôle plutôt que comme une configuration externe.
Modèle de déploiement
Plan de contrôle SaaS avec des agents s’exécutant dans des clusters Kubernetes, ou auto-hébergé en utilisant Crossplane.
Points forts
Unifie la gestion de l’infrastructure et des applications sous les APIs Kubernetes. Supporte les environnements multi-cloud avec des abstractions cohérentes. Les compositions permettent des patterns d’infrastructure réutilisables entre les équipes. Fort alignement avec les workflows GitOps et déclaratifs.
Points faibles
Nécessite une compréhension approfondie des concepts Kubernetes et Crossplane. Le débogage des problèmes d’infrastructure via des ressources personnalisées peut être complexe. Pas idéal pour les équipes sans maturité Kubernetes.
Idéal pour
Les équipes cloud-native qui souhaitent une infrastructure-as-Kubernetes-resources et sont prêtes à investir dans l’expertise Crossplane.
Notes opérationnelles
Moyen. Les plans de contrôle gérés réduisent la charge, mais vous écrivez et maintenez encore des compositions et des configurations de fournisseurs.
Comment choisir la bonne IDP pour votre organisation
Commencez par votre modèle de provisionnement, pas par votre liste de souhaits. Si vous êtes Terraform-first, privilégiez les plateformes qui traitent l’IaC comme une capacité fondamentale (Cycloid, Resourcely).
Si vous êtes Kubernetes-native, regardez du côté de Kratix, Humanitec ou Upbound. Ensuite, évaluez le coût opérationnel. Votre équipe peut-elle maintenir une plateforme auto-hébergée, ou avez-vous besoin d’un SaaS ? Backstage vous offre le contrôle mais exige des ETP. Port et Cortex vous donnent de la visibilité avec une charge minimale.
Enfin, vérifiez l’extensibilité : cette plateforme grandira-t-elle avec vos besoins, ou en serez-vous à l’étroit dans 18 mois ? Les plateformes open source (Backstage, Kratix) ont un potentiel infini mais un coût élevé. Les plateformes SaaS ont des plafonds plus bas mais un time-to-value plus rapide. Il n’y a pas de gagnant universel. La bonne plateforme dépend de votre stack, de la taille de votre équipe et de là où vous en êtes dans la maturité de votre plateforme.
Conclusion
Cette comparaison a couvert 11 plateformes développeur internes de qualité production, évaluées sur l’architecture, l’extensibilité, les capacités de provisionnement et la charge opérationnelle. Chaque plateforme fait des compromis différents entre contrôle et commodité, flexibilité open-source et simplicité SaaS, workflows Kubernetes-native et gestion d’infrastructure multi-cloud. Les plateformes développeur internes réussissent quand elles suppriment les frictions sans supprimer le contrôle.
Si vous gérez une infrastructure multi-cloud et que les coûts et la conformité vous importent autant que la vélocité, le modèle IaC-first de Cycloid avec FinOps intégré est adapté. Si vous avez besoin d’un catalogue de services et de la flexibilité des plugins, Backstage reste le standard. Si vous êtes Kubernetes-native et souhaitez une infrastructure-as-code via les APIs K8s, Upbound livre. Choisissez la plateforme qui s’aligne sur la façon dont votre équipe travaille déjà, pas celle qui a la liste de fonctionnalités la plus longue. La meilleure IDP est celle que les ingénieurs utilisent réellement.
Foire Aux Questions
1. Ai-je besoin d’une IDP si j’ai déjà des pipelines CI/CD ?
Le CI/CD déploie du code ; une IDP provisionne l’infrastructure, gère les environnements et expose des workflows en libre-service. Ils résolvent des problèmes adjacents. La plupart des équipes ont besoin des deux.
2. Puis-je construire une IDP plutôt que d’en acheter une ?
Oui, mais attendez-vous à un minimum de 2 à 4 ETP pour la construire et la maintenir. La plupart des équipes sous-estiment le coût opérationnel des plateformes maison. La maintenance augmente plus vite que les fonctionnalités.
3. Backstage est-il prêt pour la production en 2026 ?
Oui, mais avec des nuances. L’écosystème de plugins est mature, mais la stabilité de l’API de base évolue encore. Budgétez du temps d’ingénierie pour la maintenance des plugins et les mises à niveau de versions.
4. Quelle est la différence entre une IDP et un PaaS ?
Un PaaS (Heroku, Render) est opinonné et géré. Une IDP est un framework pour construire du libre-service sur votre propre infrastructure. Vous contrôlez les abstractions.
5. Combien de temps prend l’adoption d’une IDP ?
6 à 18 mois selon la taille de l’organisation et l’outillage existant. La plupart des équipes sous-estiment la gestion du changement ; l’intégration technique est plus rapide que de convaincre les ingénieurs de l’utiliser.


